Other Advantages of Running IMS TM in a Sysplex Environment
| The next few sections discuss additional IMS functions that take advantage of the sysplex environment:
Rapid Network ReconnectRapid Network Reconnect (RNR) is IMS's support for VTAM persistent sessions for non-XRF systems. RNR can provide great benefits for some environments, but it is not appropriate for all environments. RNR is optional. VTAM persistent session support eliminates session cleanup and restart when a host failure occurs. There are two kinds of persistent session support:
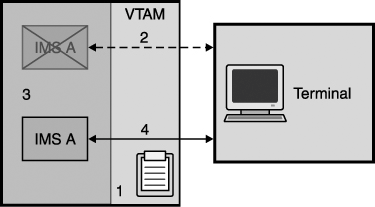
With persistent sessions, end users do not lose their sessions for the supported failures. In fact, they remain logged on. Even though their IMS system fails, their sessions are not terminated. This means that the unbind traffic does not flow through the network when the failure occurs. Secondly, when their IMS system is restarted, their sessions do not have to be reestablished and the bind traffic does not flow. For LU types that typically have users, such as SLUTYPE2 and SLUTYPE1 (CONSOLE), a sign-on is required. For LU types that typically are programmable, such as SLUTYPEP, or do not have direct users, such as LU1 (PRINTER1), a sign-on is not required. Single Node Persistent SessionsWhen using RNR with SNPS, only outages due to IMS abends are mitigated. The VTAM used by this IMS must not fail. The scenario illustrated in Figure 27-13 shows how SNPS works. The numbers in Figure 27-13 refer to the descriptions in the following list. Figure 27-13. SNPS Example Scenario: Logon Is Not Terminated When Its IMS Fails
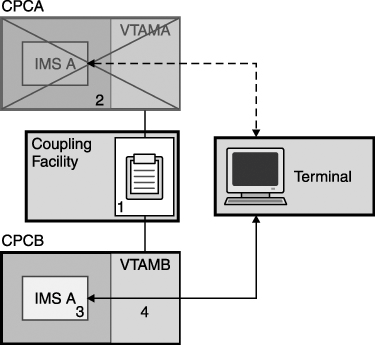
Multinode Persistent SessionsWith MNPS, the session data is stored in a coupling facility structure where it is available to other systems in the sysplex. All types of failures are supported with MNPS. As with SNPS support, when IMS is restarted, the users are automatically reconnected in a "logged on" state. When using RNR with MNPS, all outages of the IMS, VTAM, or processor are mitigated. The scenario illustrated in Figure 27-14 shows how MNPS works. The numbers in Figure 27-14 refer to the descriptions in the following list. Figure 27-14. MNPS Example Scenario: Logon Is Not Terminated When Its IMS Fails
Benefits of Rapid Network ReconnectThe benefit of RNR is the maintenance of the sessions when IMS fails. RNR eliminates the time required to terminate and reestablish the sessions. This eliminates the bind and unbind traffic that would otherwise flow through the network, which can be time consuming. Service to the end users is reestablished more quickly. Of course, the IMS system must be restarted. When using RNR, the end user does not have the option of logging on to another IMS in the Parallel Sysplex. The value of RNR depends on how quickly IMS is restarted. If the restart is slow, there is not much benefit. If the restart is quick, the benefit can be substantial. However, if another system with the same capabilities is available, the users would get quicker restoration of service by logging onto it, which means that RNR is probably not a good solution for IMS systems with clones. Persistent session support for IMS users of APPC (LU 6.2) is provided by APPC/MVS, not IMS. With APPC, the sessions are persistent, but the conversations are not. Sysplex Failure RecoveryParallel Sysplex adds more components to a system. These include clones of systems and subsystems and new components such as coupling facilities and coupling facility links. Even though you might have another component available to do your work when one component fails, you want to restore the sysplex to full robustness as soon as possible. Recoveries from most failures in a sysplex can be automated. Advantages of Multiple Copies of ServersThe main advantage in a sysplex is that you have multiple copies of your servers. When one fails, another is available to do its work. This applies to subsystems, processors, and coupling facilities.
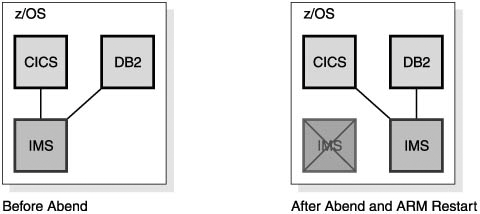
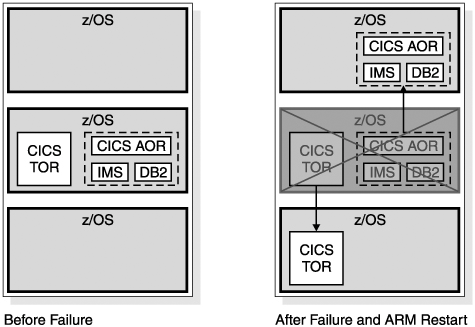
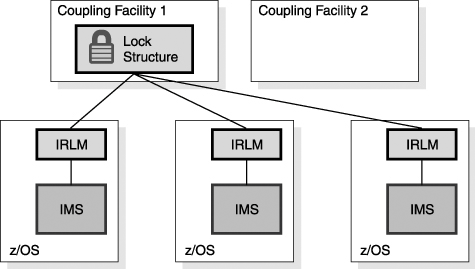
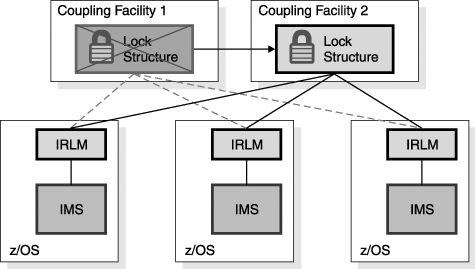
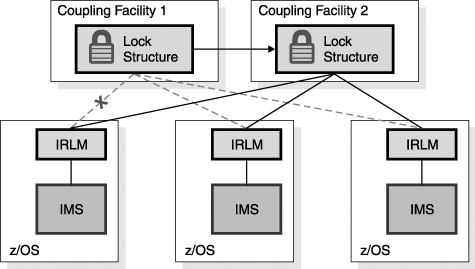
Recovery Using the Automatic Restart Manager (ARM)When IMS fails, you need to restart it as quickly as possible. Even though other IMS systems might be available to do work, the failed IMS might have inflight or indoubt work that needs to be resolved. This resolution releases locks on database resources and releases DBRC authorizations and allows new work to have access to all of the data. ARM can be used to provide rapid restarts of IMS. ARM is a sysplex capability that allows an automatic restart of subsystems such as IMS, DB2, CICS, and IRLM. If the subsystem abends, the restart is on the same z/OS instance (LPAR). If the z/OS (LPAR) fails, the restart is on another z/OS instance in the sysplex. Figure 27-15 illustrates the actions of ARM when an IMS abends. Figure 27-15. ARM Restarting an Abended IMS In Figure 27-15, IMS is restarted on the same z/OS system. This IMS was providing DBCTL services to a CICS and was using a DB2 subsystem. You must restart IMS on the same z/OS so that services between these subsystems can be restored. For example, indoubt threads must be resolved. In the case of a z/OS or processor failure, IMS is restarted on another candidate z/OS (see Figure 27-16 on page 490). The z/OS is chosen according to a user-defined ARM policy. Subsystems that must remain together can be restarted as a group on the same z/OS. In the example in Figure 27-16, an IMS subsystem is using DB2 for database services. A CICS AOR (Application Owning Region) is using the same DB2 and the IMS for database services. When the z/OS system fails, the IMS, the DB2, and the CICS AOR must be moved together, but the CICS TOR (Terminal Owning Region) can be restarted on another z/OS in the sysplex because CICS AORs and TORs can communicate with other z/OS systems. Figure 27-16. ARM Restarting IMS, CICS, and DB2 after a z/OS Failure For ARM to restart subsystems, it must be active in the sysplex. ARM is controlled by a policy that the user defines. The policy is stored in an ARM couple data set. The policy is used to group subsystems for restart together. It also controls whether or not a subsystem is restarted. For example, an installation might not want to restart test subsystems. ARM only restarts subsystems that register with ARM. Subsystems register with ARM when they initialize. IMS uses the ARMRST parameter to control whether or not IMS registers with ARM. ARMRST=Y is the default. IMS has full ARM support. ARM can be used to restart IMS control regions, Common Queue Server regions, Fast Database Recovery regions, Common Service Layer components, and IRLMs. ARM does not directly restart IMS dependent regions. These are typically started by automation when the control region is started. ARMWRAP is a program that registers an address space for ARM restarts. It is used for a step in a job. If the following step fails, ARM restarts the job. IMS Connect does not register with ARM. ARMWRAP can be used to get ARM support for IMS Connect. Recovery After Coupling Facility FailuresMuch of the sysplex support is provided through the use of coupling facility structures. If a CF is lost, it is important to have access to structures elsewhere. If a CF survives, but you lose all of the links from a processor to the CF, you need to resolve the problem. This can be treated like the loss of the CF itself. You can either rebuild its structures on CFs that have connectivity to the processors that require it or you can use duplicate structures. Recovery Using Structure RebuildSome structures can be rebuilt automatically when either a CF failure or a CF link failure occurs. These include IRLM lock structures, OSAM and VSAM cache structures, and IMS shared-queues structures. The example in Figure 27-17 on page 491 uses an IRLM lock structure. Figure 27-17. Three IMSs on Three z/OSs Sharing One IRLM Lock Structure on a Coupling Facility Figure 27-17 shows an IRLM structure on CF1 before a CF failure. Figure 27-18 on page 492 shows a scenario where CF1 (on which the IRLM structure resides) fails. When the CF fails, the system automatically recognizes the loss and rebuilds the lock structure on another CF (CF2). Each IRLM retains the information necessary to restore its lock information in the structure. The IRLMs together rebuild the lock structure on another CF. Data sharing is resumed. Similar rebuild and recovery occurs for OSAM, VSAM, and shared-queue structures. Figure 27-18. IRLM Structure on Failed Coupling Facility Is Rebuilt on Another Coupling Facility In Figure 27-19 on page 492, the CF does not fail. Instead, the connectivity between one of the processors and the CF fails. This case is treated the same as the loss of the CF. That is, the system automatically rebuilds the structure on another CF. All processors have connectivity to this CF. This means that data sharing can continue. Similar rebuild and recovery occurs for OSAM, VSAM, and shared-queue structures. Figure 27-19. IRLM Structure Rebuilt on Another Coupling Facility After a Connectivity Failure Recovery Using Structure DuplexingFast Path shared VSO does not rebuild its cache structures. Instead, it relies on a duplicate copy to provide failure survival. The duplicate copy can be created in either of two ways.
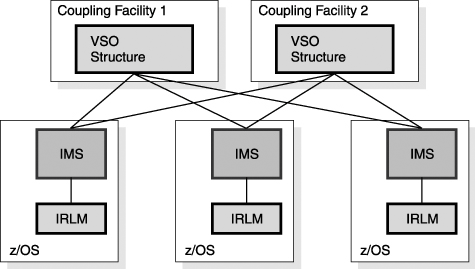
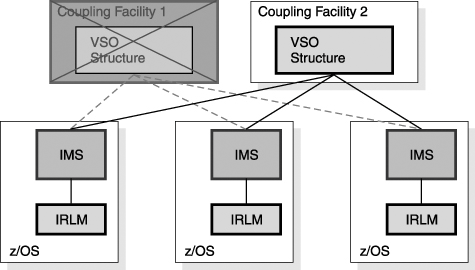
Figure 27-20 shows a duplexed DEDB VSO structure on two coupling facilities that are being shared by three IMSs. Figure 27-20. Shared VSO Structure Duplexed on Two Coupling Facilities If a CF is lost (as shown in Figure 27-21 on page 494), then a duplicate structure on another CF is used. With system-managed duplexing, a duplicate is immediately built if another CF is available. If another CF is not available, a duplicate structure is built when another CF becomes available. Figure 27-21. System-Managed Duplicate Shared VSO Structure Is Used After a Coupling Facility Failure Similarly, if connectivity to a CF is lost, then the use of its structure is discontinued. The duplicate structure on another CF is used instead. |
EAN: 2147483647
Pages: 226