4.5 Workload Model
| A workload model is a representation that mimics the real workload under study. It can be a set of programs written and implemented with the goal of artificially testing a system in a controlled environment. A workload model may also serve as input data for an analytical model of a system. It is not practical to have a model composed of thousands of basic components to mimic the real workload. Workload models should be compact and representative of the actual workload [14]. 4.5.1 Types of Workload ModelsWorkload models can be classified into two main categories:
Non-executable workload models are described by a set of average parameter values that reproduce the same resource usage as the real workload. Each parameter denotes an aspect of the execution behavior of the basic component on the system under study. The basic inputs to analytical models are parameters that describe the service centers (i.e., hardware and software resources) and the customers (e.g., transactions and requests). Typical parameters are:
Each type of system may be characterized by a different set of parameters. As an example, consider a parametric characterization of a workload of a distributed system file server [5]. Several factors have a direct influence on the performance of a file server: the system load, the device capability, and the locality of file references. From these factors, the following parameters are defined:
The above parameters specify the workload model and are capable of driving synthetic programs that accurately represent real workloads. Another study [22] looks at an I/O workload from a different perspective. The workload model for a storage device (i.e., queues, caches, controllers, disks) is specified by three classes of parameters: access time attributes, access type (i.e., fraction of reads and writes), and spatial locality attributes [1]. Access time attributes capture the time access pattern, which includes the arrival process (i.e., deterministic, Poisson, bursty), arrival rate, burst rate, burst count, and burst fraction. Spatial locality attributes specify the relationship between consecutive requests, such as sequential and random accesses. Due to "seek" delays, workloads with a larger fraction of sequential accesses typically exhibit better performance than those with random accesses. Thus, for a detailed model of an I/O device, it is important to include the spatial locality attributes of the workload. 4.5.2 Clustering AnalysisConsider a workload that consists of transactions that exhibit a large variability in terms of their CPU and I/O demands. Averaging the demands of all transactions would likely produce a workload model that is not representative of most of the transactions. Therefore, the transactions in the workload have to be grouped, or clustered, so that the variability within each group is relatively small when compared to the variability in the entire data set. These clusters correspond to different classes of a multiclass performance model. The process of generating these rather homogeneous groups is called clustering analysis. While clustering analysis can be performed automatically by specific functions of software packages (e.g., SPSS, SAS, WEKA), a performance analyst should know the fundamentals of this technique. A well-known clustering technique, called k-means clustering, is presented here. Assume that a workload is described by a set of p points wi = (Di1, Di2, ..., DiM) in an M-dimensional space, where each point wi represents a unit of work (e.g., transaction, request) executed by a computer system. The components of a point wi describe specific properties of a transaction, such as the service demand at a particular device or any other value (e.g., I/O count, bytes transmitted) from which service demands can be obtained. Many clustering algorithms, including k-means, require that a distance metric between points be defined. A common distance metric is the Euclidean distance, which defines the distance, di,j, between two points wi = (Di1, Di2, ···, DiM) and wj = (Dj1, Dj2, ···, DjM) as Equation 4.5.2 The use of raw data to compute Euclidean distances may lead to distortions if the components of a point have very different relative values and ranges. For instance, suppose that the workload of a Web server is described by points, each representing an HTTP request, of the type (f, c) where f is the size of the file retrieved by an HTTP request and c is the CPU time required to process the request. Consider the point (25, 30) where f is measured in Kbytes and c in milliseconds. If f is now measured in Mbytes, the point (25, 30) becomes (0.025,30). Such changes of units may result in the modification of the relative distances among groups of points [16]. Scaling techniques should be used to minimize problems that arise from the choice of units and from the different ranges of values of the parameters [16]. The k-means algorithm produces k clusters. Each cluster is represented by its centroid, which is a point whose coordinates are obtained by computing the average of all the coordinates of the points in the cluster. The algorithms starts by determining k points in the workload to act as initial estimates of the centroids of the k clusters. The remaining points are then allocated to the cluster with the nearest centroid. The allocation procedure iterates several times over the input points until no point switches cluster assignment or a maximum number of iterations is performed. Having as input data the p points wi = (Di1, Di2, ···, DiM), the steps required by the k-means algorithm are shown in Fig. 4.5. Figure 4.5. The k-means clustering algorithm. Another distance-based clustering algorithm is the minimum spaning tree algorithm described in [16]. Fractal-based clustering of E-commerce workloads is discussed in [15]. |
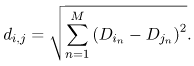

EAN: 2147483647
Pages: 166