9.2 The Help Desk Service
| Consider a large high technology company with 21,600 employees who have access to a large variety of computing resources. A new help desk application is being designed to provide employees with assistance in solving problems related to their computing environments including operating systems, middleware, and applications. Three main functions of the new system have been identified:
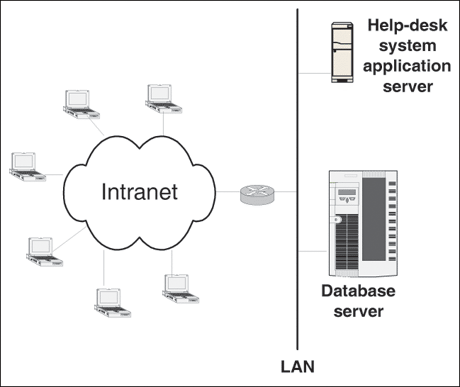
The anticipated architecture of the help desk system is depicted in Fig. 9.3. An application server implements the business logic for the FAQ, help tickets, and tracking system. A database server stores all persistent data. These two servers are connected by a 100-Mbps Ethernet LAN. Employees connect to the application server through the company's Intranet. Management is interested in appropriately sizing the database server, the most critical resource of the system, even before the application is fully developed. Figure 9.3. Help-desk system. 9.2.1 Workload CharacterizationTable 9.1 presents the data used to characterize the workload intensity of the new application. Daily and peak period activity are given for the three types of requests (i.e., FAQ access, ticket creation, and status inquiries). General system activity is also given. The first three sections of the table are related to the three types of requests to be processed by the help desk system.
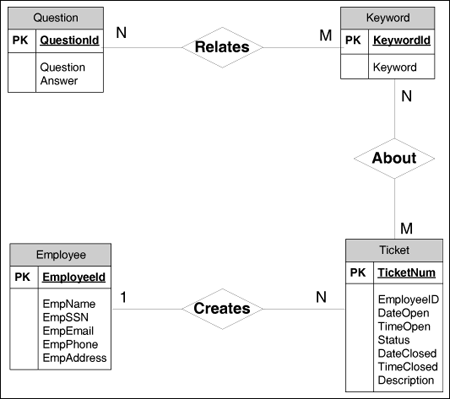
The average arrival rate of requests during the peak period can be computed for each type of request using the data of Table 9.1 as follows. Equation 9.2.1 The arrival rate of new tickets, lticket, has two components: one due to employees that access the FAQ database before generating ticket requests and the other due to employees who bypass the FAQ database. 9.2.2 Database DesignA high level conceptual design of the database that supports the new help desk system is shown in Fig. 9.4 using an Entity-Relationship (E-R) model. The are four entities: Question, Keyword, Employee, and Ticket. The Question entity has three attributes: QuestionId, Question, and Answer. QuestionId is the primary key (PK) attribute (i.e., the attribute that uniquely identifies a question). The Keyword entity has two attributes: KeywordId (the primary key) and Keyword. The Employee entity has six attributes: EmployeeId (the primary key), EmpName, EmpSSN, EmpEmail, EmpPhone, and EmpAddress. The Ticket entity has eight attributes: TicketNum (the primary key), EmployeeId, DateOpen, TimeOpen, Status, DateClosed, TimeClosed, and Description. Figure 9.4. Entity-Relationship model for the database design. As shown in Fig. 9.4, these four entities interact with each other via the following relationships:
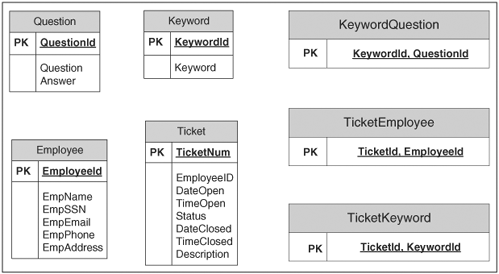
The process of translating an E-R model into a relational database design is well-known [12]. Using this process, the E-R model of Fig. 9.4 is mapped into relational tables as indicated in Fig. 9.5. There are seven relational tables. Tables Question, Keyword, Employee, and Ticket have a direct correspondence to the entities of the same name in the E-R model. Tables KeywordQuestion, TicketEmployee, and TicketKeyword have a direct correspondence to the three relationships (i.e., Relates, About, and Creates). Figure 9.5. Database design for the help-desk system. The database is a major component of the new help desk system. To appropriately size the database server, it is necessary to estimate the cardinality (i.e., the number of rows and row size) of each database table. The cardinality multiplied by the row size gives the total size of each table. The cardinalities of the Question, Keyword, and Employee tables are easy to estimate. The number of questions in the system (i.e., 10,000), the number of keywords (i.e., 500), and the number of employees of the company (i.e., 21,600) come directly from Table 9.1. The cardinality of the Ticket table is equal to the number of tickets generated during a typical year. (Recall that a ticket diary is kept in the database server of the previous year's activities.) Using the data of Table 9.1, the number of tickets created per day is equal to Ne x (fFAQ x tFAQ + ft) = 21600 x (0.2 x 0.35 + 0.15) = 4,752. Therefore, 1,734,480 (= 4,752 x 365) tickets are created during one year. It is assumed that a question is associated with 10 keywords on average. Thus, the cardinality of the KeywordQuestion table has ten times the number of rows as the Question table (i.e., 10 x 10,000 = 100,000 rows). The cardinality of the TicketEmployee table is the same as that of the Ticket table (i.e., 1,734,480 rows). This follows from the one-to-many "Creates" relationship in Fig. 9.4: every ticket corresponds to a single employee. The following additional assumptions are needed to estimate the cardinality of the two remaining tables. It is also assumed that a ticket has an average of 5 keywords associated to it. Thus, the cardinality of the TicketKeyword table is five times that of the Ticket table (i.e., 5 x 1,734,480 = 8,672,400 rows). The row size for each table is estimated based on the type of columns of each database table. For instance, questions are assumed to be within 1,000 aracters and keywords are assumed to be 50 characters long. The row size estimates for all database tables as well as their cardinality is shown in Table 9.2. The last column of this table shows the total size of each table (i.e., the product of the cardinality by the row size).
9.2.3 Transaction LogicA high-level description of the transaction logic (i.e., the software run on the application server and on the database server) is necessary for the purpose of estimating service demands for the new help-desk application. The following description is annotated with enough information to allow for the estimation of service demands at each of the system devices (i.e., CPUs and disks). The basic approach for estimating service demands in an SPE study consists of estimating the number of I/Os per transaction. The CPU service demands are estimated as a function of the number of I/Os. The description of the transaction logic for each of the three transaction types (i.e, FAQs, ticket, and status) is presented here using Clisspe, a language developed for the purpose of specifying systems for SPE studies [10]. The Clisspe language allows designers of client/server systems to describe different kinds of objects such as servers, clients, databases, relational database tables, transactions, and networks, as well as the relationships between them. The language also allows the designer to specify the actions executed by each transaction type. The process of computing service demands for each transaction type at each system device from a Clisspe specification is automated in a compiler for the language [10]. The compiler includes a detailed model of the database management system (including query optimization) and provides estimates on the number of I/Os and CPU time for SQL statements. The transaction logic for a query to the FAQ database is shown in Fig. 9.6. The specification includes two types of Clisspe statements: loop and select. The loop statement indicates the average number of times a loop is executed. The select statement indicates the execution of a select statement on a certain database table. Clisspe allows for complex multi-join select statements. The names of constants are preceded in Clisspe by the "#" sign (e.g., #KeywordsPerQuery). Comments in Clisspe are preceded by the "!" sign. The transaction of Fig. 9.6 loops for a number of times equal to the number of keywords per query. For each keyword x, the corresponding keyword id, id(x), is retrieved using the select statement of line 03. The where clause of a select statement indicates the names of the columns on which a search criteria is based. The select statement of line 05 retrieves question ids (i.e., a total number of #QuestionsPerKeyword) that correspond to the keyword id id(x). For each of them, the actual question is retrieved using the select statement of line 08. Figure 9.6. Transaction logic for query on FAQ database. Similarly, the transaction logic for the creation of a new ticket is shown in Fig. 9.7. Two more Clisspe statements are used in this transaction: if-then and update. The if-then statement indicates a probability that the statements in the then clause are executed. The update statement indicates that an update or insertion is performed on a given table. The number of rows modified or inserted is indicated by the num_rows parameter. For example, line 05 inserts one extra row in the Ticket table. The logic of the creation of a new ticket starts by accessing the Employee table to verify the existence of the customer requesting the ticket. In the affirmative case, 1) a ticket is created in the Ticket table (line 05), 2) one row is added to the TicketEmployee table (line 07), and 3) as many rows are created in the TicketKeyword table as there are keywords associated with the ticket (line 09). Figure 9.7. Transaction logic for creation of a new ticket. Finally, and in a manner similar to the FAQ logic and the ticket logic, the transaction logic for a status inquiry transaction is shown in Fig. 9.8. The select statement in line 02 retrieves all ids of the tickets associated with a given employee. Then, the actual tickets are retrieved from the Ticket table by the select statement of line 05. Note that the where clause of this select statement specifies a selection based on both the TicketId and the Status. Figure 9.8. Transaction logic for viewing the status of open tickets. The values of the various constants used in the specifications of the three types of transactions are assumed to be: #KeywordsPerQuery = 2, #QuestionsPerKeyword = 10,000 / 500 = 20, #ProbValidEmployee = 0.9, #KeywordsPerTicket = 5, and #TicketsPerEmployee = 1,734,480 / 21,600 = 80.3. These constants are used in the transaction's logic (i.e., Figs. 9.6-9.8) to provide the device demands in the ensuing performance model. |




EAN: 2147483647
Pages: 166