5.8 Text Mining Tools
5.8 Text Mining Tools
The market for text mining products can be divided into two groups: text mining tools and kits for constructing applications with embedded text mining facilities. They vary from inexpensive desktop packages to enterprisewide systems costing thousands of dollars. The following is a partial list of text analysis software. Keep in mind, this is not an all-encompassing list; however, analysts need to know what these tools do and how they may want to apply them to solve profiling and forensic needs.
Autonomy
http://www.autonomy.com
Autonomy offers a number of products that use text mining technology for developing internal department or agency networks, intranet, or Web site portal applications. Autonomy's knowledge portal application also provides a unified view of disparate data sources across an organization. Such sources include e-mail, word processing files, PowerPoint presentations, Excel spreadsheets, PDF files, Lotus Notes archives, intranet file servers, SQL/ODBC databases, live chat/IRC, news feeds, and the expertise profiles of other employees. A user-profiling system automatically identifies an employee's area of expertise based on the user's search patterns and document and e-mail content.
For example, users of the Autonomy technology include the Defense Evaluation and Research Agency (DERA), an agency of the U.K. Ministry of Defence responsible for non-nuclear research, technology, testing, and evaluation. The U.K. police forces are also using Autonomy to categorize and tag criminal information stored within police stations. Police officers use the Autonomy Server™ as a central police information repository, categorizing and tagging live information from various sources.
The U.S. DOD is using Autonomy's Portal-in-a-Box™ to make personalized portals available to all of its personnel. The portals automatically draw information from thousands of Internet and intranet sites and create personalized sites for each individual to deliver specific information that the user either explicitly requests or has previously shown an interest in.
Clairvoyance
http://www.claritech.com/
Formerly Claritech, this company was founded in 1992 to commercialize text-analysis technology developed at the Laboratory for Computational Linguistics at Carnegie Mellon University. Clairvoyance's tools employ NLP capabilities, which enable it to carry out in-depth automated analysis of unstructured information. For example, the technology can recognize that different words or phrases can have the same meaning in certain contexts, such as determining that "go for a car" and "really like a car" express similar attitudes. It can also identify "probelm" as a misspelling of "problem" and discern an individual's feelings, attitudes, and intentions by distinguishing the subtle differences among words such as "prefer," "lean toward," and "like a lot" in text-based e-mail messages or call records. It can also differentiate among time expressions such as "soon," "immediately," and "in a few weeks." The ability to gauge the attitudes in the textual content that it analyzes makes this particular software useful for monitoring the communications of suspects in an investigation.
Claivoyance has put a lot of effort into packaging its technology into an application development environment that mainstream developers can use with the following functions:
-
NLP (for morphological analysis and phrase/sub-phrase identification)
-
Automatic document indexing
-
Information retrieval
-
Routing/filtering of streaming texts
-
Subject classification
-
Summarization of documents
-
Automatic thesaurus discovery
-
Spell-checking (empirically based, without a reference lexicon)
-
Information extraction (identification of entities and relations)
-
Virtual hypertext—automatic linking of content "on the fly"
-
Document and concept clustering
-
Compound-document management (combining text and page images)
This text mining technology clearly can be applied to a wide range of monitoring and reporting capabilities for detection and deterrence of a wide variety of criminal and terrorist activities.
ClearForest
http://www.clearforest.com/
Formerly ClearResearch, this text mining software can be used for the analysis and visualization of a large collection of documents. ClearForest can read vast amounts of text, extract relevant information specific to users' requirements, and provide visual, interactive, and executive summaries. ClearForest extracts and delivers knowledge snapshots from structured and unstructured information repositories, allowing investigators and analysts to gain rapid and valuable insights from massive amounts of textual files. This saves end users significant time, enabling them to be more productive and, ultimately, to make better analytical decisions in less time.
As ClearForest's name implies, its software is designed to allows users to obtain a "clear" view of the textual and document "forest." ClearForest's technology assimilates text data of any size and structure, extracts key terms, assigns them to meaningful categories (a taxonomy), and establishes their inter-relationships (see Figure 5.4).
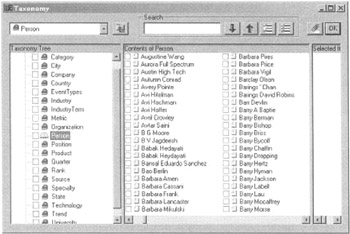
Figure 5.4: ClearForest taxonomy graphical view of an individual.
The output of this tool is a highly structured map of the information that users can slice as needed, generating within seconds patterns in a variety of visual forms, such as maps, tables, and graphs. Information specifically relevant to each user's needs is extracted and displayed in a variety of simple, visual maps that the user can interact with as associations, patterns, updates, and trends are identified (see Figure 5.5).
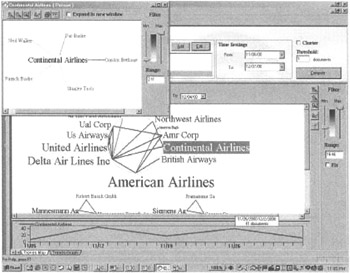
Figure 5.5: Dynamic view of relationships.
Dynamic browsers allow users to drill down and roll up the visual maps as needed in order to focus on the relevant results. Throughout, the system maintains links to the original documents, allowing the user to back up and access the actual documents that contributed to the discovered pattern.
Copernic
http://www.copernic.com/company/index.html
Using agent technology, this firm provides a group of desktop text mining, indexing, and organizing products. Their Copernic 2001 software allows users to find exactly what they want on the Internet by simultaneously accessing the best search engines on the Web. Copernic uses its own technology to query hundreds of specialized and multilanguage Internet sources, including some business databases. Copernic can aggregate and integrate search results from scores of information sources, including intranets, extranets, proprietary networks, and the Web. It uses statistical and linguistic algorithms to retrieve key concepts and extracts the most relevant sentences from the original text. This particular tool combines agent technology for content retrieval and text mining capabilities for concept aggregation, making it a good forensic instrument for investigators and analysts.
DolphinSearch
http://www.dolphinsearch.com/
DolphinSearch provides a text-reading robot, mainly for law-related organizations, powered by a computer model mimicking the object-recognition capabilities of a person. The software is based on neural-network and fuzzy-logic technologies that allow the program to read documents and to know the meaning of the words in their native context. A person solves the problem of understanding the meaning of written sentences by forming vast interconnected networks among the words and their meanings.
These vast networks allow people to make inferences, understand analogies, and do a myriad of other things with words; it is the basis of a theory of semantic projection, which is at the core of this text mining software. Each piece of text (e.g., a document or a paragraph) is translated into a vector for neural network input. One neural network learns the pattern of word relations in the organization's documents and learns to represent the meaning of those words in terms of these vectors. The result of this learning is a semantic profile for each word in the vocabulary. These semantic profiles can be used to compare queries with documents, to compare documents with documents, or to compare documents to serve the interests of the organization or individuals.
DolphinSearch believes organizations differ in the way they understand words. They evolve their own jargon and their own patterns of discourse. Consequently, the software first learns the meanings of words used by a community by reading an authoritative training text. By the way, this concept of training is a key process when using neural networks to recognize patterns in data. The same patterns of word use that allow the members of the community to understand one another can be learned by DolphinSearch so that it can recognize new documents that are relevant to the community and can understand their content. Later, when a community member enters a query, DolphinSearch understands the meaning of the words in that query in the same way that human community members would and finds relevant documents that contain the corresponding concept.
dtSearch
http://www.dtsearch.com/
dtSearch provides several versions of its text mining software for the desktop, Web sites, remote servers, and for embedding in other applications. dtSearch software has over two dozen search options and can work with PDF and HTML files with highlighted hits, embedded links and images, and multiple hit and file navigation options. It can convert XML, word processor, database, spreadsheet, e-mail, zip, Unicode, etc., to HTML for browser display with highlighted hits and multiple navigation options. Most indexed searches take less than a second; indexing, searching, and display do not affect original files. This particular text mining tool is ideally suited for rapid indexing by forensic investigators.
As computer crimes continue to increase, law enforcement and corporate security personnel require new technology to fight this battle. The Forensic Toolkit™ (FTK), from AccessData is a password recovery and forensic file decryption product. FTK offers users a suite of technologies for performing forensic examinations of computer systems. The Known File Filer (KFF) feature can be used to automatically pull out benign files that are known not to contain any potential evidence and flag known problem files for the investigator to examine immediately. The FTK uses the text search engine of dtSearch for all of its searching of text strings; the dtSearch technology is incorporated into the FTK product.
HNC Software
http://www.hnc.com/
HNC's text-analysis technology uses both mathematically-based context vector data modeling techniques and HNC's proprietary neural-network algorithms to automate a number of text-processing applications. Together, these technologies provide the ability to read and learn the content of unstructured, text-based information and to discover relationships between words and documents. This learning capability serves as the foundation for a line of products that provide both interactive and automated decision making based on the text and its internal relationships, as well as predictive modeling of future patterns, trends, and analysis. HNC calls this process context vector modeling.
Context vector modeling is a form of machine learning that employs neural-network techniques to analyze text-based information to automatically discover similarity of usage at the word level. Context vector modeling systems break down a document. They function by translating free text into a mathematical representation composed of vectors. Any text-based object (such as a word, document, or document cluster) is assigned a vector in a multi-dimensional space, referred to as a document universe. A learning algorithm then automatically adjusts word vectors so that the words that are used in similar context will have vectors that point in similar directions. Because the vectors encode the contexts in which the words appear, they are referred to as context vectors. Vectors representing larger bodies of text are derived from the vectors for the individual words occurring within them. As a result, vectors for documents with similar subject content have vectors that point in similar directions. Their proximity (closeness) in the document universe is equivalent to closeness or similarity in subject content.
One of the most important functions of context vector modeling is clustering documents by similarity of meaning. Because documents with similar information content possess context vectors that point in similar directions, it is possible to use a clustering algorithm to find clusters of documents with similar concepts. Moreover, because each document cluster can be represented by a context vector, any operation that can be performed on word or document clusters can also be performed on cluster vectors. For example, the meaning of the clusters can be explained automatically by summarization. This operation consists of determining the words whose vectors are closest to each cluster center.
In addition, the clustering operation can be applied recursively on the cluster centers. The result is a hierarchy of clusters called cluster trees. Because a cluster tree is organized by similarity of meaning, it provides a hierarchical subject index for all the textual information modeled as context vectors. Consequently, cluster trees provide the basis for efficient context vector storage. Once stored as context vectors, words, documents, predefined categories, and naturally occurring document clusters can be directly compared and contrasted. The resulting representation serves as the basic model for conducting a range of text-processing operations, including document retrieval, routing, document summarization, query-by-example, and keyword assignment.
Because the context vector technique is based on a mathematical model, it is language-independent. Thus, this technique can be applied to any language without the need to resort to external dictionaries or thesauri, as is necessary with NLP-based text mining systems. Context vector modeling provides the base technology for most HNC products. Because this type of text mining technology is language neutral, it is especially attractive to government agencies responsible for monitoring foreign textual data.
IBM
http://www-3.ibm.com/software/data/iminer/fortext/index.html
IBM Intelligent Miner for Text offers system integrators and application developers several text-analysis tools, full-text retrieval components, and Web-access tools. IBM's Intelligent Miner for Text is a developer toolkit containing several components, including a text-analysis, feature extraction, clustering, summarization, and categorization set of tools. A free 60-day evaluation of this text mining application development kit is available from IBM.
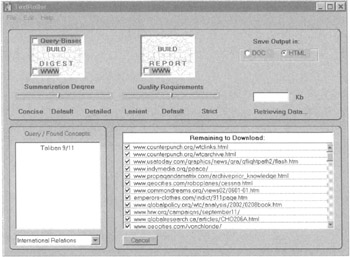
Figure 5.6: TextRoller summary results.
iCrossReader
http://www.insight.com.ru
iCrossReader lets a user automatically build an on-demand survey from excerpts of documents without the need to first search for the texts and conduct a visual review. Created in Russia, InsightSoft combines text processing technology with text-retrieval and text-analysis techniques. The principal of the firm is professor Martin Subbotin, who has over 30 years of experience with intelligent text-processing technologies, having written over 150 scientific papers in the field of text mining. Running on a desktop, the software captures and builds a document corpus or collection on your hard disk, on-the-fly, as it searches. This process requires extensive CPU power because at the same time that it's locating and downloading Web documents, the computer is doing brute-force processing, and analyzing the text streams within each document to determine their relevance to the query. This requires an enormous amount of RAM.
A new agent-based product called TextRoller can retrieve and summarize the content of documents or Web pages in real time. It is available free from this firm's Web site. This is a very impressive little information-retrieval tool. The user simply fills in the small form with some key words, clicks on the WWW window button and TextRoller starts compiling a little folder with relevant Web sites that is placed on the user's desktop or in a predefined directory. A Word file is also created, which extracts the core content of the HTML pages retrieved. What is amazing is the accuracy of the content that is retrieved, the speed with which it performs these tasks, and the fact that the demo of TextRoller is free!
TextRoller can conduct searches on the Web or on internal computer systems for DOC or HTML text. Different settings can be set by domain specificity, such as international relations, scientific, business, economy, etc. In addition, the search parameters can be controlled through some simple sliding controls.
The software does not seek to assemble or create lists of documents that are potentially relevant to a user's query. There's no pre- or post-coordinate indexing or characterizing, no analyzing of the document to create a surrogate record, no attempt to describe or classify the content. Instead, the software uses pure computer power to pour through a document text meticulously to find and extract segments of relevant text information. It uses natural language scanning to identify potentially relevant material and linguistic and semantic text analysis algorithms to extract highly relevant information. In comparison to search engines such as Google, it by far outperforms them in seeking, organizing, and summarizing relevant content on the user's desktop. One word of caution: TextRoller can bring a PC to a grinding halt as it requires a high amount of RAM. All other applications should be closed when using it.
Klarity
http://www.klarity.com.au
Klarity learns, recognizes, analyzes and labels any textual information for subsequent recall; it is an application development text mining tool kit.
Kwalitan
http://www.gamma.rug.nl
Kwalitan uses codes for text fragments to facilitate textual search and display overviews, which can be used to build hierarchical trees.
Leximancer
http://www.leximancer.com
Leximancer makes automatic concept maps of text data collections. First, it creates a map of the documents it collects. Then it constructs concept keys. Leximancer can be used to discover ideas or names linked to an initial concept, such as whether two suspect names refer to the same thing—for instance aliases or a group of closely linked corporations. The technology behind Leximancer is based on Bayesian theory, meaning that by examining the bits and pieces of evidence, it can predict what associations exist.
Leximancer examines the words that make up a sentence in order to predict the concepts being discussed in a document or a collection of text, such as newsgroups, chat files, e-mails, etc. (see Figure 5.7). One of the most important innovations of this system is its ability to learn automatically and efficiently which words predict which concepts for a wide range of concepts across large groups of documents. A very important characteristic of these concepts is that they are defined in advance using only a small number of seed words, often as few as one word.

Figure 5.7: A Leximancer concept map of 155 Internet news groups.
Lextek
http://www.languageidentifier.com
Lextek basically provides a text-profiling engine that can sort through large amounts of data looking for keywords and trying to discern if someone is up to something nefarious. The tool kit could be used either by police departments (for sorting through data on someone's hard drive) or by agencies such as the FBI, CIA, and NSA for watching traffic on the Internet or for scanning other communications. The text mining tool kit can be integrated into an application using C/C++ or other similar programming language. Lextek provides the underlying text-searching technologies, allowing other developers to build their specific forensic application around them. Lextek offers a wide range of document management systems using text-indexing technologies. Its products include the following:
-
Onix Toolkit for adding full-text indexing search and retrieval to applications
-
Lextek Profiling Engine for automatically classifying, routing, and filtering electronic text according to user-defined profiles
-
LanguageIdentifier for identifing what language and character set a document is written in (it supports 260 language and encoding modules)
Other Lextek text mining tool kits include the following:
-
RouteX Document Classifier which uses rules to route documents
-
Brevity Document Summarizer which generates summaries of documents for users
-
SpellWright Spellchecking and PhonMatch Phonetic Toolkits
Typically, building text-search technologies that are competitive speed-wise and that have more than basic functionality is a huge process. For this reason, developers and companies that need this kind of functionality typically license the text-search and categorization technologies from a vendor, such as Lextek. A user requiring text-indexing and search technology would use the Onix engine, while the technology used to locate documents by their subject matter would require the licensing of their Profiling Engine kit.
The main difference is that Onix is better for a specific set of data (such as a database, file system, etc.) where multiple searches are going to be performed. The reason for this is that it takes time to build the index where all the words are. On the other hand, the Lextek Profiling Engine is better suited for filtering and categorizing documents that are in a stream of data. An example of this would be an e-mail stream, scanners watching Internet traffic, etc., where this is done once on a document and not performed on that same document again. Either would be appropriate for integration into criminal analysis software, though this would probably depend a lot on the specific application.
Semio
http://www.semio.com/
Semio offers taxonomy-building and content-mapping tools for automating the process of creating searchable, hierarchical directories for intranets and portal applications. Semio's text mining toolkit consists of a core concept-mapping engine, lexical tools and utilities, client visualization software, and administrative tools and utilities. Semio also provides a text mining tool that features a GUI front end coupled with a back-end, server-based, concept-mapping engine that users can deploy across multiple platforms.
Semio's concept-mapping engine features automatic text processing, including lexical extraction in English, French, Spanish, and Italian. It also has a Java front end to display the engine's text mining results visually in a browser. Semio can process a wide variety of document formats, including text-only, PDF, HTML, Microsoft Office documents, Lotus Notes databases, Web pages, XML, and other sources. Semio uses four automated processes to analyze and categorize text in real time:
-
Text indexing and extraction
-
Concept clustering
-
Taxonomy generation
-
Graphical display and navigation
Semio's lexical technology is based on research in linguistic semiotics. It functions by extracting phrases instead of keywords from text, and it tracks the co-occurrences of extracted phrases. The extractor is customizable for particular applications; for example, for a particular type of investigation, analysts can modify the taxonomy to build or create their own set of keywords. The Semio client component uses data visualization techniques to display key concepts and relationships graphically. This three-dimensional "concept map" lets the user move through related concepts, drill down to different levels of detail, or jump to the referenced documents.
The document categories, which are dynamically generated, are presented based on their relationship to one another in a graphical map. This map allows an investigator or analyst to navigate quickly through the key phrases and relationships within a body of text and drill down and back up to specific documents as desired. Investigators can explore and view a variety of documents, e-mails, articles, chats, and any other textual data using this type of text mining tool.
Temis
http://www.temis-group.com
The Temis Group provides a text mining tool using a combination of components for information extraction, categorization, clustering, and creating automatic reports enabling users to understand and visualize the content of text documents in a multilingual context. Temis also offers its Insight Discoverer and Skill Cartridge text mining engines and software components. Temis can cluster, categorize, and extract text using its Insight Discoverer Clusterer, Categorizer, and Extractor components.
Another application is its Online Miner, which crawls the Web and online databanks, using text mining techniques in any of seven languages. Using their Temis Skill Cartridges, a user can "model" the language (with its grammars, slangs, and vocabularies), defining the target the user wants to monitor. In business applications, this capability allows companies to analyze their customers' and prospects' interactions, such as e-mails, chat lines, newsgroups, forums, and call center transcriptions, in order to recognize similar groups of customers with common interests and feelings. In forensic applications, this allows the detection of "invisible colleges," groups using the same language and styles, and having the same attitudes.
Online Miner can also gather information from large collections of documents in different languages. It can organize the documents by topics through the analysis of clusters; it can group documents by similar content and main themes or by categories. The tool provides content-based navigation by establishing relationships between documents and between topics. It also highlights the strategic content hidden in documents. Online Miner can be used to gather intelligence as described by the definition of objectives, monitoring directions, and targets of interest.
Text Analyst
http://www.megaputer.com
Text Analyst offers semantic analysis of free-form texts, summarization, clustering, navigation, and natural language retrieval with search dynamic refocusing. Text Analysts is one of several data mining components offered by Megaputer, a data mining firm originating in Russia.
TripleHop
http://www.triplehop.com/ie
Formerly Matchpoint, this product collects information from corporate documents, e-mails, Web pages, proprietary network servers, and other data sources; it simultaneously classifies the data and delivers content to specific users based on preset profiles. It uses three levels of information processing (see Figure 5.8):
-
Information Discovery. This layer captures both structured and unstructured data located on the Internet, corporate networks, e-mail servers and internal databases stored in different formats including text, html, Word documents, PDF files, spreadsheets, and database tables.
-
Classification. This layer uses a proprietary algorithm based on a statistical method called support vector machine (SVM) to organize and associate the text.
-
Information Retrieval. This layer routes the retrieved documents by relevance to users.
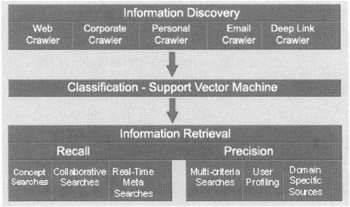
Figure 5.8: TripleHop's three-layer architecture.
This software could be used to collect, organize, and route specific content to members of law enforcement agencies and police departments.
Quenza
http://www.xanalys.com/quenza.html
Quenza automatically extracts entities and cross-references from free-text documents and builds a database for subsequent analysis. Their PowerIndexing component applies a set of rules called a grammar to extract information from text. Grammars are specialized for particular domains; for example, for money-laundering investigations you might need to identify companies, financial information, and commercial activities. Alternatively, you might need to identify people, vehicles, and property in a drug or weapons criminal investigation. The type of investigation would determine the type of grammar an investigator would use with this tool.
Quenza's visualization tool, Watson, can be used to support the development and presentation of prosecution or defense arguments by validating and illustrating patterns, alibis, links, and relations. Watson has been used to find and track individual criminals and criminal gangs, pinpoint and trace the areas and origins of criminal activity, as well as trace and document Internet crimes such as child pornography.
Readware
http://www.readware.com
Readware information processor for intranets and the Internet classifies documents by content and provides literal and conceptual searches. It includes a ConceptBase with English, French, or German lexicons.
VantagePoint
http://www.thevantagepoint.com
VantagePoint provides a variety of interactive graphical views and analysis tools with the ability to discover knowledge from text databases. Including document categorization and utilities for cleaning data, VantagePoint has also the ability to create a thesaurus for data compression and scripting capabilities to automate knowledge gathering. The tool can be configured to text mine most forms of structured bibliographic data.
VisualText™
http://www.textanalysis.com/
VisualText by TextAI is an excellent text mining toolkit for developing custom text analyzers with multiple functions, such as generating rules from text or documents. For those agencies or departments with an IT staff wishing to customize and build its own text analyzer, this kit is ideal. Some functions that this kit supports include the following:
-
Information extraction: systems that extract, correlate, and standardize content
-
Shallow extraction: systems that identify names, locations, and dates in text
-
Indexing: systems for indexing text from the Internet and other sources
-
Filtering: systems that determine if a document is relevant
-
Categorization: systems that determine the topic of documents
-
Test grading: systems for reading and matching prose
-
Summarization: systems for building a brief description of contents in text
-
Automated coding: systems for coding documents, such as police reports
-
Natural language query: systems for interacting with a computer using plain text
-
Dissemination: systems for routing documents to people who require them
VisualText provides a comprehensive interface for quickly building a text analyzer (see Figure 5.9).
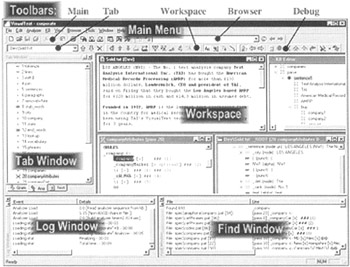
Figure 5.9: The VisualText GUI interface.
Wordstat
http://www.simstat.com/wordstat.htm
Wordstat is a tool for mining textual information contained in responses to open-ended questions; for example, it may be used to analyze interrogation transcripts, criminal interviews, etc., in any text stored in several records of a data file. It supports several optional features, including the following:
-
Optional exclusion of pronouns, conjunctions, etc., by the use of user-defined exclusion lists
-
Categorization of words or phrases using existing or user-defined dictionaries
-
Word and phrase substitution and scoring using wildcards and integer weighting
-
Frequency analysis of words, phrases, derived categories or concepts, or user-defined codes entered manually within a text
-
Interactive development of hierarchical dictionaries or categorization schema
-
Ability to restrict the analysis to specific portions of a text or to exclude comments and annotations
-
Ability to perform an analysis on a random sample of records
-
Integrated spell-checking with support for different languages, such as English, French, Spanish, etc.
-
Integrated thesaurus (English only) to assist the creation of categorization schema
-
Record filtering on any numeric or alphanumeric field and on code occurrence (with AND, OR, and NOT Boolean operators)
-
Ability to define a memo field linked to individual records to write annotations, side notes, comments, or codes
-
Ability to print presentation-quality tables (word count, cross tabs, or KWIC lists)
-
Ability to save any table to ASCII, tab-separated or comma-separated value files or HTML files
-
Option to perform case-sensitive content analysis
-
Option to use disks for the storage of temporary files or the analysis of large files
-
Flexible keyword highlighting (the text editor can display all categories using different colors)
EAN: 2147483647
Pages: 232