13.7. TCP Output Processing We are finally ready to investigate the most interesting part of the TCP implementation: the send policy. As we saw earlier, a TCP packet contains an acknowledgment and a window field as well as data, and a single packet may be sent if any of these three fields change. A naive TCP send policy might send many more packets than necessary. For example, consider what happens when a user types one character to a remote-terminal connection that uses remote echo. The server-side TCP receives a single-character packet. It might send an immediate acknowledgment of the character. Then, milliseconds later, the login server would read the character, removing the character from the receive buffer; the TCP might immediately send a window update, noting that one additional octet of send window was available. After another millisecond or so, the login server would send an echoed character back to the client, necessitating a third packet sent in response to the single character of input. It is obvious that all three responses (the acknowledgment, the window update, and the data return) could be sent in a single packet. However, if the server were not echoing input data, the acknowledgment could not be withheld for too long a time or the client-side TCP would begin to retransmit. The algorithms used in the send policy to minimize network traffic yet to maximize throughput are the most subtle part of a TCP implementation. The send policy used in FreeBSD includes several standard algorithms, as well as a few approaches suggested by the network research community. We shall examine each part of the send policy. As we saw in the previous section, there are several different events that may trigger the sending of data on a connection; in addition, packets must be sent to communicate acknowledgments and window updates (consider a one-way connection!). Sending of Data The most obvious reason that the tcp output module tcp_output() is called is that the user has written new data to the socket. Write operations are done with a call to tcp_usr_send() routine. (Recall that sosend() waits for enough space in the socket send buffer if necessary and then copies the user's data into a chain of mbufs that is passed to the protocol by the tcp_usr_send() routine.) The action in tcp_usr_send() is simply to place the new output data in the socket's send buffer with sbappendstream() and to call tcp_output(). If flow control permits, tcp_output() will send the data immediately. The actual send operation is not substantially different from one for a UDP datagram socket. The differences are that the header is more complicated and additional fields must be initialized, and the data sent are simply a copy of the user's data. However, for send operations large enough for sosend() to place the data in external mbuf clusters, the copy is done by creating a new reference to the data cluster. A copy must be retained in the socket's send buffer in case retransmission is required. Also, if the number of data octets is larger than the size of a single maximum-sized segment, multiple packets will be constructed and sent in a single call. The tcp_output() routine allocates an mbuf to contain the output packet header and copies the contents of the header template into that mbuf. If the data to be sent fit into the same mbuf as the header, tcp_output() copies them into place from the socket send buffer using the m_copydata() routine. Otherwise, tcp_output() adds the data to be sent as a separate chain of mbufs obtained with an m_copy() operation from the appropriate part of the send buffer. The sequence number for the packet is set from snd_nxt, and the acknowledgment is set from rcv_nxt. The flags are obtained from an array containing the flags to be sent in each connection state. The window to be advertised is computed from the amount of space remaining in the socket's receive buffer; however, if that amount is small (less than one-fourth of the buffer and less than one segment), it is set to zero. The window is never allowed to end at a smaller sequence number than the one in which it ended in the previous packet. If urgent data have been sent, the urgent pointer and flag are set accordingly. One other flag must be set: The PUSH flag on a packet indicates that data should be passed to the user; it is like a buffer-flush request. This flag is generally considered obsolete but is set whenever all the data in the send buffer have been sent; FreeBSD ignores this flag on input. Once the header is filled in, the packet is checksummed. The remaining parts of the IP header are initialized, including the type-of-service and time-to-live fields, and the packet is sent with ip_output(). The retransmission timer is started if it is not already running, and the snd_nxt and snd_max values for the connection are updated. Avoidance of the Silly-Window Syndrome Silly-window syndrome is the name given to a potential problem in a window-based flow-control scheme in which a system sends several small packets rather than waiting for a reasonable-sized window to become available [Clark, 1982]. For example, if a network-login client program has a total receive buffer size of 4096 octets, and the user stops terminal output during a large printout, the buffer will become nearly full as new full-sized segments are received. If the remaining buffer space dropped to 10 bytes, it would not be useful for the receiver to volunteer to receive an additional 10 octets. If the user then allowed a few characters to print and stopped output again, it still would not be useful for the receiving TCP to send a window update allowing another 14 octets. Instead, it is desirable to wait until a reasonably large packet can be sent, since the receive buffer already contains enough data for the next several pages of output. Avoidance of the silly-window syndrome is desirable in both the receiver and the sender of a flow-controlled connection, as either end can prevent silly small windows from being used. We described receiver avoidance of the silly-window syndrome in the previous subsection; when a packet is sent, the receive window is advertised as zero if it is less than one packet and less than one-fourth of the receive buffer. For sender avoidance of the silly-window syndrome, an output operation is delayed if at least a full packet of data is ready to be sent but less than one full packet can be sent because of the size of the send window. Instead of sending, tcp_output() sets the output state to persist state by starting the persist timer. If no window update has been received by the time that the timer expires, the allowable data are sent in the hope that the acknowledgment will include a larger window. If it does not, the connection stays in persist state, sending a window probe periodically until the window is opened. An initial implementation of sender avoidance of the silly-window syndrome produced large delays and low throughput over connections to hosts using TCP implementations with tiny buffers. Unfortunately, those implementations always advertised receive windows less than the maximum segment size a behavior that was considered silly by this implementation. As a result of this problem, the TCP keeps a record of the largest receive window offered by a peer in the protocol-control-block variable max_sndwnd. When at least one-half of max_sndwnd may be sent, a new segment is sent. This technique improved performance when a BSD system was communicating with these limited hosts. Avoidance of Small Packets Network traffic exhibits a bimodal distribution of sizes. Bulk data transfers tend to use the largest possible packets for maximum throughput. Interactive services (such as network-login) tend to use small packets, however, often containing only a single data character. On a fast local-area network, such as an Ethernet, the use of single-character packets generally is not a problem because the network bandwidth usually is not saturated. On long-haul networks interconnected by slow or congested links, or wireless LANs that are both slow and lossy, it is desirable to collect input over some period and then send it in a single network packet. Various schemes have been devised for collecting input over a fixed time usually about 50 to 100 milliseconds and then sending it in a single packet. These schemes noticeably slow character echo times on fast networks, however, and often save few packets on slow networks. In contrast, a simple and elegant scheme for reducing small-packet traffic was suggested by Nagle [1984]. This scheme allows the first octet output to be sent alone in a packet with no delay. Until this packet is acknowledged, however, no new small packets may be sent. If enough new data arrive to fill a maximum-sized packet, another packet is sent. As soon as the outstanding data are acknowledged, the input that was queued while waiting for the first packet may be sent. Only one small packet may ever be outstanding on a connection at one time. The net result is that data from small output operations are queued during one round-trip time. If the round-trip time is less than the intercharacter arrival time, as it is in a remote-terminal session on a local-area network, transmissions are never delayed, and response time remains low. When a slow network intervenes, input after the first character is queued, and the next packet contains the input received during the preceding round-trip time. This algorithm is attractive because of both its simplicity and its self-tuning nature. Eventually, people discovered that this algorithm did not work well for certain classes of network clients that sent streams of small requests that could not be batched. One such client was the network-based X Window System [Scheifler & Gettys, 1986], which required immediate delivery of small messages to get real-time feedback for user interfaces such as rubber-banding to sweep out a new window. Hence, the developers added an option, TCP_NODELAY, to defeat this algorithm on a connection. This option can be set with a setsockopt call, which reaches TCP via the tcp_ctloutput() routine. Unfortunately, the X Window System library always sets the TCP_NODELAY flag, rather than only when the client is using mouse-driven positioning. Delayed Acknowledgments and Window Updates TCP packets must be sent for reasons other than data transmission. On a one-way connection, the receiving TCP must still send packets to acknowledge received data and to advance the sender's send window. The mechanism for delaying acknowledgments in hope of piggybacking or coalescing them with data or window updates was described in Section 13.6. In a bulk data transfer, the time at which window updates are sent is a determining factor for network throughput. For example, if the receiver simply set the TF_DELACK flag each time that data were received on a bulk-data connection, acknowledgments would be sent every 200 milliseconds. If 8192-octet windows are used on a 10-Mbit/s Ethernet, this algorithm will result in a maximum throughput of 320 Kbit/s, or 3.2 percent of the physical network bandwidth. Clearly, once the sender has filled the send window that it has been given, it must stop until the receiver acknowledges the old data (allowing them to be removed from the send buffer and new data to replace them) and provides a window update (allowing the new data to be sent). Because TCP's window-based flow control is limited by the space in the socket receive buffer, TCP has the PR_RCVD flag set in its protocol-switch entry so that the protocol will be called (via the tcp_usr_rcvd() routine) when the user has done a receive call that has removed data from the receive buffer. The tcp_usr_rcvd() routine simply calls tcp_output(). Whenever tcp_output() determines that a window update sent under the current circumstances would provide a new send window to the sender large enough to be worthwhile, it sends an acknowledgment and window update. If the receiver waited until the window was full, the sender would already have been idle for some time when it finally received a window update. Furthermore, if the send buffer on the sending system was smaller than the receiver's buffer and thus smaller than the receiver's window the sender would be unable to fill the receiver's window without receiving an acknowledgment. Therefore, the window-update strategy in FreeBSD is based on only the maximum segment size. Whenever a new window update would move the window forward by at least two full-sized segments, the window update is sent. This window-update strategy produces a twofold reduction in acknowledgment traffic and a twofold reduction in input processing for the sender. However, updates are sent often enough to give the sender feedback on the progress of the connection and to allow the sender to continue sending additional segments. Note that TCP is called at two different stages of processing on the receiving side of a bulk data transfer: It is called on packet reception to process input, and it is called after each receive operation removing data from the input buffer. At the first call, an acknowledgment could be sent, but no window update could be sent. After the receive operation, a window update also is possible. Thus, it is important that the algorithm for updates run in the second half of this cycle. Retransmit State When the retransmit timer expires while a sender is awaiting acknowledgment of transmitted data, tcp_output() is called to retransmit. The retransmit timer is first set to the next multiple of the round-trip time in the backoff series. The variable snd_nxt is moved back from its current sequence number to snd_una. A single packet is then sent containing the oldest data in the transmit queue. Unlike some other systems, FreeBSD does not keep copies of the packets that have been sent on a connection; it retains only the data. Thus, although only a single packet is retransmitted, that packet may contain more data than does the oldest outstanding packet. On a slow connection with small send operations, such as a remote login, this algorithm may cause a single-octet packet that is lost to be retransmitted with all the data queued since the initial octet was first transmitted. If a single packet was lost in the network, the retransmitted packet will elicit an acknowledgment of all data transmitted thus far. If more than one packet was lost, the next acknowledgment will include the retransmitted packet and possibly some of the intervening data. It may also include a new window update. Thus, when an acknowledgment is received after a retransmit timeout, any old data that were not acknowledged will be resent as though they had not yet been sent, and some new data may be sent as well. Slow Start Many TCP connections traverse several networks between source and destination. When some of the networks are slower than others, the entry router to the slowest network often is presented with more traffic than it can handle. It may buffer some input packets to avoid dropping them because of sudden changes in flow, but eventually its buffers will fill and it must begin dropping packets. When a TCP connection first starts sending data across a fast network to a router forwarding via a slower network, it may find that the router's queues are already nearly full. In the original send policy used in BSD, a bulk-data transfer would start out by sending a full window of packets once the connection was established. These packets could be sent at the full speed of the network to the bottleneck router, but that router could transmit them only at a much slower rate. As a result, the initial burst of packets was highly likely to overflow the router's queue, and some of the packets would be lost. If such a connection used an expanded window size in an attempt to gain performance for example, when traversing a satellite-based network with a long round-trip time this problem would be even more severe. However, if the connection could once reach steady state, a full window of data often could be accommodated by the network if the packets were spread evenly throughout the path. At steady state, new packets would be injected into the network only when previous packets were acknowledged, and the number of packets in the network would be constant. Figure 13.9 shows the desired steady state. In addition, even if packets arrived at the outgoing router in a cluster, they would be spread out when the network was traversed by at least their transmission times in the slowest network. If the receiver sent acknowledgments when each packet was received, the acknowledgments would return to the sender with approximately the correct spacing. The sender would then have a self-clocking means for transmitting at the correct rate for the network without sending bursts of packets that the bottleneck could not buffer. Figure 13.9. Acknowledgment clocking. There are two routers connected by a slow link between the sender and the receiver. The thickness of the links represents their speed. The width of the packets represents their time to travel down the link. Fast links are wide and the packets are narrow. Slow links are narrow and the packets are wide. In the steady state shown, the sender sends a new packet each time an acknowledgment is received from the receiver. 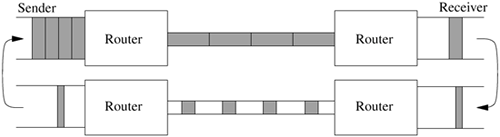
An algorithm named slow start brings a TCP connection to this steady state [Jacobson, 1988]. It is called slow start because it is necessary to start data transmission slowly when traversing a slow network. Figure 13.10 shows the progress of the slow-start algorithm. The scheme is simple: A connection starts out with a limit of just one outstanding packet. Each time that an acknowledgment is received, the limit is increased by one packet. If the acknowledgment also carries a window update, two packets can be sent in response. This process continues until the window is fully open. During the slow-start phase of the connection, if each packet was acknowledged separately, the limit would be doubled during each exchange, resulting in an exponential opening of the window. Delayed acknowledgments might cause acknowledgments to be coalesced if more than one packet could arrive at the receiver within 200 milliseconds, slowing the window opening slightly. However, the sender never sends bursts of more than two or three packets during the opening phase and sends only one or two packets at a time once the window has opened. Figure 13.10. The progression of the slow-start algorithm. 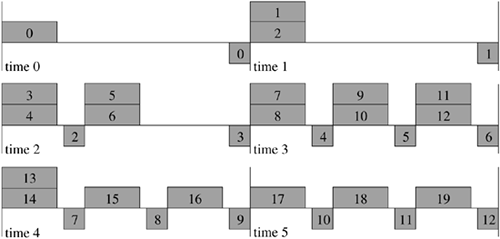
The implementation of the slow-start algorithm uses a second window, like the send window but maintained separately, called the congestion window (snd_cwnd). The congestion window is maintained according to an estimate of the data that the network is currently able to buffer for this connection. The send policy is modified so that new data are sent only if allowed by both the normal and congestion send windows. The congestion window is initialized to the size of one packet, causing a connection to begin with a slow start. It is set to one packet whenever transmission stops because of a timeout. Otherwise, once a retransmitted packet was acknowledged, the resulting window update might allow a full window of data to be sent, which would once again overrun intervening routers. This slow start after a retransmission timeout eliminates the need for a test in the output routine to limit output to one packet on the initial timeout. In addition, the timeout may indicate that the network has become slower because of congestion, and temporary reduction of the window may help the network to recover from its condition. The connection is forced to reestablish its clock of acknowledgments after the connection has come to a halt, and the slow start has this effect as well. A slow start is also forced if a connection begins to transmit after an idle period of at least the current retransmission value (a function of the smoothed round-trip time and variance estimates). Source-Quench Processing If a router along the route used by a connection receives more packets than it can send along this path, it will eventually be forced to drop packets. When packets are dropped, the router may send an ICMP source quench error message to hosts whose packets have been dropped to indicate that the senders should slow their transmissions. Although this message indicates that some change should be made, it provides no information on how much of a change must be made or for how long the change should take effect. In addition, not all routers send source-quench messages for each packet dropped. The use of the slow-start algorithm after retransmission timeouts allows a connection to respond correctly to a dropped packet whether or not a source quench is received to indicate the loss. The action on receipt of a source quench for a TCP connection is simply to anticipate the timeout because of the dropped packet, setting the congestion window to one packet. This action prevents new packets from being sent until the dropped packet is resent at the next timeout. At that time, the slow start will begin again. Buffer and Window Sizing The performance of a TCP connection is obviously limited by the bandwidth of the path that the connection must transit. The performance is also affected by the round-trip time for the path. For example, paths that traverse satellite links have a long intrinsic delay, even though the bandwidth may be high, but the throughput is limited to one window of data per round-trip time. After filling the receiver's window, the sender must wait for at least one round-trip time for an acknowledgment and window update to arrive. To take advantage of the full bandwidth of a path, both the sender and receiver must use buffers at least as large as the bandwidth-delay product to allow the sender to transmit during the entire round-trip time. In steady state, this buffering allows the sender, receiver, and intervening parts of the network to keep the pipeline filled at each stage. For some paths, using slow start and a large window can lead to much better performance than could be achieved previously. The round-trip time for a network path includes two components: transit time and queueing time. The transit time comprises the propagation, switching, and forwarding time in the physical layers of the network, including the time to transmit packets bit by bit after each store-and-forward hop. Ideally, queueing time would be negligible, with packets arriving at each node of the network just in time to be sent after the preceding packet. This ideal flow is possible when a single connection using a suitable window size is synchronized with the network. However, as additional traffic is injected into the network by other sources, queues build up in routers, especially at the entrance to the slower links in the path. Although queueing delay is part of the round-trip time observed by each network connection that is using a path, it is not useful to increase the operating window size for a connection to a value larger than the product of the limiting bandwidth for the path times the transit delay. Sending additional data beyond that limit causes the additional data to be queued, increasing queueing delay without increasing throughput. Avoidance of Congestion with Slow Start The addition of the slow-start algorithm to TCP allows a connection to send packets at a rate that the network can tolerate, reaching a steady state at which packets are sent only when another packet has exited the network. A single connection may reasonably use a large window without flooding the entry router to the slow network on startup. As a connection opens the window during a slow start, it injects packets into the network until the network links are kept busy. During this phase, it may send packets at up to twice the rate at which the network can deliver data because of the exponential opening of the window. If the window is chosen appropriately for the path, the connection will reach steady state without flooding the network. However, with multiple connections sharing a path, the bandwidth available to each connection is reduced. If each connection uses a window equal to the bandwidth-delay product, the additional packets in transit must be queued, increasing delay. If the total offered load is too high, routers must drop packets rather than increasing the queue sizes and delay. Thus, the appropriate window size for a TCP connection depends not only on the path, but also on competing traffic. A window size large enough to give good performance when a long-delay link is in the path will overrun the network when most of the round-trip time is in queueing delays. It is highly desirable for a TCP connection to be self-tuning, as the characteristics of the path are seldom known at the endpoints and may change with time. If a connection expands its window to a value too large for a path, or if additional load on the network collectively exceeds the capacity, router queues will build until packets must be dropped. At this point, the connection will close the congestion window to one packet and will initiate a slow start. If the window is simply too large for the path, however, this process will repeat each time that the window is opened too far. The connection can learn from this problem and can adjust its behavior using another algorithm associated with the slow-start algorithm. This algorithm keeps a state variable for each connection, snd_ssthresh (slow-start threshold), which is an estimate of the usable window for the path. When a packet is dropped, as evidenced by a retransmission timeout, this window estimate is set to one-half the number of the outstanding data octets. The current window is obviously too large at the moment, and the decrease in window utilization must be large enough that congestion will decrease rather than stabilizing. At the same time, the slow-start window (snd_cwnd) is set to one segment to restart. The connection starts up as before, opening the window exponentially until it reaches the snd_ssthresh limit. At this point, the connection is near the estimated usable window for the path. It enters steady state, sending data packets as allowed by window updates. To test for improvement in the network, it continues to expand the window slowly; as long as this expansion succeeds, the connection can continue to take advantage of reduced network load. The expansion of the window in this phase is linear, with one additional full-sized segment being added to the current window for each full window of data transmitted. This slow increase allows the connection to discover when it is safe to resume use of a larger window while reducing the loss in throughput because of the wait after the loss of a packet before transmission can resume. Note that the increase in window size during this phase of the connection is linear as long as no packets are lost, but the decrease in window size when signs of congestion appear is exponential (it is divided by 2 on each timeout). With the use of this dynamic window-sizing algorithm, it is possible to use larger default window sizes for connection to all destinations without overrunning networks that cannot support them. Fast Retransmission Packets can be lost in the network for two reasons: congestion and corruption. In either case, TCP detects lost packets by a timeout, causing a retransmission. When a packet is lost, the flow of packets on a connection comes to a halt while waiting for the timeout. Depending on the round-trip time and variance, this timeout can result in a substantial period during which the connection makes no progress. Once the timeout occurs, a single packet is retransmitted as the first phase of a slow start, and the slow-start threshold is set to one-half the previous operating window. If later packets are not lost, the connection goes through a slow startup to the new threshold, and it then gradually opens the window to probe whether any congestion has disappeared. Each of these phases lowers the effective throughput for the connection. The result is decreased performance, even though the congestion may have been brief. When a connection reaches steady state, it sends a continuous stream of data packets in response to a stream of acknowledgments with window updates. If a single packet is lost, the receiver sees packets arriving out of order. Most TCP receivers, including FreeBSD, respond to an out-of-order segment with a repeated acknowledgment for the in-order data. If one packet is lost while enough packets to fill the window are sent, each packet after the lost packet will provoke a duplicate acknowledgment with no data, window update, or other new information. The receiver can infer the out-of-order arrival of packets from these duplicate acknowledgments. Given enough evidence of reordering, the receiver can assume that a packet has been lost. The FreeBSD TCP implements fast retransmission based on this signal. Figure 13.11 shows the sequence of packet transmissions and acknowledgments when using the fast-retransmission algorithm during the loss of a single packet. After detecting three identical acknowledgments, the tcp_input () function saves the current connection parameters, simulates a retransmission timeout to resend one segment of the oldest data in the send queue, and then restores the current transmit state. Because this indication of a lost packet is a congestion signal, the estimate of the network buffering limit, snd_ssthresh, is set to one-half of the current window. However, because the stream of acknowledgments has not stopped, a slow start is not needed. If a single packet has been lost, doing fast retransmission fills in the gap more quickly than would waiting for the retransmission timeout. An acknowledgment for the missing segment, plus all out-of-order segments queued before the retransmission, will then be received, and the connection can continue normally. Figure 13.11. Fast retransmission. The thick, longer boxes represent the data packets being sent. The thin, shorter lines represent the acknowledgments being returned. 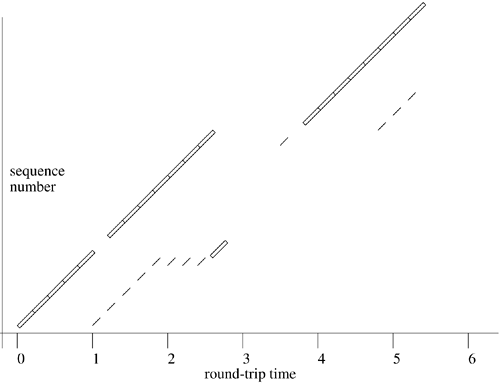
Even with fast retransmission, it is likely that a TCP connection that suffers a lost segment will reach the end of the send window and be forced to stop transmission while awaiting an acknowledgment for the lost segment. However, after the fast retransmission, duplicate acknowledgments are received for each additional packet received by the peer after the lost packet. These duplicate acknowledgments imply that a packet has left the network and is now queued by the receiver. In that case, the packet does not need to be considered as within the network congestion window, possibly allowing additional data to be sent if the receiver's window is large enough. Each duplicate acknowledgment after a fast retransmission thus causes the congestion window to be moved forward artificially by the segment size. If the receiver's window is large enough, it allows the connection to make forward progress during a larger part of the time that the sender awaits an acknowledgment for the retransmitted segment. For this algorithm to have effect, the sender and receiver must have additional buffering beyond the normal bandwidth-delay product; twice that amount is needed for the algorithm to have full effect. |