Normalization
| Normalization is related conceptually to relationships. Basically, normalization dictates that your database tables eliminate inconsistencies and minimize inefficiency. Recall that databases are called inconsistent when data in one table doesn't match data in another table. For example, if half your staff thinks that Arkansas is in the Midwest and the other half thinks it's in the South and if both factions handle data entry accordingly your database reports on how things are doing in the Midwest will be meaningless. An inefficient database doesn't allow you to isolate the exact data you want. A database in which all the data is stored in one table might force you to slog through myriad customer names, addresses, and contact histories just to retrieve one person's current phone number. In contrast, in a fully normalized database each piece of information in the database is stored in its own table and is identified uniquely by its own primary key. Normalized databases allow you to reference any piece of information in any table if you know that information's primary key. You decide how to normalize a database when you design and initially set it up. Usually, every thing about your database application from table design to query design and from the user interface to the behavior of reports stems from the way you've normalized your database. Note As a database developer, sometimes you'll come across databases that haven't been normalized for one reason or another. The lack of normalization might be intentional (as it's often possible to trade good normalization for other benefits, such as performance). Or it might be a result of inexperience or carelessness on the part of the original database developer. At any rate, if you choose to redesign an existing database to enforce normalization, you should do so early in your development effort (because everythingelse you do will depend on the table structure of the database). Additionally, you will find SQL data-definition language commands to be useful tools in fixing a deficiently designed database. DDL commands enable you to move data from one table to another, as well as add, update, and delete records from tables based on criteria you specify. As an example of the normalization choices you have to make during the database design phase, consider the request made by Brad Jones in Business Case 1.2. His business needs a way to store both a customer's state of residence and the region of the country in which the customer lives. The novice database designer might decide to create one field for state of residence and another field for region of the country.
This structure might initially seem rational, but consider what would happen if you try to enter data into an application based on this table. You'd have to enter the normal customer information name, address, and so on but then, after you'd already entered the customer's state, you'd have to come up with the customer's region. Is Arkansas in the Midwest or the South? What about a resident of the U.S. Virgin Islands? You don't want to leave these kinds of decisions in the hands of your data-entry people no matter how capable they might be because if you rely on the record-by-record decisions of human beings, your data will ultimately be inconsistent. And defeating inconsistency is one of the primary reasons for normalization. Instead of forcing your data-entry people to make a decision each time they type in a new customer, you want to them to store information pertaining to regions in a separate table, tblRegion.
The State and Regional data in such a table would be recorded as follows.
In this refined version of the database design, when you need to retrieve information about a region, you would perform a two-table query with a join between the tblCustomer and tblRegion tables, with one supplying the customer's state and the other identifying the region for that state. Joins match records in separate tables that have fields in common. (See Chapter 2 for more information on how to use joins.) Storing information pertaining to regions in a single table of its own has many advantages, including the following.
In general, then, you should always plan on creating distinct tables for distinct categories of information. Devoting time to database design before you actually build the database will give you an idea as to which database tables you'll need and how they relate to each other. As part of this process, you should map the database schema, as discussed in the Creating a Database Schema section earlier in this chapter. One-to-One RelationshipsSay that your human resources database contains tables for employees and jobs. The relationship between employees and jobs is referred to as a one-to-one relationship because for every employee in the database there is only one job. One-to-one relationships are the easiest kind of relationships to understand and implement. In such relationships, a table usually takes the place of a field in another table, and the fields involved are easy to identify. However, a one-to-one relationship is not the most common relationship found in most mature database applications, for two reasons.
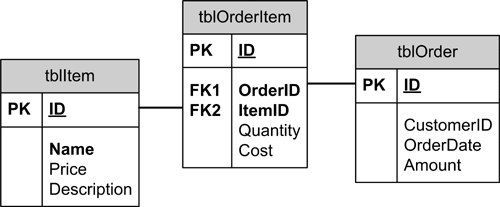
One-to-Many RelationshipsMore common than a one-to-one relationship is a one-to-many relationship, in which each record in a table can have none, one, or many records in a related table. In the database design we created earlier, there's a one-to-many relationship between customers and orders. Because each customer can have none, one, or many orders, we say that a one-to-many relationship exists between tblCustomer and tblOrder. Recall that, to implement this kind of relationship in a database design, you copy the primary key of the "one" side of the relationship to the table that stores the "many" side of the relationship. In a data-driven user interface, this type of relationship is often represented in a master/detail form, in which a single ("master") record is displayed with related ("detail") records displayed in a compact grid beneath them. In a user-interface design, you'll usually copy the primary key of one table to the foreign key of a related table with a list box or combo box. Many-to-Many RelationshipsA many-to-many relationship takes the one-to-many relationship a step farther. The classic example of a many-to-many relationship is the relationship between students and classes. Each student can have multiple classes, and each class has multiple students. (Of course, it's also possible for a class to have one or no students, and it's possible for a student to have one or no classes.) In our business example, there's a relationship between orders and items. Each order can comprise many items, and each item can appear on many orders. To set up a many-to-many relationship, you must have three tables: the two tables that store the actual data and a third table, called a juncture table, that stores the relationship between the two data tables. The juncture table usually consists of nothing more than two foreign keys one from each related table although sometimes it's useful for the juncture table to have an identity field of its own in case you need to access a record in the table programmatically. An example of a many-to-many relationship is to configure the business database to store multiple items per order. Each order can have multiple items, and each item can belong to an unlimited number of orders. These tables would look like those shown in Figure 1.13. Figure 1.13. Tables involved in a many-to-many relationship. In this design, tblOrderItem is the juncture table.
|
EAN: 2147483647
Pages: 97