4.2 Enterprise JavaBeans
|
| < Day Day Up > |
|
4.2 Enterprise JavaBeans
In this section we provide a brief overview of EJBs so that we can better understand the methodology of the performance tuning of a WebSphere Application Server and DB2 integrated system and how WebSphere applications interact with DB2.
4.2.1 EJB overview
Enterprise JavaBeans (EJB) is a server-side component architecture for the development and deployment of component-based distributed business applications.
The EJB component model simplifies development of business components that are transactional, scalable, and portable. Enterprise JavaBean servers reduce the complexity of developing business components by providing automatic support for system-level services, such as transactions, security, and database connectivity, thus allowing the developers to concentrate on developing the business logic.
The EJB specification defines a standard, so that different vendors are able to implement these standards. Because this standard defines every essential detail of the architecture, an application written using the Enterprise JavaBeans architecture is scalable, transactional, and multi-user secure. Such an application may be written once, and then deployed on any server platform that supports the Enterprise JavaBeans specification.
Figure 4-1 on page 78gives an overview for a basic EJB environment:
-
The EJB components are running inside the container of an EJB server.
-
The container has the connection to the database or to other components.
-
An EJB client can access the EJBs from the same Java Virtual Machine (JVM) or from another JVM over remote interfaces. The EJB home component is comparable to a factory for the EJB objects. The EJB objects retrieved from the home components can be also local or remote objects.
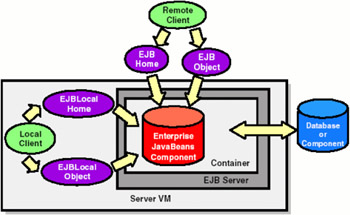
Figure 4-1: EJB environment
EJB 2.0 overview
In this section we have a short look at the new and changed functions in EJB 2.0.
Local interfaces
An EJB client never directly interacts with an EJB object. The client uses the component interface, which defines the methods that are available to the client. The implementation of this interface is provided by the container.
Without having the new local interfaces, the container has to provide only one implementation of this component interface—an implementation for invocations over a network protocol, because the EJB client has to be a remote client. If the EJB client and the EJB object itself are in the same Java Virtual Machine (JVM), an avoidable overhead arises because of the communication layers.
To avoid this overhead, one type of component interface is being added to the EJB specification 2.0: The local component interface.
There are now two types of component interfaces: A local and a remote interface. We can now choose the type that suits our needs.
Container-managed persistence (CMP)
An EJB container and an EJB have to interact with each other. In the case of an CMP entity bean, this interaction is quite complex. This communication is called a contract.
The EJB specification 2.0 establishes new contracts for CMP. These new contracts are fundamentals for the new functionality and they support more efficient vendor implementations.
The new contracts themselves are transparent to an EJB programmer. From a programmer's point of view, there are only some changes in the implementations. One change that may catch the attention of a programmer is that the bean class is now an abstract class without fields. The getters and setters of the bean class describe the attributes of the bean. It is then the job of the container to generate a concrete class for this bean and to implement the fields and the relationships between entity beans.
The two new primary CMP functions are relationships and EJB QL.
Container-managed relationships (CMR)
The main principles of CMR and CMP are comparable. In CMP, we describe our container-managed fields and the container is responsible for persistence. In CMR, we describe the relations between our entity beans and the container is responsible for maintaining the referential integrity.
What a container does in different situations is clearly described in the specification. For example, if we create a one-to-many relationship between bean A and bean B and invoke a set method on instance A2 passing the instance B1, the container has to remove the previous relationship between A1 and B1 because of the 1:n relationship definition. B1 can only belong to one instance of bean A. The container has to remove the prior relationship in the same transaction context to maintain the referential integrity.
The descriptions of the relationships are based on the abstract persistence schema. The abstract schema and the description of the relationships are part of the deployment descriptor.
The members of a container-managed relationship must have a local interface. The container-managed relationships support one-to-many (1:m), one-to-one (1:1), and many-to-many (m:m) relationships.
EJB query language
The finder methods in the home interfaces are responsible for locating particular entity objects, but the name and the declaration of the methods are not sufficient information for the container to generate an implementation of the finder method.
Therefore, the bean provider has to provide a description of the finder method. The EJB Architecture Version 1.1 does not specify the format of the finder method description. So every vendor (that is, every container provider) must offer a way to do this.
There are some obvious drawbacks with this approach. Every container provider offers a different way to describe and implement the finder methods, but all the different implementations have a big drawback in common. Since the EJB 1.1 beans have no object schema, they have to implement and describe the finder methods based on the data schema.
The EJB Query Language (EJB QL) enables us to describe the finder methods based on the object schema in an independent manner. Now our finder methods are supported by every EJB 2.0-compliant container. We do not have to customize our finder methods if we are using another database or another EJB container.
The EJB QL uses an SQL-like syntax to select objects or values. It is a typed expression language.
EJB types
There are three types of EJBs: Entity, session, and message-driven beans, as shown in Figure 4-2 on page 83. In this section, we explore their structure, behavior, and container life-cycle relationship in more detail. Additionally, when a particular bean type might be an appropriate choice in the design, an expanded client view is also discussed. Finally, we conclude with an example application scenario that helps us to classify the usage of a particular bean type.
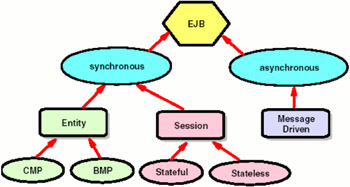
Figure 4-2: EJB types
Session beans
Session beans are often considered to be extensions or agents of the client, and perform tasks on behalf of the client. Only one client may be processing on a given session bean at a given time, so there is no concurrency of session beans. They are modeled to encapsulate process or workflow-like behavior, such as transferring funds between accounts. Although some session beans may maintain state data, this data is not persistent in the sense that an entity bean represents persistent data.
There are two sub-types of session EJBs—stateless session EJBs, and stateful session EJBs as follows:
-
Stateless session EJB
These represent a set of related behaviors (methods) that do not retain client-specific states between invocations. Contrary to popular belief, stateless session beans can, in fact, possess instance variables, but those variables must be shared among multiple potential clients (for example, they should be read-only). This often overlooked fact can be key to understanding some potential uses of stateless session EJBs.
For readers familiar with traditional transaction-processing systems like CICS or Encina®, you can think of each method call to a stateless session EJB as an individual non-conversational transaction.
-
Stateful session EJB
Each stateful session EJB is "owned" by a single client, and is uniquely connected to that client. As a result of this, stateful session EJBs may retain client state across method invocations. That is to say, a client may call a method that sets a variable value in one method, and then be assured that another, later, method invocation to retrieve that value will retrieve the same value.
Entity beans
Entity beans are typically modeled to represent domain objects, that is, data entities that are stored in a permanent, persistent data store such as a database, and the behavior that can be performed on that data. This is sometimes referred to as objectifying the data, and the attributes of the entity object are mapped to rows in one or more database tables. Some examples of entities might be accounts or customers. Each entity is uniquely identified by its primary key. Since data in a database may be shared by multiple users, so may entity beans. Managing the concurrency of the entity bean is one of the responsibilities of the container.
Depending on the way the persistence is managed, there are two kinds of entity beans: Container-managed persistence (CMP) and bean-managed persistence (BMP) beans. Persistence can be defined as the data access protocol for transferring the state of the object between the entity bean and the underlying data source.
-
CMP beans
CMP means that the EJB container handles all database access required by the entity bean. The bean's code contains no database access (SQL) calls. As a result, the bean's code is not tied to a specific persistent storage mechanism (database). This provides independence from the underlying database implementations, and the same entity EJB can be deployed on different J2EE servers that use different databases, without modifying or recompiling the entity EJB code. In other words, your entity beans are more portable.
The EJB 2.0 specification addresses some of the known limitations in EJB 1.1 by providing a common persistence model that CMPs are developed on. This persistent model is intended to transcend the product lines and make it standard for all EJB vendors. Specifically, the specification provides:
-
An abstract persistence schema—This enables CMP mappings to be done in an abstract way for all vendor tools.
-
EJB Q L—A standardized query language for finding and locating beans. Although it is not actually SQL, it is an SQL-like language that supports a subset of SQL functions.
-
Container-managed relationships (CMR)—Standardize how beans are related to other beans, and supports the relationship types of one-to-one, one-to-many, and many-to-many. This is actually included as a part of the abstract persistence schema.
WebSphere Studio Application Developer and VisualAge® for Java have long provided support within the tool set for building schemas and managing relationships of beans. Application Developer Version 5 provides updated tools for the building of beans on this new, abstract model.
-
-
BMP beans
Entity beans that manage their own persistence are called bean-managed persistence (BMP) entity beans.
With a BMP entity bean, the EJB developer manages the persistent state of the bean by coding database calls, or any type of access to permanent storage, directly into the bean class. This puts the responsibility on the developer to properly manage the persistence of the bean. To do so properly requires understanding how callback methods and other bean life-cycle methods are invoked by the container as part of its persistence service, as is done automatically in CMPs, then emulating that behavior yourself in your own bean.
It is the developer's responsibility to save and restore the state of the bean when called by the container through the ejbLoad and ejbStore methods—these are the callback methods for the bean type; and to create, find, and/or remove beans through ejbCreate and ejbRemove methods—these are the life-cycle methods of the bean. Most of the time, the developer of BMPs uses JDBC for coding the persistence logic directly into these methods; however, other techniques can also be used, such as SQLJ or CICS transactions.
Although most of the new features of EJB 2.0 were for CMPs, some of the newer features are available for BMPs as well. Specifically, BMPs also may define new structures of query methods (home and select methods), although developers must code the data source logic themselves. The new EJB query language is not available for BMPs.
Message-driven beans
This EJB type is added in the EJB 2.0 specification. A message-driven bean is an asynchronous message consumer, implemented as a Java Message Service (JMS) consumer. Message-driven beans are similar to session beans. They may also represent business process-like behavior, but are invoked asynchronously.
They typically represent integration points for other applications that need to work with the EJB.
Access intent
When using CMP EJBs, the SQL and the interface to the database are usually transparent to the programmer. However, there are ways of controlling the database lock isolation level of the CMP auto-generated SQL.
-
EJB 1.1 module
The database lock isolation level is indirectly selected based on the isolation level defined for the transaction attributes in the EJB deployment descriptor. This can be set at the method level by the development tool when you build the .ear file. This capability has been removed from the EJB 2.0 module. WebSphere Application Server Version 5.0 is compliant with the EJB 2.0 specification; therefore you cannot specify the isolation level on the EJB method level or bean level.
-
EJB 2.0 module
The isolation level and read-only method level modifiers that could be defined for EJB1.1 are now part of the access intent mechanism of WebSphere. Isolation levels were specific to JDBC, but because the persistence mechanism is now based on J2C resources, a more abstract mechanism was needed. If the underlying resource is a JDBC resource, then the access intent hints will still be translated to JDBC isolation levels under the covers. If the resource is not a relational database, then the access intent will be translated to the mechanism appropriate to that resource.
An access intent policy is a named set of properties (access intents) that governs data access for EJB persistence. You can assign a policy to individual methods on an entity bean's home, remote, or local interfaces during assembly. Access intents are available only within EJB 2.x-compliant modules for entity beans with CMP 2.x and for BMPs.
Access intent enables developers to configure applications so that the EJB container and its agents can make performance optimizations for entity bean access. Entity bean methods are configured with access intent policies at the module level. A policy is acted upon by either the combination of the WebSphere EJB container and persistence manager (for CMP entities) or by BMP entities directly. Note that access intent policies apply to entity beans only.
The intent of the access intent mechanism in WebSphere Version 5 is to allow developers to supply the container with optimization hints. The container will use these hints to make decisions about isolation levels, cursor managements, and so forth. The hints are organized into groups called policies. The policies are defined at the module level and applied to individual methods on the bean's interface (local or remote).
Concurrency control
Concurrency control is the management of contention for data resources. A concurrency control scheme is considered pessimistic when it locks a given resource early in the data-access transaction and does not release it until the transaction is closed. A concurrency control scheme is considered optimistic when locks are acquired and released over a very short period of time at the end of a transaction.
Read-ahead hints
Read-ahead schemes enable applications to minimize the number of database round trips by retrieving a working set of CMP beans for the transaction within one query. Read-ahead involves activating the requested CMP beans and caching the data of related beans (relationships), which ensures that data is present for the beans that are most likely to be needed next by an application. A read-ahead hint is a canonical representation of the related beans that are to be read. It is associated with a finder method for the requested bean type, which must be an EJB 2.x-compliant CMP entity bean.
Specifying access intent in WebSphere
WebSphere V5 has several predefined access intent policies that are useful combinations of the five available access intent attributes:
-
Access type
-
Collection scope
-
Collection increment
-
Resource adapter prefetch increment
-
Read-ahead hint
The access type hint is relevant for transactions because it has to do with concurrency and update intent. For a more detailed explanation of the access intent policies, please refer to the Application Developer help.
Table 4-1 and Table 4-2 describe the access intent settings, and how they might affect the underlying isolation levels.
| Profile name | Concurrency control | Access type | Transaction isolation |
|---|---|---|---|
| wsPessimisticRead | pessimistic | read | repeatable read |
| wsPessimisticRead | pessimistic | update | repeatable read |
| wsPessimisticUpdate-Exclusive | pessimistic | update | serializable |
| wsPessimisticUpdate-NoCollision | pessimistic | update | read committed |
| wsPessimisticUpdate-WeakestLockAtLoad | pessimistic | update | repeatable read |
| wsOptimisticRead | optimistic | read | read committed |
| wsOptimisticUpdate | optimistic | update | read committed |
| Isolation level in JDBC | Isolation level in DB2 | Abbreviation |
|---|---|---|
| TRANSACTION_SERIALIZABLE | Repeatable read | RR |
| TRANSACTION_REPEATABLE_READ | Read stability | RS |
| TRANSACTION_READ_COMMITTED | Cursor stability | CS |
| TRANSACTION_READ_UNCOMMITTED | Uncommitted read | UR |
Mapping transaction isolation levels to DB2
DB2 accepts a set of isolation levels when you bind an application. The DB2 specification is a little different from the EJB specification, but there is a close match between the two sets.
Pessimistic read
Read locks are held for the duration of the transaction.
Pessimistic update
To assure data integrity, locks will be held during the scope of the transaction under which ejbLoad was invoked. This access type can be further qualified with the following update hints:
-
Exclusive
This is a hint that the normal isolation value used for pessimistic update may not be sufficient.
-
No collision
This hint indicates that the application will have no row collisions by design and a lesser isolation level may be chosen by the runtime. WebSphere can, of course, make no assurances guaranteeing the data integrity; in fact, row collisions do occur when the no collision hint is specified, and concurrent transactions can overwrite each other's updates. Use this policy if only one transaction updates at any given time.
-
Weakest lock
Same as no collision, but with repeatable read isolation level. Deadlocks can occur when the updating of one entity bean by two transactions is attempted. This is the default type that will be used if no type has been explicitly assigned.
Optimistic read
This type is equivalent to pessimistic read, but with a different isolation level.
Optimistic update
Locks will not be acquired during ejbLoad; instead, overqualified updates will be used in order to assure data integrity. For a JDBC resource, an overqualified update will use the WHERE part of the UPDATE statement to compare every field of the record to its old value, as in:
UPDATE Customer SET field1=newvalue1, field2=newvalue2 WHERE field1=oldvalue1 AND field2=oldvalue2
Note that, for records with a large number of fields, this type of comparison can become a rather expensive operation.
So with optimistic update, instead of locking everything, you hope that nobody else will change the data, or only a few columns are changed. This could be the case for your application if changes are highly unlikely and always locking the data would affect scalability. When a conflict does occur, an exception is thrown.
It is important to note that nullable columns are not supported by optimistic concurrency in WebSphere V5. Nullable columns are excluded from overqualified updates so that changes to nullable columns are not detected.
Optimistic concurrency always faces the possibility of getting locked out by another transaction using a stronger locking strategy. However, optimistic concurrency does not suffer from the pessimistic restriction that an entity loaded under read intent cannot be updated.
|
| < Day Day Up > |
|
EAN: N/A
Pages: 90