5.6 Text Mining for Deception
5.6 Text Mining for Deception
Text mining software developed by Dr. James W. Pennebaker from The University of Texas can be used to detect whether someone is lying or not by keying in a selected number of words. Lying often involves telling a story that is either false or one that the teller doesn't believe. Most research has focused on identifying such lies through nonverbal cues or physiological activity. Dr. Pennebaker's work and software are investigating the linguistic styles that distinguish between true and false stories.
When people attempt to deceive another person, several possible clues to their anxiety—and to their deception—must be controlled at the same time. However, people do not possess the resources required to monitor all possible channels of communication. As a result, deceivers must attempt to control a smaller number of channels. Deceiving another person usually involves the manipulation of language and the careful construction of a story that will appear truthful. In addition to constructing a convincing story, the deceiver also must present it in a style that appears sincere. Although the deceiver has a good deal of control over the content of the story, the style of language used to tell this story may contain clues to the person's underlying state of mind.
The FBI trains its agents in a technique called statement analysis, which attempts to detect deception based on parts of speech (i.e., linguistic style) rather than the facts of the case or the story as a whole. Suspects are first asked to make a written statement. Trained investigators then review this statement, looking for deviations from the expected parts of speech. These deviations from the norm provide agents with topics to explore during interrogation. Before Susan Smith was a suspect in the drowning death of her children, she told reporters, "My children wanted me. They needed me. And now I can't help them." Normally, in a missing-person case, relatives will speak of the missing person in the present tense; the fact that Smith used the past tense suggested that she already viewed them as dead. Human judges may be more accurate at judging the deceptiveness of a communication if they are given time to analyze it and are trained in what to look for. But which dimensions of language are most likely to reveal deception? As seen in the case of Susan Smith, statement analysis works by identifying stylistic features of deception that are context-dependent.
Dr. Pennebaker's approach has been influenced by the analysis of linguistic styles when individuals write or talk about personal topics. Essays that are judged more personal and honest (or, perhaps, less self-deceptive) have a very different linguistic profile than essays that are viewed as more detached. This suggests that creating a false story about a personal topic takes work and results in a different pattern of language use. Extending this idea, Dr. Pennebaker's software can predict that many of these same features would be associated with deception or honesty in text-based communication, such as e-mail. Based on his research, at least three different language dimensions can be associated with deception:
-
Few personal self-references
-
Few markers of making distinctions
-
More negative emotion words
The idea is that deception is a cognitively complex undertaking. From a cognitive perspective, truth tellers are more likely to tell about what they did and what they did not do. That is, they make a distinction between what is in the category of their story and what is not. Individuals who use a higher number of exclusive words are generally healthier than those who do not use these words. Similarly, deceivers might also want to be as imprecise as possible. Statements that are more general are easier to remember, and the deceiver is less likely to be caught in a contradiction by keeping his or her story as simple as possible. In everyday interactions, little or no attention is paid to these linguistic dimensions, but if the appropriate elements of linguistic style could be identified, they might serve as a reliable marker of deception.
The linguistic profiles of Dr. Pennebaker have led to the development of the Linguistic Inquiry and Word Count (LIWC) software, a text-analysis program that computes the percentage of words within various categories that writers or speakers use in normal (i.e., nonclinical) speech or writing samples. The program analyzes written or spoken samples on a word-by-word basis. Each word is then compared against a file of words that are divided into 74 linguistic dimensions. LIWC operates under the assumption that a person's psychological state—in this case, attempting to deceive another person—will be reflected to some degree in the words that are chosen.
In an analysis of five independent samples involving hundreds of writing examples, the LIWC text analysis program correctly classified liars and truth tellers at a rate of 67% when the topic was constant and a rate of 61% overall. Compared to truth-tellers, liars used fewer self-references, other-references, and exclusive words and more "negative emotion" and "motion" words. The lie-detection text analysis software is available from simstat.com. The LIWC program analyzes text files on a word-by-word basis, calculating the percentages of words that match each of several language dimensions. Its output is a text file that can be opened in any of a variety of applications, including word processors and spreadsheet programs. Table 5.1 shows the LIWC 2001 table of dimensions and word examples.
| Dimension | Abbreviation | Examples | Number of Words |
|---|---|---|---|
| |||
| Total pronouns | Pronoun | I, our, they, your | 70 |
| 1st person singular | I | I, my, me | 9 |
| 1st person plural | We | we, our, us | 11 |
| Total first person | Self | I, we, me | 20 |
| Total second person | You | you, your | 14 |
| Total third person | Other | she, their, them | 22 |
| Negations | Negate | no, never, not | 31 |
| Assents | Assent | yes, OK, mmhmm | 18 |
| Articles | Article | a, an, the | 3 |
| Prepositions | Preps | on, to, from | 43 |
| Numbers | Number | one, thirty, million | 29 |
| |||
| Affective or emotional processes | Affect | happy, ugly, bitter | 615 |
| Positive emotions | Posemo | happy, pretty, good | 261 |
| Positive feelings | Posfeel | happy, joy, love | 43 |
| Optimism and energy | Optim | certainty, pride, win | 69 |
| Negative emotions | Negemo | hate, worthless, enemy | 345 |
| Anxiety or fear | Anx | nervous, afraid, tense | 62 |
| Anger | Anger | hate, kill, pissed | 121 |
| Sadness or depression | Sad | grief, cry, sad | 72 |
| Cognitive processes | Cogmech | cause, know, ought | 312 |
| Causation | Cause | because, effect, hence | 49 |
| Insight | Insight | think, know, consider | 116 |
| Discrepancy | Discrep | should, would, could | 32 |
| Inhibition | Inhib | block, constrain | 64 |
| Tentative | Tentat | maybe, perhaps, guess | 79 |
| Certainty | Certain | always, never | 30 |
| Sensory and perceptual processes | Senses | see, touch, listen | 111 |
| Seeing | See | view, saw, look | 31 |
| Hearing | Hear | heard, listen, sound | 36 |
| Feeling | Feel | touch, hold, felt | 30 |
| Social processes | Social | talk, us, friend | 314 |
| Communication | Comm | talk, share, converse | 124 |
| Other references to people | Othref | 1st-per pl, 2nd-, 3rd-per prns | 54 |
| Friends | Friends | pal, buddy, coworker | 28 |
| Family | Family | mom, brother, cousin | 43 |
| Humans | Humans | boy, woman, group | 43 |
| |||
| Time | Time | hour, day, oclock | 113 |
| Past-tense verb | Past | walked, were, had | 144 |
| Present-tense verb | Present | walk, is, be | 256 |
| Future-tense verb | Future | will, might, shall | 14 |
| Space | Space | around, over, up | 71 |
| Up | Up | up, above, over | 12 |
| Down | Down | down, below, under | 7 |
| Inclusive | Incl | with, and, include | 16 |
| Exclusive | Excl | but, except, without | 19 |
| Motion | Motion | walk, move, go | 73 |
| |||
| Occupation | Occup | work, class, boss | 213 |
| School | School | class, student, college | 100 |
| Job or work | Job | employ, boss, career | 62 |
| Achievement | Achieve | try, goal, win | 60 |
| Leisure activity | Leisure | house, TV, music | 102 |
| Home | Home | house, kitchen, lawn | 26 |
| Sports | Sports | football, game, play | 28 |
| Television and movies | TV | TV, sitcom, cinema | 19 |
| Music | Music | tunes, song, cd | 31 |
| Money and financial issues | Money | cash, taxes, income | 75 |
| Metaphysical issues | Metaph | God, heaven, coffin | 85 |
| Religion | Relig | God, church, rabbi | 56 |
| Death and dying | Death | dead, burial, coffin | 29 |
| Physical states and functions | Physcal | ache, breast, sleep | 285 |
| Body states, symptoms | Body | ache, heart, cough | 200 |
| Sex and sexuality | Sexual | lust, penis, fuck | 49 |
| Eating, drinking, dieting | Eating | eat, swallow, taste | 52 |
| Sleeping, dreaming | Sleep | asleep, bed, dreams | 21 |
| Grooming | Groom | wash, bath, clean | 15 |
| Appendix: Experimental dimensions | |||
| Swear words | Swear | damn, fuck, piss | 29 |
| Nonfluencies | Nonfl | uh, rr* | 6 |
| Fillers | Fillers | youknow, Imean | 6 |
The program has 74 preset dimensions (output variables), including linguistic dimensions (e.g., percentage of articles, pronouns), word categories tapping psychological constructs (e.g., positive and negative emotions, causal words), and personal concern categories (e.g., sex, death), and it can accommodate user-defined dimensions as well. The LIWC 2001 Dictionary is composed of 2,290 words and word stems. Each word or word stem defines one or more word categories or sub-dictionaries.
Each of the 74 preset LIWC 2001 categories is composed of a list of dictionary words that defines that scale. Table 5.1 provides a partial list of the LIWC 2001 dictionary categories with sample scale words and relevant scale word counts. The WordStat software has the ability to look at the frequency analysis on words, phrases, derived categories or concepts, or user-defined codes entered manually within a text (see Figure 5.3). The present studies in this area suggest that liars can be reliably identified by their words—not by what they say, but by how they say it.
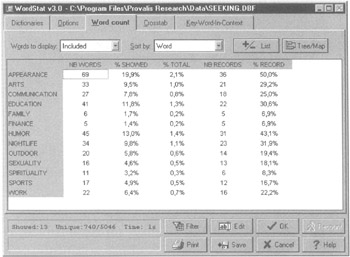
Figure 5.3: WordStat univariate word-frequency analysis.
EAN: 2147483647
Pages: 232