| User interface components must contain all the information necessary to create and process the view and may also include methods for interacting with the controller and model functions. Definition of the following may be required to create a user interface component: Acquire and display data. Recognize and interpret events triggered by both users and the system. Filter actions based upon the context. Prevent triggering transactions outside the specified events. Validate user inputs. Maintain reference of the state with the controller. Maintain reference of the state with the model and update display when the model changes. Implement local caching. Implement features for pagination when dealing with long lists. Implement functions that create and interact with variables. Implement interaction with utility classes to provide functions such as undo, clipboard, and business functions (e.g., add total). Can encapsulate both the view and the controller functionality.
Since the users of the system interact and manipulate the interface components directly, it is critical that they support the necessary usability attributes. Following are some user-interaction and display-related design considerations: Interaction with the component is easy to understand. Visual assistance is available as necessary to the user. Erroneous inputs are prevented at an element level. Mandatory and valid data input are validated. Mapping among data elements is contained in the model with user-friendly terms appropriate for display. Values for display (such as date, currency, and other formatting) are formatted. Any localization work on the rendered data (for example, using resource strings to display column headers in a grid in the appropriate language for the user's locale) is performed. Users are provided with status information by indicating, for example, when an application is working in "disconnected" or "connected" mode. Appearance of the application is customized according to user preferences or the kind of client device used.
Internet Browser User Interfaces Canaxia's retail application requires a Web-based user interface so that customers can browse the catalogue and place orders via the Internet. Web-based user interfaces allow for standards-based user interfaces across many devices (such as Internet browsers, WAP browsers on cell phones, and PDAs) and platforms (such as Microsoft Windows, Solaris, Linux, and Macintosh). This is very useful for extending the reach to the maximum within Canaxia's customer base. Most user interfaces in Web-based applications require a dynamic page creation technology, such as ASP.NET, JSP, Cold Fusion, and so on. Even within the dynamic page creation, the applications can be grouped into two major categories: Template-based pages. The screen consists of a fixed layout of the user interface components. For example, the order screen has a fixed layout in which the order header presents the bill to, ship to, and sold to information, which is followed by the list of the products ordered, which is followed by pricing details. Individual orders may contain different information, but all follow the same structure or template. Rule-based pages. The screen is created based upon rules and previous user input. For example, a product locator feature solicits user input and then guides users through a series of screens, with each screen filtering the product choices progressively. Since the product attributes are large especially when combined with user preferences and their relationships with other products the choices quickly multiply and make it difficult to capture all possible combinations in any template-based pages. In such cases, the complete user interface definition is maintained in a rules set that is applied as users interact with the system to create the dynamic rule-based pages.
When you need to implement an application for a browser, you need to use several rich features offered by the technology of choice. The reason to move intelligence to the browser in a Web-based application is to reduce the to-and fro-traffic between the browser and the Web server. This is usually done by moving some processing to the browser be it validation or parsing of the dynamic page (as in XML/XSLT, Extensible Markup Language/Extensible Stylesheet Language Transformation, in some recent browsers) or using DHTML (Dynamic Hyper Text Markup Language) to increase object manipulation in the browser's DOM (Domain Object Model). Following are some design considerations while architecting the browser application: Implementation of a validation framework is generally done using JavaScript and DHTML at the browser. In general, two types of validation are used for entered information. Field validation is the domain of the UI layer. It ensures that you entered a valid date, spelled the group message correctly, selected an employee only from the combo box, and so on. Data validation, on the other hand, is the domain of the business layer. It ensures that you didn't try to assign someone to a category for which they are unqualified or to ship a thousand widgets to a company that only uses sprockets (Burrows 2000). For performance and other reasons, you may wish at times to move some data validation to the client, but you must remember that the primary responsibility of this function still remains in the business logic tiers. Sometimes a JavaScript object is dynamically created and sent to the browser when the business logic object is accessed in the business tiers. This allows you to maintain the business logic in one place and to move intelligence to the client. With the increase in adoption of DHTML, browser-based applications are witnessing richer GUI. The basic HTML-form objects are not sufficient to create the necessary experience. Web application authors are creating custom controls. If you are creating Web user controls, expose only the public properties and methods that you actually need. This improves maintainability. Implement your controller functions as separate functions that will be deployed with your Web pages. Use a component to view state, to store page-specific state, and keep session and application state for data with a wider scope. This approach makes it easier to maintain and improves scalability. Your controller functions should invoke the actions on a user process component to guide the user through the current task, rather than redirecting the user directly to the page. Implement a custom error page and a global exception handler. This provides you with a catchall exception function that prevents the user from seeing unfriendly pages in case of a problem.
Mobile Device User Interfaces With the increasing popularity of handheld PCs, Wireless Application Protocol (WAP) phones, and iMode devices, Canaxia recently opened access to the retail application to such devices. In concept, Canaxia adopted a popular WAP network architecture with the intention to reuse as much of the existing browser-based solution as possible. In general, a user interface for a mobile device needs to be able to display information on a much smaller screen than can other common applications, and it must offer acceptable usability for the devices being targeted. Because user interaction can be awkward on many mobile devices, particularly mobile phones, you should design your mobile user interfaces with minimal data input requirements. A common strategy is to combine the use of mobile devices with a fat-client or a browser-based application. The user can preregister data through the fat-client or the browser-based application and then select that data when using the mobile client. For example, in Canaxia's retail application, users register credit card details through the Web site, so that a preregistered credit card can be selected from a list when orders are placed from a mobile device. Figure 9-5 illustrates the mobile access architecture. This architecture uses the current browser-based GUI definition to extend it to the mobile devices. In the architecture, the GUI manager and the device manager are the two key presentation tier components responsible for creating the user interface for the mobile devices. The former component has the responsibility for mapping the screen-specific entities and information from the browser-based GUI to the display possibilities of the mobile device and the latter informing it about the device capabilities so that it can appropriately package the GUI code. Figure 9-5. Mobile access architecture. 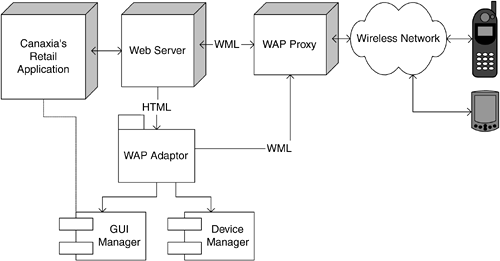
Given the limitations of the mobile devices, the mobile presentation tier strategy offers two basic choices: Create a new GUI manager component for mobile devices. This approach has the maintenance overhead of changing the GUI manager code when the basic application GUI needs to change and when a new device type is introduced. Adopt model-driven architecture for creating a platform-independent model for the complete presentation tier code. User Interface Markup Language (UIML) is an emerging language that captures the complete user interface definition, using a UML-derived notation. The GUI code is generated (potentially dynamically) and deployed from the model based upon the device profile and the technology choices.
Fat-client User Interfaces There are three main reasons for adopting a fat-client user interface. You may wish to provide a persistent connection with the back-end system, to provide users with options of doing a large chunk of work in the offline mode (locally on their computers), or to provide a rich user interaction. With fat-client user interfaces, the user interface components are typically installed on the user's local computer. This leads to maintenance overheads, as the application needs to be reinstalled with every change to the client. The following deployment strategies have become popular recently: Download the application from a central server and check for newer versions when the users log on. Install patches and version upgrades in this manner. This may follow a pull paradigm in which the software is downloaded on explicit user request or a push paradigm where the software is downloaded automatically when the user is online. Provide architecture for the client, in two parts, in which the part that needs to change infrequently is installed on the user's local computer and the part that can change frequently is downloaded when the user connects to the central server. In download on demand, another option, the software is downloaded and installed only for users who need that functionality and when they need it.
The technology choice for authoring the fat-client is based upon the requirement for deploying the software. Some technologies, such as JAVA, make it possible to create the application user interfaces that can run on any operating system. Others, such as Microsoft Windows, XMotif, and SystemX user interfaces can only run in a certain environment. They can, however, take advantage of a wide range of state management and persistence options and can access local processing power of the native operating system and the computer. Following are the four main types of fat-client user interfaces: In a full-blown fat-client user interface, all the client-side code is contained and installed on the user's local computer. This makes it possible to use the processing power of the user's computer to create the display. A richer interface and a highly interactive user interface can be offered in this paradigm. This may tie you to a client platform, and the application needs to be deployed to the users (even if the application is deployed by downloading it over an HTTP connection). You can use additional embedded HTML in your fat-client applications. Embedded HTML allows for greater run-time flexibility (because the HTML may be loaded from external resources or even a database in connected scenarios) and user customization. Embed a fat-client within an HTML page. This is done frequently using applets in the Java paradigm, ActiveX in the Microsoft paradigm, or third-party plug-ins, such as Macromedia Flash. Such plug-ins can provide an interface as rich as the full-blown fat-client, but they require a browser and some locally and successfully installed run-time environment on the user's local computer. Extend an existing application's features by using your application as a plug-in. This allows you to use all the existing framework of the native application.
Key design considerations for a fat-client include the following: Maintain state information across several concurrent displays. Changing the state in one instance can automatically change the display in another window. This is particularly useful if one is working with multiple views of the same data source and it is accomplished by data binding to keep the views synchronized. Design the user interface components to promote reuse. The reuse can happen at the individual screen or screen element level, at a set of screens that may include the dependent relationships of one parent screen with the child screens level, and at the set of screens that orchestrate a user-interface process level. Implement frameworks for client-side validation and for creating user-friendly nomenclature for display to the users. If you are creating custom user controls, expose only the public properties and methods that you actually need. This improves maintainability. Implement your controller functions as separate functions that will be deployed with your client. Use a component to view state, to store screen-specific state, and to keep session and application state for data with a wider scope. This approach makes it easier to maintain and improves scalability. Your controller functions should invoke the actions on a user process component to guide the user through the current task rather than redirecting the user to the page directly. Implement a custom error page and a global exception handler. This provides you with a catchall exception function that prevents the user from seeing unfriendly pages in case of a problem.
Document-Based User Interfaces As Canaxia demonstrates, some users not only are familiar with document-based tools but also find them easy to use. In the retail example, the back-office clerk works with a wide variety of Excel documents, and it is convenient for them to prepare orders and then upload them to the retail application for further processing. Users often are more comfortable working with documents that reflect their real lives than they are with the form-based user interface provided by an application. For example, the accounting world relies extensively on spreadsheet-based applications such as Microsoft Excel, and most interaction among people is via word-processed documents, such as those produced in Microsoft Word. You may also need solutions that require interaction with documents that are created and often maintained outside your application. Consider the following document-based solutions: Reporting data. Your application (Windows- or Web-based) may provide users with a feature that lets them see data in a document of the appropriate type for example, showing invoice data as a Word document or a price list as an Excel spreadsheet. Additionally, these documents may require displaying information collected from various others for example, address for ship-to information that is maintained in your customer relationship management (CRM) system. Gathering data. You could let sales representatives enter purchase information for telephone customers in Excel spreadsheets to create a customer order document and then submit the document to your business process. Now the Excel spreadsheet may contain macros that perform several application functions, such as validations, calculations, and formatting that could potentially reduce processing overheads from your applications. Synchronized data. Sometimes these documents have direct connectivity with your back-end systems and provide a two-way interaction and manipulation of the model from the context of the document.
Designing User Interface Process Components As presented previously in this chapter, user interface process components are the other key presentation tier piece that is responsible for providing the interaction to your application. Whether you are providing users the ability to interact with screen elements or widgets, with a complete screen, or with a collection of screens that are connected in some logical way, this piece of functionality is referred to as the controller (in the MVC paradigm, also discussed previously in this chapter). The user interface process component is typically implemented as a separate JAVA, .NET, or similar class. Sometimes this component may be bundled with the user interface components, but it is usually a good practice to keep it separate. Sometimes the process component is dynamically generated from the model. This is useful when this component is providing a business process like functionality, spans several user interfaces such as those needed by different devices, or needs to generate a dynamic application interaction paradigm. For example, in the Canaxia retail application, users are required to enter product details, view the total price, enter payment details, and enter delivery address information. This process involves displaying and accepting input from a number of user interface elements, and the state for the process (which products have been ordered, the credit card details, and so on) must be maintained between each transition from one step in the process to another. To help coordinate the user process and handle the state management required when displaying multiple user interface pages or forms, you can create user process components. (Note: Implementing a user interaction with user process components is not a trivial task.) The user interface component typically provides an interface to trigger the process component. For example, the Show Order button can trigger the controller component to interact with the model to create a view for displaying the list of products within the order. To increase the reusability of the component, it is advisable not to index a screen directly but to use the metadata to reference the display. Doing this will, as in the preceding example, allow reuse of the same component for displaying the list of products from the invoice screen. Designing user process components from multiple user interfaces will result in a more complex implementation and will isolate device-specific issues. Separating the user interaction functionality into user interface and user interface process components allows the long-running user interaction state to be more easily persisted, thus allowing a user interaction to be abandoned and resumed, possibly even using a different user interface. For example, a customer could add some items to a shopping cart using the Web-based user interface and later call a sales representative to complete the order using the fat-client interface. An unstructured approach to designing user interface logic may result in undesirable situations as the size of the application grows or new requirements are introduced. If you need to add a specific user interface for a given device, you may need to redesign the data flow and control logic. Partitioning the user interaction flow from the activities of rendering data and gathering data from the user can increase your application's maintainability and provide a clean design to which you can easily add seemingly complex features, such as support for offline work. Let us use the Canaxia retail application example to illustrate the three key user interface design issues that are resolved by the process component. Figure 9-6 illustrates the three interaction issues: Handling concurrent user activities. Some applications may allow users to perform multiple tasks simultaneously by making more than one user interface element available. For example, a Windows-based application may display multiple forms, or a Web application may open a second browser window. User process components simplify the state management of multiple ongoing processes by encapsulating all the state needed for the process in a single component. You can map each user interface element to a particular instance of the user process by incorporating a custom process identifier into your design. Using multiple panes for one activity. If multiple windows or panes are used in a particular user activity, it is important to keep them synchronized. In a Web application, a user interface usually displays a set of elements on the same page (which may include frames) for a given user activity. However, in rich client applications, you may actually have many nonmodal windows affecting just one particular process. For example, you may have a product category selector window floating in your application that lets you specify a particular category, in which the products will be displayed in another window. User process components help you to implement this kind of user interface by centralizing the state for all windows in a single location. You can further simplify synchronization across multiple user interface elements by using data bindable formats for state data. Isolating long-running user activities from business-related state. Some user processes can be paused and resumed later. The intermediate state of the user process should generally be stored separately from the application's business data. For example, a user could specify some of the information required to place an order and then resume the checkout process at a later time. The pending order data should be persisted separately from the data relating to completed orders, allowing you to perform business operations on completed order data (for example, counting the number of orders placed in the current month) without having to implement complex filtering rules to avoid operating on incomplete orders.
Figure 9-6. User interface process components. 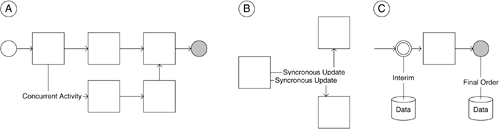
User activities, just like business processes, may have a time-out specified, when the activity has to be cancelled and the right compensatory actions should be taken on the business process. You can design your user process components to be serializable or to store states separately from the application's business data. Separating User Process from User Interface To separate a user process from the user interface, use the following steps: Identify the business process or processes that the user interface process will help to accomplish. Identify how the user sees this as a task (you can usually do this by consulting the sequence diagrams you created as part of your requirements analysis). Identify the data needed by the business processes. The user process must submit this data when necessary. Identify any additional state you will need to maintain throughout the user activity to assist rendering and data capture in the user interface. Design the visual flow of the user process and the way each user interface element receives or gives control flow. You must also implement code to map a particular user interface session to the related user process: A Web UI will have to obtain the information about the current user process by getting a reference from the session object or another storage medium, such as a database. You will need this reference in event handlers for the controls on your Web page. Your windows or controls must refer to the current user process component. You can keep this reference in a member variable. However, you should not keep it in a global variable because, if you do, composing user interfaces will become very complicated as your application user interface grows.
User Process Component Functionality User process components include the following: Provide a simple way to combine user interface elements into user interaction flows without requiring you to redevelop data flow and control logic. Separate the conceptual user interaction flow from the implementation or device where it occurs. Encapsulate how exceptions may affect the user process flow. Track the current state of the user interaction. Do not start or participate in transactions. They keep internal data related to application business logic and their internal state, persisting the data as required. Maintain an internal business-related state, usually holding on to one or more business entities that are affected by the user interaction. You may keep multiple entities in private variables or in an internal array or appropriate collection type. May provide a "save and continue later" feature by which a particular user interaction may be restarted in another session. You may implement this functionality by saving the internal state of the user process component in some persistent form and providing the user with a way to continue a particular activity later. You can create a custom task manager utility component to control the current activation state of the process.
The user process state may be stored in one of the following places: If the user process can be continued from other devices or computers, you must store it centrally, such as in a database. If you are running in a disconnected environment, you must store the user process state locally on the user device. If your user interface process is running in a Web farm, you must store any required state on a central server so that it can be continued from any server in the farm. The internal state may be initialized by calling a business process component or data access logic components. Typically, the user process state will not be stored as enterprise services components. The only reason to do so would be to use the enterprise services role-based authorization capabilities. The user process may be started by a custom utility component that manages the menus in your application.
General Recommendations for User Process Components When designing user process components, consider the following recommendations: Decide whether you need to manage user processes as components that are separate from your user interface implementation. Separate user processes are most needed in applications with a high number of user interface dialog boxes or in applications in which the user processes may be subject to customization and may benefit from a plug-in approach. Choose where to store the state of the user process. If the process is running in a connected fashion, store interim state for long-running processes in a central database; in disconnected scenarios, store it in local XML files, isolated storage, or local databases. If the process is not long running and does not need to be recovered if a problem occurs, you should persist the state in memory. For user interfaces built for rich clients, you may want to keep the state in memory. For Web applications, you may choose to store the user process state in the session object. Design your user process components so that they may be serialized. This will help you implement any persistence scheme. Include exception handling in user process components and propagate exceptions to the user interface. Exceptions that are thrown by the user process components should be caught by user interface components and published.
Accessing Data Access Logic Components from the UI Some applications' user interfaces need to render data that are readily available as queries exposed by data access logic components. Regardless of whether or not your user interface components invoke data access logic components directly, you should not mix data access logic with business processing logic. Accessing data access logic components directly from your UI may seem to contradict the layering concept. However, it is useful in this case to adopt the perspective of your application as one homogenous service you call it, and it's up to it to decide what internal components are best suited to respond to a request. You should allow direct data access logic component access to user interface components in the following instances: You are willing to tightly couple data access methods and schemas with user interface semantics. This coupling requires joint maintenance of user interface changes and schema changes. Your physical deployment places data access logic components and user interface components together, allowing you to get data in streaming formats from data access logic components that can be bound directly to the output of the user interfaces for performance. If you deploy data access and business process logic on different servers, you cannot take advantage of this capability. From an operational perspective, allowing direct access to the data access logic components to take advantage of streaming capabilities means that you must provide access to the database from where the data access logic components are deployed possibly including access through firewall ports.
Network Connectivity and Offline Applications In many cases, your application will require support for offline operations when network connectivity is unavailable. For example, many mobile applications, including rich clients for pocket PC or table PC devices, must be functional when the user is disconnected from the corporate network. Offline applications must rely on local data and user process state to perform their work. When designing offline applications, adhere to the following general guidelines. The online and offline status should be displayed to the user. This is usually done in status bars or title bars or with visual cues around user interface elements that require a connection to the server. The development of most of the application user interface should be reusable, with little or no modification needed to support offline scenarios. While offline, your application will not have the following: Access to online data returned by data access logic components. The ability to invoke business processes synchronously. As a result, the application will not know whether the call succeeded or will not be able to use any returned data.
If your application does not implement a fully message-based interface to your servers but relies on synchronously acquiring data and knowing the results of business processes (as most of today's applications do), you should do the following to provide the illusion of connectivity: Implement a local cache for read-only reference data that relates to the user's activities. You can then implement an offline data access logic component that implements exactly the same queries as your server-side data access logic components but accesses local storage. Implement an offline business component that has the same interface as your business components but takes the submitted data and places them in a store-and-forward, reliable messaging system such as message queuing. This offline component may then return nothing or a preset value to its caller. Implement UI functionality that provides a way to inspect the business action outbox and possibly to delete messages in it. If message queuing is used to queue offline messages, you must set the correct permissions on the queue to do this from your application. Design your application's transactions to accommodate message-based UI interactions. You will have to take extra care to manage optimistic locking and the results of transactions based on stale data. A common technique for performing updates is to submit both the old and new data and to let the related business process or data access logic component eventually resolve any conflicts. For business processes, the submission may include critical reference data that the business logic uses to decide whether or not to let the data through. For example, you can include product prices alongside product IDs and quantities when submitting an order.
|