Constructing Test Cases
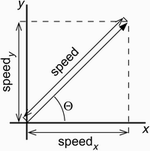
| Let us investigate how to identify and construct test cases for a class. First, we will look at how to identify test cases from a class specification expressed in OCL. Then we will look at test case construction from a state transition diagram. Test cases are usually identified from the class specification, which can be expressed in a variety of ways. These include OCL, natural language, and/or state transition diagrams. Test cases can be identified from a class implementation, but using only that approach will propagate errors the class developer has made in interpreting the specification during implementation to the test software. We prefer to develop test cases initially from the specification and then augment them with additional cases as needed to test boundaries introduced by the implementation. If a specification does not exist for a class to be tested, then we "reverse engineer" one and have it reviewed by the developers before we start testing. Most of the examples in this chapter will be based on testing the Velocity and PuckSupply classes from Brickles. A puck supply is a collection of pucks that have not yet been put into play. A velocity represents the movement of a movable sprite on a playfield based on attributes of a speed (expressed in playfield units per unit time) and a direction (expressed as an angle in degrees, with 0 designating east or right, 90 designating north or up, and so on) (see Figure 5.1). The speed attribute is broken into two components: speedx speed in the x direction (left-right) and speedy speed in the y direction (up-down). While the speed attribute is always a non-negative value, the components of a velocity's speed can be negative. The value of speedx is negative if a velocity's direction is heading left. The value of speedy is negative if the direction is down. Speed and Direction are abstract types ultimately defined as integer values. Figure 5.1. A velocity is a vector characterized by a speed and a direction Q
A class model for Velocity is shown in Figure 5.2. Its OCL specification is shown in Figure 5.3. The invariant for the class constrains the value for direction and speed as well as the relationships between the values of those attributes, including the speedx, and speedy components. Because these attributes are integer-valued, the invariant relaxes the ideal relationship described by the Pythagorean theorem. Figure 5.2. The Velocity class as specified in the UML model
Figure 5.3. OCL specification for the Velocity class
The design of Velocity includes the setSpeed() and setDirection() modifiers to improve runtime efficiency by eliminating the need to create a new instance every time one or both attribute values change. Test Case Construction from Pre- and PostconditionsThe general idea for identifying test cases from preconditions and postconditions for an operation is to identify requirements for test cases for all possible combinations of situations in which a precondition can hold and postconditions can be achieved. Then create test cases to address these requirements. From the requirements, create test cases with specific input values, including typical values and boundary values, and determine the correct outputs. Finally, add test cases to address what happens when a precondition is violated (see sidebar). To identify general test case requirements from pre- and postconditions, we can analyze each of the logical connectives in an OCL condition and list the test cases that result from the structure of that condition. Figure 5.4 and Figure 5.5 list the requirements for test cases that result from various forms of logical expressions in preconditions and postconditions, respectively. Figure 5.4 identifies additional test cases that result from an implicit use of defensive programming. Notice the significant increase in the number of test case requirements over the contract approach. Figure 5.4. Contribution to the test suite by preconditions
Figure 5.5. Contribution to the test suite by postconditions
Use these two figures to find requirements for the minimum number of test cases[3] needed to test an operation specified using all combinations of preconditions and postconditions. Follow these steps:
If a precondition or a postcondition has a more complex form than is shown in the table for example, involving three disjuncts then the processes described in Steps 1 and 2 will have to be applied recursively that is, broken into smaller pieces with the rules applied to the pieces, and then applied together as the pieces are recombined with operators. Fortunately, widely accepted object-oriented design principles keep most preconditions and postconditions simple. Figure 5.6 and Figure 5.7 show examples of how to use these tables for two of the operations in the Velocity class. Figure 5.6. Identifying test cases for Velocity::setDirection()
Figure 5.7. Identifying test cases for Velocity::reverseX()
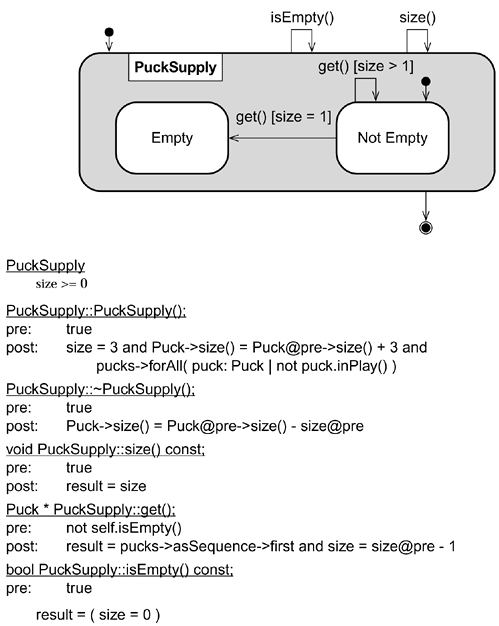
Test Case Construction from State Transition DiagramsState transition diagrams show the behavior associated with instances of a class graphically. These diagrams can supplement written specifications or comprise the entire specification. A state transition diagram for the PuckSupply class is given in Figure 5.8. A puck supply holds the pucks that have not yet been put into play during a Brickles match. OCL for the class is also shown in the figure so you can compare the forms of specification. Figure 5.8. The PuckSupply class's state transition diagram and OCL specification
We can use the same general approach to generating test cases that we described for using pre- and postconditions. Each transition on the diagram represents a requirement for one or more test cases. The diagram in Figure 5.8 has six transitions between states, one transition representing construction, and two representing destruction nine transitions total.[5] Thus, we have nine requirements for test cases. We satisfy these requirements by selecting representative values and boundary values on each side of a transition. If a transition is guarded, then you should select boundary values for the guard condition, too.
Boundary values for states are determined based on the range of attribute values associated with a state. Each state is defined in terms of attribute values. In PuckSupply, the Empty state is associated with a size attribute value of zero. The Not Empty state is associated with a nonzero size attribute value. We want to be sure to include a test case to check that a PuckSupply instance does not behave as though it is empty when its size is one. For most of us, generating test cases from state transition diagrams is more intuitive than generating them from pre- and postconditions. The behavior associated with a class is more evident from the diagrams, and it is easy to identify the requirements for test cases since they come directly from the transitions. However, we must be careful to understand completely the way states are defined in terms of attribute values, and how events affect specific values within a given state. Consider, for example, the Not Empty state in PuckSupply. From the diagram alone, we are left to guess that each time a puck is removed, the size decreases by one. This is explicit in the OCL specification. At the extreme, consider Velocity, which has only one state and twelve transitions. It is difficult to identify all test cases from that simple diagram alone. When testing based on state transition diagrams, make sure you investigate the boundaries and results of each transition as you generate test cases. Adequacy of Test Suites for a ClassIdeally, we could exhaustively test every class, that is, test with all possible values to ensure each class meets its specification. In practice, exhaustive testing is either impossible or requires considerable effort. Nonetheless, it is wise to exhaustively test certain classes. Consider, for example, the Velocity class in Brickles. If it does not operate correctly, the system has no chance of operating correctly. The benefits of exhaustive testing in this case outweigh the cost of writing a test driver to run more test cases. Exhaustive testing is usually infeasible or impractical under time and resource constraints, so we need to test a class enough. Without exhaustive testing, we cannot be sure every aspect of a class meets its specification, but we can apply some measure of adequacy to give us a high level of confidence in the quality of the test suite. Three commonly used measures of adequacy are state-based coverage, constraint-based coverage, and code-based coverage. Meeting these measures minimally will result in different test suites. Using all three measures for a test suite will improve the level of confidence in testing adequately. State-Based CoverageState-based coverage is based on how many of the transitions in a state transition diagram are covered by the test suite. If one or more transitions is not covered, then the class has not been tested adequately and more test cases should be generated to cover those transitions. If test cases are generated from a state transition diagram as we described, then the test cases achieve this measure. If test cases were generated from pre- and postconditions, then analyzing the test cases in terms of which transitions they cover is quite useful for finding missed test cases.
Even if all transitions are covered once, adequate testing is doubtful because states usually embrace a range of values for various object attributes. We need to test values over those ranges. Testing is needed for typical values and boundary values. We must also be concerned about how operations interact with respect to transitions. If there are two transitions T1 and T2 into a state and one transition T3 out of a state, then the test cases for T3 might pass when the input state is set up using T1, but not when T2 is used. We can address this problem using a measure of adequacy based on coverage of all pairs of transitions in the state transition diagram. In our example, we would test the combinations of T1-T3 and T2-T3. Constraint-Based CoverageParallel to adequacy based on state transitions, we can express adequacy in terms of how many pairs of pre- and postconditions have been covered. If for example, the preconditions for an operation are pre1 or pre2 and the postconditions are post1 or post2, then we make sure the test suite contains cases for all the valid combinations pre1=true, pre2=false, post1=true, post2=false; pre1=false, pre2=true, post1=true, post2=false, and so on. Recall the steps we described earlier for finding test case requirements when generating test cases from pre- and postconditions. If one test case is generated to satisfy each requirement, then the test suite meets this measure of adequacy. In a way similar to what we described for using pair-wise sequences of transitions in state-based coverage, we can use sequences of operations based on analysis of preconditions and postconditions. For each operation op that is not an accessor, identify the operators op1, op2, and so on, for which the preconditions are met when the postconditions for op hold. Then execute the test cases for op-op1, op-op2, and so on. Code-Based CoverageA third measure of adequacy can be based on how much of the code that implements the class is executed across all test cases in the suite. It is a good idea to determine that every line of (or path through) the code implementing a class was executed at least once when all test cases have completed execution. Tools for making such measurements are available commercially. If certain lines of code (or paths) have not been reached, then the test suite needs to be expanded with test cases that do reach those lines (paths) or the code needs to be corrected to remove unreachable lines. Even with full code coverage, the test suite for a class might not be adequate because it might not exercise interactions between methods as we described in state-based and constraint-based coverage. Use of one of those other metrics to determine adequacy is important. However, measuring in terms of code coverage is also important (see sidebar). One implementation-level technique for determining the adequacy of a test suite is measuring code coverage for sequences of operations. If all statements (paths) are not executed, generate more test cases to reach them.
| ||||||||||||||||||||






EAN: 2147483647
Pages: 126