9.3 A Performance Model
| In order to assess how this new help-desk application performs in a target architecture, a predictive performance model is constructed. Since the workload intensity is specified through arrival rates of the three types of transactions, an open multiclass model is used. The arrival rates are already available from Eq. (9.2.1). The next two sections estimate the number of I/Os and the service demands for each transaction class, respectively. 9.3.1 Estimating the Number of I/OsThe number of I/Os generated by a select statement depends on the type of indexes available for the tables accessed by the select statement. For example, take the Employee table. Assume that a select statement on this table is used to locate an employee with a given Social Security Number (SSN). If there is no index on SSN for this table, the database management system (DBMS) must scan all 21,600 rows of the table until such an employee is found. This is called a table scan, generates many I/Os, and can be quite expensive for large tables. If an index on SSN exists, the row for that employee can be typically located with a small number of I/Os. An index on a database table T is a table with two columns. Each row is of the form (IndexKey, RowPointer), where the IndexKey is either a particular column value found in one or more rows of T or a concatenation of column values in a specified format. A RowPointer (called rowid in Oracle, rid in DB2, and tid in Ingres) uniquely identifies a row in T. Rows are stored in specific slots within database pages. Pages are stored within operating system files One of the most common types of indexes, supported by virtually all commercial DBMSs, is the b-tree index [10, 12]. A b-tree has two types of nodes: index nodes and leaf nodes. Index nodes contain entries of the form (key value, pointer). A pointer points to either another index node or to a leaf node. Leaf nodes do not have any pointers. The number of pointers in an index node is called the fanout of the tree. A b-tree has a constant height (i.e., the number of nodes from the root of the tree to any leaf node is constant). Thus, the number of I/Os needed to locate a leaf node in a b-tree index is equal to the height h of the tree. Since the root of the tree will almost certainly be in the buffer pool, the number of I/Os is h 1. The height of a b-tree with fanout k and L entries is given by Equation 9.3.2 In most cases of practical interest, the height of a b-tree is at most four. Following the approach given in [10], it is possible to compute the fanout of a b-tree index. The format of a page of a b-tree index is [Header, (KeyValue1, RowPointer1), ···, (KeyValuek, RowPointerk), FreeSpace]. The fanout k for a b-tree index is computed as Equation 9.3.3 where
Table 9.3 shows the b-tree indexes assumed for all seven database tables. Tables KeywordQuestion and TicketEmployee have two indexes. The table shows the key size, the fanout computed according to Eq. (9.3.3), and the height of the b-tree computed according to Eq. (9.3.2). The values in the table assume that PageSize = 2048 bytes, HeaderSize = 20 bytes, fi = 0.71, and rp = 4 bytes.
If a table scan is needed, the number of I/Os is equal to the number of data pages, ndpT, needed to store a table T. This number is equal to Equation 9.3.4 where NumRowsT is the cardinality of table T and nrpT is the number of rows of table T that can be stored in a data page. The value of nrpT is computed as indicated in [10]. The layout of a data page is assumed to be: [Header, RowDirectory, FreeSpace, RowN, ..., Row1]. The row directory is a table with as many entries as the number of rows in the page. An entry in this directory contains the byte offset of the row within the page. The slot number of a row in a page is the number of its entry in the row directory. To allow for row size expansion, the free space on a data page is not fully used. A fill factor, fd, is assumed that indicates the percentage of the page's useful space used to store rows. Thus, nrpT can be computed as Equation 9.3.5 where
Eq. (9.3.5) assumes that a data page only stores information about a single table. The number of data pages needed to store each of the relational tables according to Eqs. (9.3.4) and (9.3.5) is shown in Table 9.4 assuming PageSize = 2048 bytes, HeaderSized = 20 bytes, fd = 0.8, and rd = 2 bytes.
The following approximation is used to estimate the number of I/Os due to a select statement:
In the case of an update statement, the number of I/Os is equal to the number of rows updated plus the number of I/Os needed to update any table indexes. The number of I/Os necessary to update an index is assumed to be equal to the height of the b-tree minus 1 for the root being in memory. Tables 9.5 through 9.7 indicate, for each of the three transactions types, the number of I/Os per select or update statement as well as the total number of I/Os for the transaction types. The first column of each table is the statement number in the specification of the transaction (see Figs. 9.6-9.8). The second column indicates the index that is used to perform the access in case of a select. In case of an update, the second column indicates which indexes have to be updated. The third column indicates the number of times, ns, that the statement s is executed. This values can be obtained from the specification of the transaction logic in Clisspe. Consider for example the statement of line 08 in the FAQ transaction of Fig. 9.6. This statement is within two loops. The inner loop is executed #QuestionsPerKeyword (i.e., 20) times and the outer loop is executed #KeywordsPerQuery (i.e., 2) times. Thus, the statement in line 08 is executed 40 (= 20 x 2) times. Column 4 indicates the probability, ps, that the statement s is executed. Consider the statement in line 05 of the create ticket transaction of Fig. 9.7. This statement is executed if the statements in the then clause are executed. This happens with probability #ProbValidEmployee (i.e, 0.9). Column 5 indicates the number, ni, of I/Os on the index of column 2 per execution of statement s. This number is obtained as the height of the b-tree for the specific index minus one (because the root of the tree is assumed to be in memory). For example, consider the statement in line 05 of the FAQ transaction of Fig. 9.6. The select statement in that line is on table KeywordQuestion with a selection criterion based on column KeywordId. According to Table 9.3, this database table has an index on the column KeywordId with height 3. Thus, as indicated in Table 9.5, the number of I/Os on the index is 2 (= 3 1). Column 6 indicates the number, nd, of data page I/Os when statement s is executed. This number is determined based on the number of rows retrieved in each case. Consider again the statement in line 05 of the FAQ transaction of Fig. 9.6. The number of rows of the KeywordQuestion retrieved given a specific keyword id is equal to #QuestionsPerKeyword (i.e., 20). Finally, the last column of the table is the total number of I/Os computed as (ni + nd) x ns x ps.
Note that in Table 9.6 there are two rows for statement number 7, an update statement on table TicketEmployee (see Fig. 9.7). This double entry corresponds to the two indexes (one for the index key (TicketId, EmployeeId) and the other for the index key EmployeeId) that exist for the TicketEmployee database table (see Table 9.3). The update statement of line 07 requires one data I/O as reflected on the first line corresponding to statement 7.
All computations described in this section are shown on the Ch09-Data.XLS MS Excel workbook.
9.3.2 Estimating Service DemandsService demands can be estimated based on the number of I/Os shown in Tables 9.5-9.7. It is assumed that the average disk service time is equal to 8 msec. Measurements are taken at a test server to obtain the average CPU time per I/O. The value obtained in this test experiment is 1.5 msec of CPU time required per I/O. Using these values one can obtain the matrix of service demands for the database server, assuming one CPU and one disk. For example, consider the FAQ transaction. From Table 9.5, each FAQ transaction requires a total 158 I/Os. Each of these I/Os requires 1.5 msec of CPU time and 8 msec of disk time. Thus, the service demand at the CPU for a typical FAQ transaction is 0.237 (= 158 x 0.0015) seconds. The service demand at the disk is 1.264 (= 158 x 0.008) seconds. The results are shown in Table 9.8, which also indicates the arrival rates per class from Eq. (9.2.1).
It can be quickly seen that a configuration with a single disk will not be able to support the new help desk application. The utilization of the disk is Equation 9.3.6 (A similar calculation for the CPU indicates that the CPU utilization is 64%). Since the disk utilization exceeds 100% by more than a factor of 3, additional or faster disks are required by the database server. A balanced configuration with four disks is analyzed by assigning 25% of the service demand to each of four disks. The solution of the model is obtained with the help of the Ch09-OpenQN.XLS MS Excel workbook. The results obtained with the model show that the response times for the three classes are: RFAQ = 9.1 sec, Rticket = 1.8 sec, and Rstatus = 23 sec. The model also shows that the utilization of each disk is 85% (i.e., 340% / 4) and the utilization of the CPU is 64%. The disks are still the bottleneck and are thus responsible for most of the response time. Management finds these response times to be high. In particular, a response time of 23 seconds for the view status of open tickets is considered to be unacceptable. An analysis of the number of I/Os for this transaction type shows that an average of 404.5 I/Os are required (see Table 9.7). An analysis of the transaction logic in Fig. 9.8 shows that the problem is that the TicketEmployee relation keeps all tickets, open and closed, for the past 365 days. From Table 9.2, this generates an average of 80.3 (= 1,734,480/21,600) tickets per employee stored in the Ticket table. However, the vast majority of these tickets are already closed and are of no interest to this transaction. Given these observations, the performance analyst suggests to the system designers that they create a new database table to archive the closed tickets. Then, the Ticket table would contain only open tickets. Given that tickets do not stay open for more than three days on average, this change in the database design and application logic would have a significant performance impact. The following results are obtained by redoing the computations, assuming that tickets are only kept active for three days: 1) the total number of I/Os to create a new ticket goes from 30.9 to 23.7 and 2) the total number of I/Os required to view the status of open tickets goes down from 404.5 to 4.64. The effect of this change in the overall response time is remarkable. The new response times are RFAQ = 3.91 sec, Rticket = 0.6 sec, and Rstatus = 0.11 sec. The results of the new computations for the service demands under the modified database design are shown in the Ch09-Data-Mod.XLS MS Excel workbook. The corresponding results from the open QN model are in Ch09-OpenQN.XLS. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
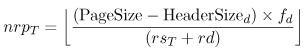
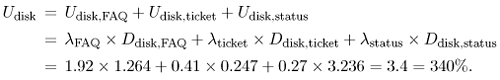
EAN: 2147483647
Pages: 166
- Challenging the Unpredictable: Changeable Order Management Systems
- ERP System Acquisition: A Process Model and Results From an Austrian Survey
- The Second Wave ERP Market: An Australian Viewpoint
- Data Mining for Business Process Reengineering
- Intrinsic and Contextual Data Quality: The Effect of Media and Personal Involvement