Traditional Character Encoding
The mechanism of assigning a code point to a given character-or encoding-has taken various forms before the emergence of Unicode. The following information provides a background on character encoding itself, including single-byte character sets as well as multibyte character sets, both of which preceded Unicode.
Basics of Character Encoding
Glossary
- ASCII: Acronym for American Standard Code for Information Interchange, a 7-bit encoding. Although primitive, ASCII's set of 128 characters is the one common denominator contained in most of the other standard character sets (and in all Windows and OEM code pages).
- Code point or code element: (1) The minimum bit combination that can represent a unit of encoded text for processing or exchange. (2) An index into a code page or a Unicode Standard.
- Character: (1) The smallest components of a writing system or script that have semantic value. A character refers to an abstract idea rather than to a specific glyph or shape that a character might have once rendered or displayed. (2) A code element.
In the past, most computers "spoke" mainly English, with each character represented by a unique numeric value or code point. As shown here, to encode the whole set of characters needed to represent the English language as well as several control characters, a total of 128 distinct code points was needed.
Uppercase (A-Z) 26 Lowercase (a-z) 26 Digits (0-9) 10 Punctuation marks (. , + { ) %) 32 Space 1 Control characters (Tab, CR, LF, and so on) 33 Total 128 In the computer world where numeric values are represented by binary data, representing 128 different configurations requires 7 bits to represent each character (27 = 128). The 7-bit encoding system was then created, which was known as "ASCII." (See Figure 3-1.)
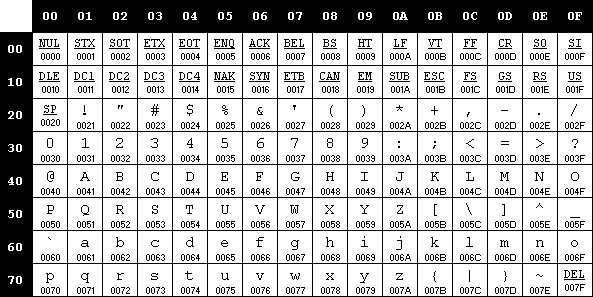
Figure 3.1 - The ASCII code page.
As computers became more widely used and as additional languages had to be accommodated, support for more comprehensive code pages that included different accented characters-an integral part of many languages-had to be added. As a result, support for new encoding systems such as single-byte character sets (SBCSs) and double-byte character sets (DBCSs) was introduced (each of which will be discussed in the sections that follow).
Single-Byte Character Sets
Glossary
- Extended characters: (1) Characters above the ASCII range (32 through 127) in single-byte character sets. (2) Accented characters.
- ANSI: Acronym for the American National Standards Institute. The term "ANSI" as used to signify Windows code pages is a historical reference, but is nowadays a misnomer that continues to persist in the Windows community. The source of this comes from the fact that the Windows code page 1252 was originally based on an ANSI draft-which became International Organization for Standardization (ISO) Standard 8859-1. "ANSI applications" are usually a reference to non-Unicode or code page-based applications.
- Single-byte character set (SBCS): A character encoding in which each character is represented by 1 byte. Single-byte character sets are mathematically limited to 256 characters.
- EBCDIC: Extended Binary Coded Decimal Interchange Code. These types of code pages are used on IBM and other manufacturers' mainframes.
With a quick look at Figure 3-1, you can immediately see that the ASCII encoding system's 128-character limitation prevents representation of most languages other than English-including some Latin-based languages that use accented characters, such as French or German. To overcome this limitation, several companies and standards bodies created new code pages using a whole byte (or 8 bits) to represent each character. In each of these new code pages, the set of characters encoded 32 through 127 (hexadecimal 0x20 through 0x7F) was left intact, forming the original 7-bit set called "ASCII". Meanwhile, the characters numbered 128 through 255 (hexadecimal 0x80 through 0xFF) were called "extended characters" and varied from one code page to another. Similarly, this set of extended characters is unique to a particular combination of languages. Therefore, distinct code pages were created to support several Latin-based Western European languages, as well as Greek, Arabic, Turkic, and other additional languages. (See Figure 3-2.)
Figure 3.2 - Extended characters and code page.
As if things were not complicated enough, different implementations of encoding systems were created for the same set of characters! For example, the Latin script for Western European countries has all the following encoding systems:
- Windows 1252, used primarily in Windows operating systems. (See different Windows encoding tables online at http://www.microsoft.com/globaldev/reference/WinCP.asp.)
- OEM-850, used in MS-DOS. (See different OEM encoding tables online at http://www.microsoft.com/globaldev/reference/oem.asp.)
- ISO 8859-1, ISO standard. (See different ISO encoding tables online at http://www.microsoft.com/globaldev/reference/iso.asp.)
- Several forms of EBCDIC such as EBCDIC-US.
- MacRoman, used by Apple Computer. (See Macintosh encoding tables online at http://www.microsoft.com/globaldev/dis_v1/html/S2589.asp.)
There are a few points to consider when handling SBCS strings of characters. First, recall that extended characters are different from one code page to another. Therefore your application's behavior is seriously jeopardized if it runs on a system that uses a different code page than what your application is expecting. Code points that you intended for representing one script will be presented and processed as a completely different script, thus displaying gibberish and incorrect results. For example, notice how different the extended characters encoded in the range x80-xFF of the Thai code page 874 (see Figure 3-3) are from the same range of characters encoded in the Windows 1252 code page.
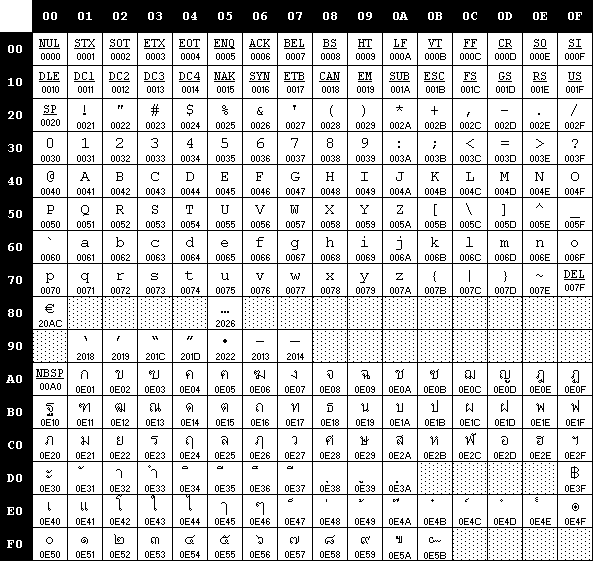
Figure 3.3 - Microsoft Windows 874 code page for Thai.
Second, be aware that certain string manipulation functions may be English-centric. For instance, the string-manipulation code for uppercasing, as shown in the example below, works only for English.
#define ToUpper(ch) ((ch)<='Z' ? (ch) : (ch)+'A' - 'a')
This particular code is English-centric because the assumed relationship between lowercase and uppercase characters is not applicable to accented characters. Also, the meaning of uppercasing is irrelevant for scripts such as Arabic, Hebrew, and East Asian languages because there is no such concept of upper and lowercase in these scripts.
Probably the SBCS's most problematic limitation is its inability to encode East Asian characters and ideographs, since their amount exceeds, by far, the 256 different possible values of an 8-bit encoding. This particular limitation of SBCS encodings has been the prime driving force behind the creation of multibyte character sets.
Multibyte Character Sets
Glossary
- Multibyte character set (MBCS): A character encoding in which the code points can be either 1, 2, or more bytes.
- Double-byte character set (DBCS): A character encoding in which the code points can be either 1 or 2 bytes. Used, for example, to encode Chinese, Japanese, and Korean languages.
- Full-width character: Characters whose glyph image extends across the entire character display cell. In legacy character sets, full-width characters are normally encoded in 2 or more bytes. The Japanese term for full-width characters is "zenkaku."
- Half-width character : Characters whose glyph image occupies half of the character display cell. In legacy character sets, half-width characters are normally encoded in a single byte. The Japanese term for half-width characters is "hankaku."
- Ideographic character: A character of Chinese origin representing a word or a syllable that is generally used in more than one Asian language. Sometimes referred to as a "Chinese character."
- Kana: The set of Japanese hiragana and katakana characters.
- Shift-JIS: The multibyte encoding developed by Microsoft for Japanese that is based on Japan Industry Standard (JIS) standard X 0208. The name comes from the way the lead bytes in Shift-JIS shift around the encoding range of half-width katakana in JIS X 0208.
- Lead byte: The first byte of a 2-byte code point in a DBCS code page.
- Trail byte: The second byte of a 2-byte code point in a DBCS code page.
- Big-5: The multibyte encoding for Traditional Chinese characters standardized by Taiwan.
A multibyte character set expands the range of encoding possibilities for East Asian languages. For instance, the Chinese script is made up of more than 10,000 basic ideographic characters-called "hantsu" or "hanzi" in Chinese. Corresponding ideographic characters are called "kanji" in Japanese and "hanja" in Korean. As you've seen, single-byte encodings are too limited to accommodate these languages. Once you have assigned 256 code points (that is, indexes to the code page), what do you do with the rest of the several thousand characters that Chinese or Japanese readers and writers typically use every day?
A solution commonly used on computers is to encode most characters (primarily ideographs) with 2-byte values, thus making room for far more than 256 characters. The key element in the previous sentence is "most characters"-characters such as those in the ASCII set and the Japanese phonetic syllabary known as "katakana" still have single-byte representations. The result is a code page that mixes single-byte and double-byte characters.
On other operating systems, such as UNIX, characters can be represented by as many as 4 bytes. (See Figure 3-4.) Character sets that mix character codes of 1, 2, and 3 bytes are generally called "multibyte character sets."
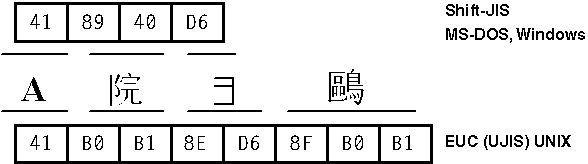
Figure 3.4 - Multibyte character sets.
The mixing of byte lengths in multibyte character sets used in East Asian scripts leads to more complex string-parsing code, where each byte does not necessarily represent a single character. For this reason, you must exercise caution when coding string-parsing routines. Each 2-byte character is composed of a lead byte and a trail byte that must be stored together and manipulated as a unit. A lead-byte value always falls into one or more ranges above 127; no 7-bit ASCII character can be a lead byte. NULL can never be a trail byte but the range of possible trail bytes can overlap to some degree with ASCII. Trail-byte values are frequently indistinguishable from lead-byte values; the only way to tell the difference is from the context of the surrounding characters. Furthermore, most trail bytes taken without their lead byte can be mistaken for a single-byte character. In the previous figure, the kanji character  is represented by the byte pair 0x89-0x40, where 0x89 is the lead byte and 0x40-which is the @ sign by itself-is the trail byte. Figure 3-5, meanwhile, shows how lead bytes from the main page map to an extended table of trail bytes that have the actual encoding for kanji characters.
is represented by the byte pair 0x89-0x40, where 0x89 is the lead byte and 0x40-which is the @ sign by itself-is the trail byte. Figure 3-5, meanwhile, shows how lead bytes from the main page map to an extended table of trail bytes that have the actual encoding for kanji characters.
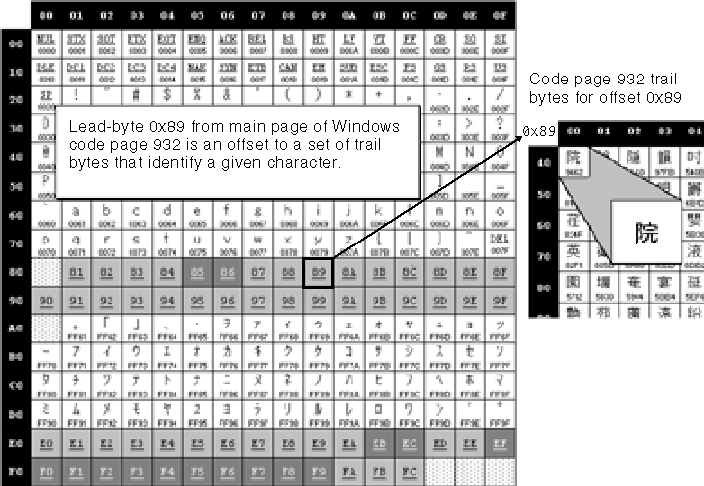
Figure 3.5 - Lead-byte and trail-byte mapping in Windows code page 932.
Special coding techniques specific to DBCSs or MBCSs will not be covered in detail in this book, since the idea of a fully globalized application is to have a Unicode encoding system. However, you'll need to consider the following when dealing with MBCS:
- Always handle one lead byte and its trail byte as a unit. A lead byte or a trail byte alone does not contain enough information to identify a character.
- Lead-byte and trail-byte ranges differ from one DBCS code page to another. (See Table 3-1 for an example involving various East Asian languages.) Instead of hard-coding these ranges, you can use Win32 application program ming interfaces (APIs) such as IsDBCSLeadByteEx or GetCPInfoEx to find out if a given byte can be a lead byte in the target code page.
- Make sure that your string parsing takes into consideration a mixture of SBCS and DBCS. Instead of using pointer incrementals or decrementals, it's suggested you use predefined APIs such as CharPrevExA and CharNextExA to go to the previous or next character.
- Caret positioning and cursor movements are common issues when dealing with MBCS. Not only do coding practices need to be adjusted to avoid splitting double-byte characters in two, but so do a program's display operations. Rules of selection, cursor placement, and cursor movement are the same as you would expect when dealing with alphabetic characters-the cursor should always end up between characters and never in the middle of one. The difference with double-byte characters is that they are a combination of two encoding units.
-
(For more information on MBCS encoding, see the first edition of this book. Or go to http://www.microsoft.com/globaldev/dis_v1/html/S24B2_b1.asp.)
Table 3-1 includes the lead-byte and trail-byte ranges for the code pages corresponding to various East Asian languages.
Table 3-1 Lead-byte and trail-byte ranges for some code pages used with East Asian languages.
| Language | Character Set Name | Code Page | Lead-Byte Ranges | Trail-Byte Ranges |
| Chinese (Simplified) | GB 2312-80 | CP 936 | 0xA1-0xFE | 0xA1-0xFE |
| Chinese (Traditional) | Big-5 | CP 950 | 0x81-0xFE | 0x40-0x7E |
| Japanese | Shift-JIS (Japan Industry Standard) | CP 932 | 0x81-0x9F | 0x40-0xFC |
| Korean (Wansung) | KS C-5601-1987 | CP 949 | 0x81-0xFE | 0x41-0x5A |
Once again, though the current shift is toward utilizing the Unicode encoding system, there is one final consideration should you need to work with code pages. Before developers started using Unicode extensively, Microsoft had a full array of Win32 APIs to make working with code pages easier. (You can find more information about these APIs at http://msdn.microsoft.com.) In fact, in order to deal with non-Unicode-based text strings, Microsoft still supports these APIs, which include the following. (See Table 3-2.)
Table 3-2 Win32 APIs used for working with code pages, before the extensive use of Unicode.
| API | Function |
| AreFileApisANSI | Determines whether the file I/O functions are using the Windows or OEM character-set code page |
| EnumSystemCodePages | Enumerates the system code pages (including OEM, Windows, and EBCDIC) that are either installed or supported, depending on the specified input arguments |
| GetACP | Returns currently selected Windows code page |
| GetConsoleCP | Returns the code-page ID of the current console code page |
| GetConsoleOutputCP | Returns the code-page ID of the current console output code page |
| GetCPInfoEx | Returns a structure containing the maximum width of a character in the specified code page; the lead-byte ranges, if any; and the code page's default character, used in conjunction with WideCharToMultiByte |
| GetOEMCP | Returns currently selected OEM code page |
| GetSystemDefaultLangID | Retrieves the language identifier of the system locale |
| GetSystemDefaultLCID | Retrieves the system default locale identifier |
| IsDBCSLeadByteEx | Determines whether a character is a lead byte in the specified code page |
| IsValidCodePage | Determines whether a code page is installed in the system |
| MultiByteToWideChar | Maps a character string to a wide-character (UTF-16) string; the character string mapped by this function is not necessarily from a multibyte character set |
| SetConsoleCP | Sets the code-page ID of the current console code page |
| SetConsoleOutputCP | Sets the code-page ID of the current console output code page |
| SetFileApisToANSI | Causes the file I/O functions to use the Windows character-set code page |
| SetFileApisToOEM | Causes the file I/O functions to use the OEM character- set code page |
| WideCharToMultiByte | Maps a wide-character (UTF-16) string to a new character string; the new character string is not necessarily from a multibyte character set |
Because of the limitations of SBCS and MBCS, however, and because of the complexity of properly handling MBCS character strings, several leading Information Technology (IT) companies jointly created the Unicode Consortium. (See "Unicode's Capabilities" later in this chapter.) The resulting universal system known as "Unicode" is helping to standardize character encoding and to make multilingual computing a reality. In the sections that follow, you'll see the possibilities that Unicode offers and gain a better understanding of how it works.
EAN: 2147483647
Pages: 198