5.1. Terminology A central component of any operating system is the memory-management system. As the name implies, memory-management facilities are responsible for the management of memory resources available on a machine. These resources are typically layered in a hierarchical fashion, with memory-access times inversely related to their proximity to the CPU (see Figure 5.1 on page 136). The primary memory system is main memory; the next level of storage is secondary storage or backing storage. Main-memory systems usually are constructed from random-access memories, whereas secondary stores are placed on moving-head disk drives. In certain workstation environments, the common two-level hierarchy is becoming a three-level hierarchy, with the addition of file-server machines or network-attached storage connected to a workstation via a local-area network [Gingell, Moran, & Shannon, 1987]. Figure 5.1. Hierarchical layering of memory. 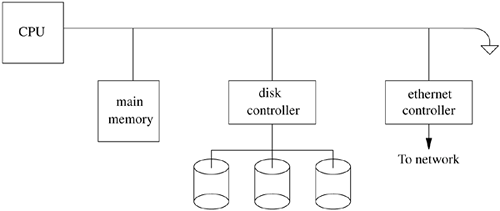
In a multiprogrammed environment, it is critical for the operating system to share available memory resources effectively among the processes. The operation of any memory-management policy is directly related to the memory required for a process to execute. That is, if a process must reside entirely in main memory for it to execute, then a memory-management system must be oriented toward allocating large units of memory. On the other hand, if a process can execute when it is only partially resident in main memory, then memory-management policies are likely to be substantially different. Memory-management facilities usually try to optimize the number of runnable processes that are resident in main memory. This goal must be considered with the goals of the process scheduler (Chapter 4) so that conflicts that can adversely affect overall system performance are avoided. Although the availability of secondary storage permits more processes to exist than can be resident in main memory, it also requires additional algorithms that can be complicated. Space management typically requires algorithms and policies different from those used for main memory, and a policy must be devised for deciding when to move processes between main memory and secondary storage. Processes and Memory Each process operates on a virtual machine that is defined by the architecture of the underlying hardware on which it executes. We are interested in only those machines that include the notion of a virtual address space. A virtual address space is a range of memory locations that a process references independently of the physical memory present in the system. In other words, the virtual address space of a process is independent of the physical address space of the CPU. For a machine to support virtual memory, we also require that the whole of a process's virtual address space does not need to be resident in main memory for that process to execute. References to the virtual address space virtual addresses are translated by hardware into references to physical memory. This operation, termed address translation, permits programs to be loaded into memory at any location without requiring position-dependent addresses in the program to be changed. This relocation of position-dependent addressing is possible because the addresses known to the program do not change. Address translation and virtual addressing are also important in efficient sharing of a CPU, because position independence usually permits context switching to be done quickly. Most machine architectures provide a contiguous virtual address space for processes. Some machine architectures, however, choose to partition visibly a process's virtual address space into regions termed segments [Intel, 1984]. Such segments usually must be physically contiguous in main memory and must begin at fixed addresses. We shall be concerned with only those systems that do not visibly segment their virtual address space. This use of the word segment is not the same as its earlier use in Section 3.5, when we were describing FreeBSD process segments, such as text and data segments. When multiple processes are coresident in main memory, we must protect the physical memory associated with each process's virtual address space to ensure that one process cannot alter the contents of another process's virtual address space. This protection is implemented in hardware and is usually tightly coupled with the implementation of address translation. Consequently, the two operations usually are defined and implemented together as hardware termed the memory-management unit. Virtual memory can be implemented in many ways, some of which are software based, such as overlays. Most effective virtual-memory schemes are, however, hardware based. In these schemes, the virtual address space is divided into fixed-sized units, termed pages, as shown in Figure 5.2. Virtual-memory references are resolved by the address-translation unit to a page in main memory and an offset within that page. Hardware protection is applied by the memory-management unit on a page-by-page basis. Figure 5.2. Paged virtual-memory scheme. Key: MMU memory-management unit. 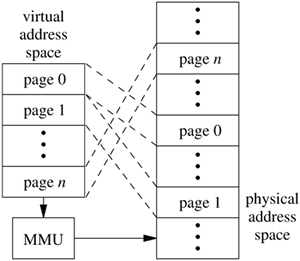
Some systems provide a two-tiered virtual-memory system in which pages are grouped into segments [Organick, 1975]. In these systems, protection is usually at the segment level. In the remainder of this chapter, we shall be concerned with only those virtual-memory systems that are page based. Paging Address translation provides the implementation of virtual memory by decoupling the virtual address space of a process from the physical address space of the CPU. Each page of virtual memory is marked as resident or nonresident in main memory. If a process references a location in virtual memory that is not resident, a hardware trap termed a page fault is generated. The servicing of page faults, or paging, permits processes to execute even if they are only partially resident in main memory. Coffman & Denning [1973] characterize paging systems by three important policies: When the system loads pages into memory the fetch policy Where the system places pages in memory the placement policy How the system selects pages to be removed from main memory when pages are unavailable for a placement request the replacement policy
The performance of modern computers is heavily dependent on one or more highspeed caches to reduce the need to access the much slower main memory. The placement policy should ensure that contiguous pages in virtual memory make the best use of the processor cache. FreeBSD uses a coloring algorithm to ensure good placement. Under a pure demand-paging system, a demand-fetch policy is used, in which only the missing page is fetched, and replacements occur only when main memory is full. Consequently, the performance of a pure demand-paging system depends on only the system's replacement policy. In practice, paging systems do not implement a pure demand-paging algorithm. Instead, the fetch policy often is altered to do prepaging fetching pages of memory other than the one that caused the page fault and the replacement policy is invoked before main memory is full. Replacement Algorithms The replacement policy is the most critical aspect of any paging system. There is a wide range of algorithms from which we can select in designing a replacement strategy for a paging system. Much research has been carried out in evaluating the performance of different page-replacement algorithms [Bansal & Modha, 2004; Belady, 1966; King, 1971; Marshall, 1979]. A process's paging behavior for a given input is described in terms of the pages referenced over the time of the process's execution. This sequence of pages, termed a reference string, represents the behavior of the process at discrete times during the process's lifetime. Corresponding to the sampled references that constitute a process's reference string are real-time values that reflect whether the associated references resulted in a page fault. A useful measure of a process's behavior is the fault rate, which is the number of page faults encountered during processing of a reference string, normalized by the length of the reference string. Page-replacement algorithms typically are evaluated in terms of their effectiveness on reference strings that have been collected from execution of real programs. Formal analysis can also be used, although it is difficult to do unless many restrictions are applied to the execution environment. The most common metric used in measuring the effectiveness of a page-replacement algorithm is the fault rate. Page-replacement algorithms are defined by the criteria that they use for selecting pages to be reclaimed. For example, the optimal replacement policy [Denning, 1970] states that the "best" choice of a page to replace is the one with the longest expected time until its next reference. Clearly, this policy is not applicable to dynamic systems, as it requires a priori knowledge of the paging characteristics of a process. The policy is useful for evaluation purposes, however, as it provides a yardstick for comparing the performance of other page-replacement algorithms. Practical page-replacement algorithms require a certain amount of state information that the system uses in selecting replacement pages. This state typically includes the reference pattern of a process, sampled at discrete time intervals. On some systems, this information can be expensive to collect [Babaoglu & Joy, 1981]. As a result, the "best" page-replacement algorithm may not be the most efficient. Working-Set Model The working-set model assumes that processes exhibit a slowly changing locality of reference. For a period of time, a process operates in a set of subroutines or loops, causing all its memory references to refer to a fixed subset of its address space, termed the working set. The process periodically changes its working set, abandoning certain areas of memory and beginning to access new ones. After a period of transition, the process defines a new set of pages as its working set. In general, if the system can provide the process with enough pages to hold that process's working set, the process will experience a low page-fault rate. If the system cannot provide the process with enough pages for the working set, the process will run slowly and will have a high page-fault rate. Precise calculation of the working set of a process is impossible without a priori knowledge of that process's memory-reference pattern. However, the working set can be approximated by various means. One method of approximation is to track the number of pages held by a process and that process's page-fault rate. If the page-fault rate increases above a high watermark, the working set is assumed to have increased, and the number of pages held by the process is allowed to grow. Conversely, if the page-fault rate drops below a low watermark, the working set is assumed to have decreased, and the number of pages held by the process is reduced. Swapping Swapping is the term used to describe a memory-management policy in which entire processes are moved to and from secondary storage when main memory is in short supply. Swap-based memory-management systems usually are less complicated than are demand-paged systems, since there is less bookkeeping to do. However, pure swapping systems typically are less effective than are paging systems, since the degree of multiprogramming is lowered by the requirement that processes be fully resident to execute. Swapping is sometimes combined with paging in a two-tiered scheme, whereby paging satisfies memory demands until a severe memory shortfall requires drastic action, in which case swapping is used. In this chapter, a portion of secondary storage that is used for paging or swapping is termed a swap area or swap space. The hardware devices on which these areas reside are termed swap devices. Advantages of Virtual Memory There are several advantages to the use of virtual memory on computers capable of supporting this facility properly. Virtual memory allows large programs to be run on machines with main-memory configurations that are smaller than the program size. On machines with a moderate amount of memory, it allows more programs to be resident in main memory to compete for CPU time, as the programs do not need to be completely resident. When programs use sections of their program or data space for some time, leaving other sections unused, the unused sections do not need to be present. Also, the use of virtual memory allows programs to start up faster, since they generally require only a small section to be loaded before they begin processing arguments and determining what actions to take. Other parts of a program may not be needed at all during individual runs. As a program runs, additional sections of its program and data spaces are paged in on demand (demand paging). Finally, there are many algorithms that are more easily programmed by sparse use of a large address space than by careful packing of data structures into a small area. Such techniques are too expensive for use without virtual memory, but they may run much faster when that facility is available, without using an inordinate amount of physical memory. On the other hand, the use of virtual memory can degrade performance. It is more efficient to load a program all at one time than to load it entirely in small sections on demand. There is a finite cost for each operation, including saving and restoring state and determining which page must be loaded, so some systems use demand paging for only those programs that are larger than some minimum size. Hardware Requirements for Virtual Memory Nearly all versions of UNIX have required some form of memory-management hardware to support transparent multiprogramming. To protect processes from modification by other processes, the memory-management hardware must prevent programs from changing their own address mapping. The FreeBSD kernel runs in a privileged mode (kernel mode or system mode) in which memory mapping can be controlled, whereas processes run in an unprivileged mode (user mode). There are several additional architectural requirements for support of virtual memory. The CPU must distinguish between resident and nonresident portions of the address space, must suspend programs when they refer to nonresident addresses, and must resume programs' operation once the operating system has placed the required section in memory. Because the CPU may discover missing data at various times during the execution of an instruction, it must provide a mechanism to save the machine state so that the instruction can be continued or restarted later. The CPU may implement restarting by saving enough state when an instruction begins that the state can be restored when a fault is discovered. Alternatively, instructions could delay any modifications or side effects until after any faults would be discovered so that the instruction execution does not need to back up before restarting. On some computers, instruction backup requires the assistance of the operating system. Most machines designed to support demand-paged virtual memory include hardware support for the collection of information on program references to memory. When the system selects a page for replacement, it must save the contents of that page if they have been modified since the page was brought into memory. The hardware usually maintains a per-page flag showing whether the page has been modified. Many machines also include a flag recording any access to a page for use by the replacement algorithm. |