Raising the Level of Reuse
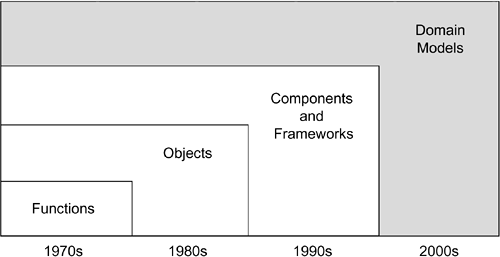
| Though some pundits have suggested that there has been more reuse of the word "reuse" than practice of it, it's undoubtedly the case that a major area of progress in our industry has involved enabling reuse. In the earliest systems, memory was so expensive that it was often necessary to save memory by reusing inline code. If those ten lines of assembly code were the same for one context as for a second, then the confines of limited memory required their reuse. Of course, over time, the minor distinctions between one context and another required flags to distinguish each case, and reuse in this manner deservedly acquired a poor reputation. The solution to this problem was the invention of the callable function. Functions, in the mathematical sense of the word, are ideal for encouraging reuse because they transform their inputs into outputs without recourse to any kind of memory, or "state." The square root function, for example, returns the same result for a given input every time. Mathematical functions lend themselves to reusable libraries for just this reason, and they also increase the granularity of reuse. However, many functions, such as a payroll function, whose output depends on knowledge of previous deductions, employ stored data saved from one invocation to the next. The controlled use of such stored data increased the range of what could be done with reusable functions more properly, subroutines and libraries of these subroutines increased mightily in the 1960s and 1970s. It quickly became apparent that there's value in sharing data between subroutines. The mechanism commonly chosen to implement this concept was a shared (global) data structure. Here swims the fly in this particular ointment: Just as the flags in shared inline code became a maintenance nightmare, so too did shared data structures. When several subroutines each have uncontrolled access to shared data, a change to a data structure in one subroutine leads to the need to change all the other subroutines to match. Thus was born the object. Objects encapsulate a limited number of subroutines and the data structures on which they operate. By encapsulating data and subroutines into a single unit, the granularity of reuse is increased from the level of a single subroutine, with implicit interfaces over other (unnamed) subroutines, to a group of subroutines with explicit (named) interfaces over a limited group of subroutines. Objects enable reuse on a larger scale. Objects are still small-scale, though, given the size of the systems we need to build. There is advantage in reusing collections of related objects together. An Account belongs to a Customer, for example; similarly, the object corresponding with a telephone call is conceptually linked to the circuit on which the call is made. In each case, these objects can, and should, be reused together, connected explicitly in the application. A set of closely related objects, packaged together with a set of defined interfaces, form a component. A component enables reuse at a higher level, because the unit of reuse is larger. However, just as each of the previous stages in increasing granularity raised issues in its usage, so do components. This time, the problem derives from the interfaces. What happens if an interface changes? The answer, of course, is that we have to find each and every place where the interface is used, change it to use the new interface, test that new code, reintegrate, and then retest the system as a whole. A small change in the interface, therefore, leads to many changes in the code. Dividing work across vertical problem areas and defining interfaces between these areas is also problematic. It's all too typical for a project team to begin with an incomplete understanding of the problem and then divide the work involved in solving the problem amongst several development teams. The teams share defined interfaces, working to build components that can simply be plugged together at the end of the project. Of course, it doesn't usually work that way: Teams can have different understanding of the specifications of each of the components, and even the best-specified interface can be misinterpreted. Components, and their big brothers, frameworks, are rarely plug-and-play, and organizations can spend inordinate amounts of time writing "glue code" to stick components together properly. The problem is even worse in systems engineering and hardware/software co-design because the teams don't even share a common language or a common development process. The result tends to be a meeting of the two sides in the lab, some months later, with incompatible hardware and software. Dividing work into horizontal subject-matter areas, or domain models, such as bank, database, authorization, user interface, and so forth, exposes interfaces at the level of rules. "The persistent data of a class is stored as database tables" and "All updates must be authorized" and "Each operation that affects stored data must be confirmed" are all rules that apply uniformly between different domain models. Glue code can be produced automatically based on rules like these. Figure 1-2 illustrates how this progression increases the granularity of reuse. Figure 1-2. Raising the level of reuse
|
EAN: N/A
Pages: 134