Lesson 3: SQL Server Replication Types
This lesson describes the three types of replication provided by SQL Server: snapshot, transactional, and merge replication. The characteristics of the three types are suited to different application and distributed data needs. Although the replication process is based on the Publisher/Subscriber metaphor for each type, they each use the replication agents and server resources differently.
A replication type applies to a single publication. It is possible to use multiple types of replication within the same database. The processes that implement the replication types are called agents. Agents are discussed at the end of this lesson.
After this lesson, you will be able to:
- Explain the SQL Server replication types
Estimated lesson time: 35 minutes
Snapshot Replication
Snapshot replication is the periodic bulk transfer of an entire publication to Subscribers. It is the easiest type of replication to set up and maintain. Figure 7.6 illustrates snapshot replication. In this figure and many of the figures that follow, the replication agents are illustrated as a circle enclosing two curved arrows.
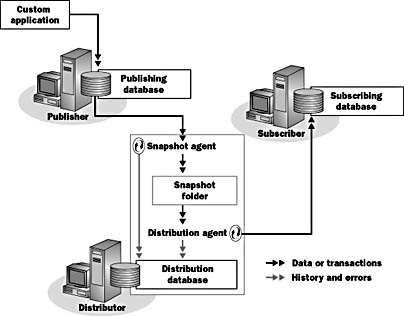
Figure 7.6 Snapshot replication
The characteristics of snapshot replication are as follows:
- It has a high degree of latency because data is refreshed only periodically.
- It has a high degree of site autonomy.
- Replicated tables do not require primary keys.
- It is not suitable for very large publications.
- It has low processor overhead because there is no continuous monitoring.
- It provides efficiency for publications with very volatile data that might be updated multiple times between updates.
The Snapshot Replication Process
In snapshot replication, the Snapshot Agent reads the publication database and creates snapshot files in the distribution working folder (the Snapshot folder) on the Distributor. SQL Server stores status information in the distribution database but does not store data.
The Distribution Agent, running on the Distributor for push subscriptions and on the Subscriber for pull subscriptions, applies snapshots of data from the distribution working folder to the Subscriber.
Transactional Replication
In transactional replication, incremental changes at the Publisher are replicated to the Subscriber. Figure 7.7 illustrates transactional replication.
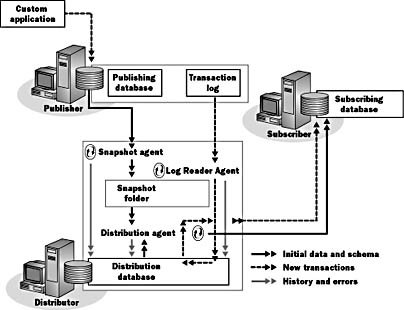
Figure 7.7 Transactional replication
Characteristics of transactional replication include the following:
- Replication typically takes place with minimal latency (seconds).
- It has a lower degree of site autonomy, especially if low latency is required.
- Replicated tables require primary keys.
- It is suitable for any size publication.
- It involves continuous monitoring of transactions (insertions, updates, and deletions) in tables that are marked for replication.
- Only committed transactions are replicated to Subscribers, and they are guaranteed to be applied in the same order as they occurred on the Publisher.
NOTE
You cannot create transactional publications on the Desktop Edition of SQL Server. You can subscribe to transactional publications from another server, and you can create and subscribe to snapshot and merge publications using the Desktop Edition.
The Transactional Replication Process
The transactional replication process shown in Figure 7.7 is as follows: Transactional replication starts with a snapshot replication. The Distribution Agent uses the files that are copied by the Snapshot Agent to set up transactional replication on the Subscriber.
Transactional replication then uses the Log Reader Agent to periodically read the transaction log on the Publisher and store the information in the distribution database. The Distribution Agent, running on the Distributor for push subscriptions and on the Subscriber for pull subscriptions, applies changes to Subscribers.
The Immediate Updating Subscribers Option
Both snapshot and transactional replication require that replicated data not be modified on the Subscribers. This is because data flows in one direction, from the Publisher to the Subscribers. Modifications made on a Subscriber will never be reflected on the Publisher or on the other Subscribers.
In environments that require data to be updated at many sites, you can partition tables so that different partitions of the same table can be published by different sites. Each site is then the Publisher for part of the replicated table and a Subscriber to the other portions of the table.
SQL Server 7 also introduces a new way of allowing data to be updated at Subscribers, called the immediate updating Subscribers option. This option combines transactional or snapshot replication with the two-phase commit protocol managed by MS DTC. Data can be modified on Subscribers as long as the modifications can be applied to the Publisher at the same time, using the two-phase commit protocol.
Figure 7.8 shows how changes made at the Subscriber are applied simultaneously on the Publisher using MSDTC. The rest of the replication process is the same as snapshot or transactional replication.
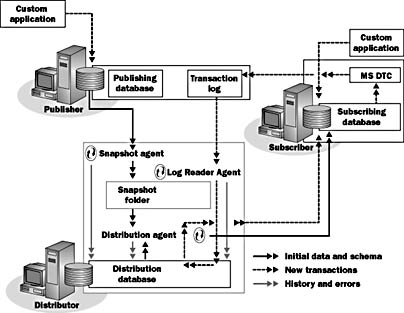
Figure 7.8 Replication under the immediate updating Subscribers option
Note that this option enables an update on the Subscriber to immediately update the Publisher only. The other Subscribers receive the update by regular replication. An update made on the Publisher is not immediately applied to a Subscriber—that would no longer be replication; instead, it would be a distributed transaction.
Using this option requires a well-connected, reliable network between the Publisher and the Subscriber.
Because the modification is made on both the Publisher and the Subscriber,
- The user connected to the Subscriber can continue working without interruption, because the change does not need to be replicated from the Publisher
- The change is guaranteed to be replicated to all other Subscribers
If you use this option with snapshot replication, you will need to partition the published data. This is because an immediate updating Subscriber cannot modify rows that have changed on the Publisher until those rows have been replicated to the Subscriber. The update on the Subscriber fails if the row being modified is different on the Publisher and the Subscriber. This situation will occur if the data has been changed directly on the Publisher or if another immediate updating Subscriber has changed the row. This is less likely to happen if you are using transactional replication, because changes are replicated almost immediately. With snapshot replication, changes are not replicated often, so you will have to partition the data to ensure that two Subscribers or a Subscriber and the Publisher do not both update the same data.
Merge Replication
Merge replication allows sites to make autonomous changes to replicated data. Later, changes from all sites are merged, either periodically or on demand. An automatic, customizable mechanism is used to resolve conflicts that occur when changes are merged. The merge replication process is illustrated in Figure 7.9.
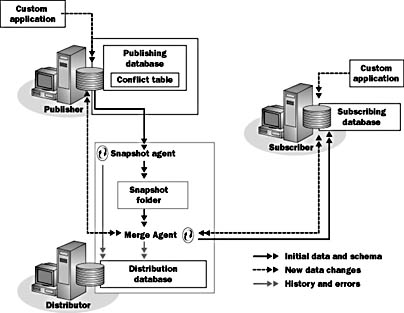
Figure 7.9 Merge replication
Characteristics of merge replication include the following:
- Its latency can be high or low.
- It has a high degree of site autonomy.
- Replicated tables have a unique identifier column to guarantee row uniqueness across all copies.
- It is suitable for any size publication.
- Triggers in the tables published for merge replication mark rows that are changed so that they can be replicated.
- It does not guarantee transactional consistency, but it does guarantee that all sites converge to the same result set.
- It does not support vertical filtering.
Merge replication can be useful for data that is filtered or partitioned according to your business practices, such as data that is structured so that sales representatives can update only the records of customers in their own territories. It is particularly suited to "self-partitioning" applications in which conflicts are not expected.
The Merge Replication Process
As shown in Figure 7.9, merge replication starts with a snapshot replication. The Merge Agent uses the files that are copied by the Snapshot Agent to set up merge replication on the Subscriber.
For a push subscription, the Merge Agent runs on the Distributor. For a pull subscription, the Merge Agent runs on the Subscriber. In merge replication, SQL Server stores status information on the distribution database, but it does not store data.
The Merge Agent applies changes from the Publisher to the Subscribers. It then applies changes from all Subscribers to the Publisher and resolves any update conflicts.
Considerations for Using Merge Replication
Merge replication makes changes to the schema to prevent or resolve conflicts.
Changes to the Schema
For merge replication to work, SQL Server makes three important changes to the schema of the published database:
- It identifies a unique column for each row in the table being replicated. This column must use the unique identifier data type and have the ROWGUIDCOL property. If there is no such column, one will be added. This feature allows the row to be uniquely identified across multiple copies of the table.
- It adds several system tables to support data tracking, efficient synchronization, and conflict detection, resolution, and reporting.
- It creates triggers on tables at the Publisher and Subscriber that track changes to the data in each row or, optionally, each column. These triggers capture changes that are made to the table and record these changes in merge system tables.
Because SQL Server supports multiple triggers of the same type on the base table, merge replication triggers do not interfere with the application-defined triggers; that is, application-defined and merge replication triggers can coexist.
Conflict Resolution
Because merge replication allows independent updates, conflicts can occur. These are addressed by using priority-based conflict resolution:
- The Merge Agent tracks every update to a row.
- The Merge Agent evaluates both the arriving and current data values, and any conflicts between new and old values are automatically resolved based on assigned priorities.
- All sites ultimately end up with the same data values but not necessarily the ones they would have arrived at had all updates been made at one site.
The history of changes to a row is known as the lineage of the row. When the Merge Agent is merging changes and encounters a row that might have multiple changes, it examines the lineage to determine whether a conflict exists. Conflict detection can be at the row or column level.
NOTE
SQL Server supports stored procedure or COM-based custom conflict resolvers.
SQL Server Replication Agents
SQL Server has several agents that implement the various types of replication. Each agent is a separate process that is usually run by SQL Server Agent. Publications and subscriptions have named agents associated with them. A named agent is really a SQL Agent job that configures one of the replication agents to process the data for a specific publication or subscription. Replication agent jobs have a category of REPL-<agentname>.
The Snapshot Agent
The publication and subscription data must be synchronized before replication is possible. The Snapshot Agent is used for initial synchronization of all types of publications and for ongoing replication of snapshot publications. This agent prepares schema and data from publications and stores these in files on the Distributor.
The Snapshot Agent runs on the Distributor and moves data from the Publisher to the Distributor.
The Distribution Agent
The Distribution Agent applies snapshot and transaction replication data from the Distributor to Subscribers for snapshot and transactional publications. For push subscriptions, it runs on the Distributor; for pull subscriptions, it runs on the Subscribers. The Distribution Agent is not used in merge replication.
The Log Reader Agent
The Log Reader Agent copies transactions that are marked for replication from the transaction log on the Publisher to the distribution database.
The Log Reader Agent runs on the Distributor and moves data from the Publisher to the Distributor.
The Merge Agent
The Merge Agent merges data changes from multiple sites that have taken place since the initial snapshot was created. It moves data in both directions between Publishers and Subscribers. The Merge Agent runs on the Distributor for push subscriptions and on the Subscriber for pull subscriptions. It is not used for snapshot or transactional replication.
NOTE
Custom Subscriber applications can be developed based on the Distribution Agent or the Merge Agent, using the SQL Distribution Control and the SQL Merge Control. These are ActiveX controls supplied with SQL Server 7.
Lesson Summary
Three types of replication are provided by SQL Server: snapshot, transactional, and merge replication. SQL Server uses four programs called agents to implement replication: the Snapshot Agent, the Distribution Agent, the Log Reader Agent, and the Merge Agent. The replication process is based on the Publisher/Subscriber metaphor for each type, but each type uses the replication agents and server resources differently.
Snapshot replication is suited to data that does not change regularly. Replication occurs infrequently, and a large amount of data is replicated when replication occurs. Data can be changed only at the Publisher.
Transactional replication is suited to data that changes regularly. Replication can occur frequently, and a relatively small amount of data is replicated when replication occurs. Unless transactional replication is used in conjunction with distributed transactions, data can be changed only on the Publisher.
Merge replication is suited to data that changes regularly. Replication can occur frequently, and a relatively small amount of data is replicated when replication occurs. Data can be changed at the Publisher or at the Subscribers. A conflict resolution mechanism resolves conflicting changes made at more than one server.
EAN: 2147483647
Pages: 114