Complex Scripts
All language versions of Windows 2000 and Windows XP are enabled for all supported languages, thereby empowering applications that use Unicode as their encoding model to handle mixed text from any of the supported scripts. For example, in Notepad you can display text containing English, Farsi, Greek, Hindi, Korean, and Thai text all at once. (See Figure 5-10.) Among these scripts there are several that require special processing to display and edit because the characters are not laid out in a simple linear progression from left to right, as most European characters are. These writing systems are referred to as "complex scripts."

Figure 5-10 - A multilingual document that contains different scripts in the same context.
Characteristics of Complex Scripts
Glossary
- Item: A character string having all the same script and direction attributes.
- Runs: Portions of an item that have continuous formatting attributes.
- Clusters: The sequence of characters or glyphs between points at which the Unicode representation of a string aligns with the glyph representation. For simple text, where each code point is represented by a single glyph, the cluster is the character and its glyph. For simple ligatures, where two or more code points are represented by a single glyph, the cluster is the sequence of code points and the single glyph. The most complex case is when a sequence of code points is represented by a sequence of glyphs with no internal alignment between characters and glyphs. This can occur, for example, in the case of reordering within Indic syllables.
Complex scripts offer significant challenges because of the linguistic traits associated with them. Some of these traits include bidirectionality and character reordering, contextual shaping, characters that combine, and special rules for word breaking, for line breaking, and for text justification.
Bidirectionality and Character Reordering
Arabic scripts (used for languages such as Arabic, Farsi, Pashtu, and Urdu) and Hebrew scripts (used for Hebrew and Yiddish) are not only right-justified, but also are read from right to left (RTL)-in other words, these two scripts have an RTL reading order. For these particular scripts, the logical order (the order in which the user enters text with a sequence of virtual-key inputs) and the visual order (the order in which characters are represented to the user) are different in most cases. (See Figure 5-11.) Character positioning and caret movement in bidirectional context, in which RTL characters and left to right (LTR) characters coexist, are the biggest hurdles to overcome when dealing with RTL scripts. A bidirectional context can be a mixture of Latin and Arabic or Hebrew text; or it can involve Arabic and Hebrew characters with numerals that have an LTR attribute in Arabic and Hebrew. Figure 5-12 shows a challenge that occurs when the trailing edge of one character in bidirectional text is not necessarily adjacent to the leading edge of the next character.

Figure 5-11 - Bidirectional text (Arabic) where the logical order (first row) and the visual order (second row) are not of the same sequence of characters.

Figure 5-12 - In bidirectional text the trailing edge of one character is not necessarily adjacent to the leading edge of the next character. In this example, the text selection follows the logical order.
The Unicode bidirectional algorithm resolves the layout of mixed-direction text in the absence of higher-level protocols. The following are some of the general assumptions this algorithm makes:
- Adjacent runs of words of opposite language direction are laid out according to the base level-left to right for an English paragraph, right to left for an Arabic paragraph.
- Numbers following LTR words should be displayed to the right of the words.
- Numbers following RTL words should be displayed to the left of the words.
- Punctuation between words of the same language direction should be displayed between those words.
- Punctuation between runs of words of opposite language direction appears between those runs.
- Punctuation at the beginning or end of a paragraph is laid out according to the paragraph direction and is not affected by the direction of adjacent text.
- The digits of numbers are laid out left to right in the number.
- Commas and periods are considered part of a number when immediately surrounded by digits. Other characters, such as currency signs, are considered part of a number when immediately adjacent to a digit.
The algorithm makes a valiant and surprisingly successful stab at resolving what can be very ambiguous text. In applications such as databases and forms, this algorithm is often sufficient. In applications such as word processors, it is usually considered necessary to give the user more direct control over bidirectional-text layout. (To learn more about bidirectionality as well as Unicode algorithms and implementation, go to the Unicode site at http://www.unicode.org.)
Contextual Shaping
For the Arabic and Indic family of languages, a character's glyph (that is, all the character's different possible representations) can change greatly depending on the glyph's position within a word and the characters that precede or follow the glyph. In Arabic, the same character can have several different shapes depending on the context. (See Table 5-5.)
Table 5-5 Arabic letter "Ain" (Unicode code point U+0639) in its four different forms.
| Arabic Letter "Ain" | Forms |
| | Isolated form |
| | Initial form (beginning of a word) |
| | Middle form |
| | Final form (end of a word) |




The difficult part of contextual shaping is that, for all the various glyphs, there is only one defined code point in different encoding models. Layout and displaying mechanisms should define (at run time) the appropriate glyph to be used from the font tables, depending on the context.
Combining Characters
For Latin script, there is often a direct one-to-one mapping between a character and its glyph. (For instance, the character "h" is always represented by the same glyph "h.") For complex scripts, several characters can combine together to create a whole new glyph independent of the original characters. There are also cases where the number of resulting glyphs can be bigger than the original number of characters used to generate those glyphs. Characters are often stacked or combined to create a cluster, which is indivisible for most of the complex scripts. In Arabic, on the other hand, a cluster can be divided by breaking a glyph into its composing characters and diacritics. (See Figure 5-13.)
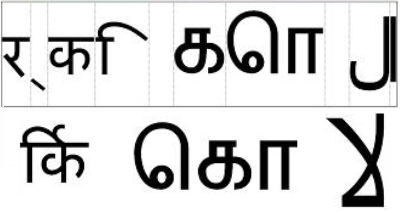
Figure 5-13 - Cluster formatting for (from left to right) Hindi, where four individual characters get resolved to one indivisible cluster of one glyph; Tamil, where two individual characters get resolved to one indivisible cluster of three glyphs; Arabic, where two individual characters get resolved to one divisible cluster of one glyph.
An indivisible cluster is treated as a single entity in UI-bound text handling. When selected or deleted, an indivisible cluster is selected or deleted as one symbol; when a caret is moved over such a cluster, it skips over the cluster in one cursor move. Divisible clusters, on the other hand, allow the user to position a caret within a cluster and to delete characters that were combined in the cluster.
Word Breaking and Line Breaking
Word breaking and line breaking for Latin script follow some straightforward rules, such as breaking a line at a space, tab, or hyphen. For languages like Thai and Khmer, words run together (with no space between characters that end a word and those that begin another word, as with Latin script). This makes word breaking in such languages a more complex process, since syntax rules require line breaking on word boundaries. Thus for languages like Thai and Khmer, word breaking is based on grammatical analysis and on word matching in dictionaries during text processing at run time.
Text Justification
To justify Latin text, spaces are added between words and characters. This approach cannot be used to justify Arabic text or the contextual shaping will break. Instead, continuous lines (or kashidas) are inserted between adjoining characters to make each word look longer. Figure 5-14 shows an example of Arabic text with kashidas inserted for justification purposes.

Figure 5-14 - Arabic text with kashidas (in gray) inserted for justification purposes.
In "Techniques for Handling Input Languages" earlier in this chapter, you saw the range of system support available for handling various input languages. Similarly, Windows 2000 and Windows XP offer considerable support to help you work with the intricacies of complex scripts.
Windows Support for Complex Scripts
Glossary
- Graphics Device Interface (GDI) : In Windows, a graphics display system used by applications to display or print bitmapped text (TrueType fonts), images, and other graphic elements. The GDI is responsible for drawing dialog boxes, buttons, and other elements.
Supported complex scripts in Windows XP are Arabic, Divehi, Hebrew, Syriac, Thai, Vietnamese, and the Indic family of scripts including Bengali, Devanagari, Gujarati, Gurmukhi, Kannada, Oriya, Tamil, and Telugu. The Unicode Script Processor (USP10.dll), also known as "Uniscribe," is the system engine used to shape and lay out complex scripts. It is shipped with Windows 2000 and Windows XP, Microsoft Internet Explorer 4 and later, and with Microsoft Office 2000 and Microsoft Office XP. (For more information on Uniscribe, see "Uniscribe" later in this chapter.)
Although applications can directly interface Uniscribe to render complex scripts, the easiest and most efficient way of supporting complex scripts is through the support that Windows 2000 and Windows XP provide automatically, as discussed in the following section. Each time the system's User or GDI components are called to perform a text output, if support for complex scripts is installed, the text is passed to a language module called "LPK.dll" (a name derived from [L]anguage [P]ac[K]). This module analyzes the text and looks for complex-script portions or runs. If the text does not contain any such runs, it is immediately returned back to the User components or GDI components for processing. If the text does contain complex-script runs, its processing is given to Uniscribe, which sends the final processed text to the User components or GDI components in order to be displayed. (See Figure 5-15.)
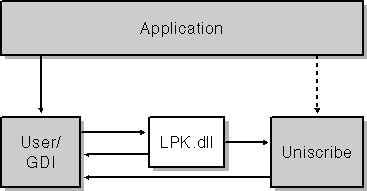
Figure 5-15 - Flowchart of complex-script processing.
As you have discovered, complex scripts often require special processing to display and edit. Luckily, there are additional techniques available to ensure that you overcome the common hurdles you might encounter, as you will see next.
EAN: 2147483647
Pages: 198