Section 15.3. The UFS Inode
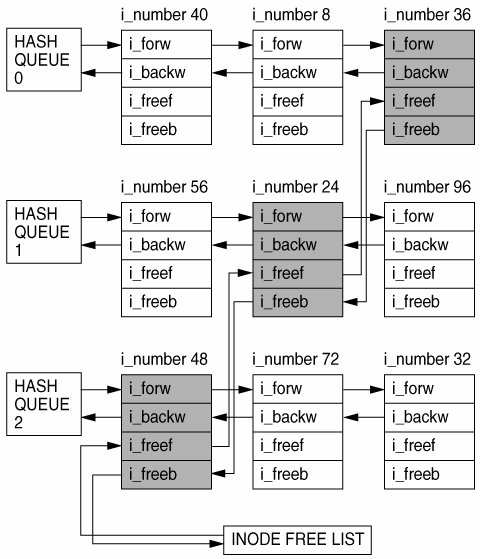
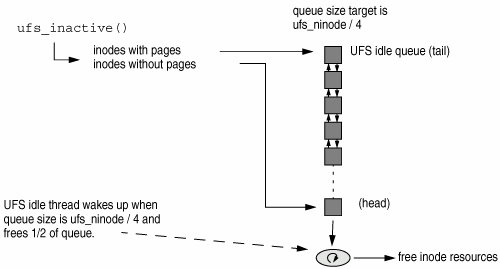
15.3. The UFS InodeThe inode (Index Node) is UFS's internal descriptor for a file. Each file system has two forms of an inode: the on-disk inode and the in-core (in-memory) inode. The on-disk inode resides on the physical medium and represents the on-disk format and layout of the file. 15.3.1. In-Core UFS InodesThe in-core inode, as you may have guessed, resides in memory and contains the file-system-dependent information, free-list pointers, hash anchors, kernel locks (covered in UFS locking below), and inode state. typedef struct inode { struct inode *i_chain[2]; /* must be first */ struct inode *i_freef; /* free list forward - must be before i_ic */ struct inode *i_freeb; /* free list back - must be before i_ic */ struct icommon i_ic; /* Must be here */ struct vnode *i_vnode; /* vnode associated with this inode */ struct vnode *i_devvp; /* vnode for block I/O */ dev_t i_dev; /* device where inode resides */ ino_t i_number; /* i number, 1-to-1 with device address */ off_t i_diroff; /* offset in dir, where we found last entry */ /* just a hint - no locking needed */ struct ufsvfs *i_ufsvfs; /* incore fs associated with inode */ struct dquot *i_dquot; /* quota structure controlling this file */ krwlock_t i_rwlock; /* serializes write/setattr requests */ krwlock_t i_contents; /* protects (most of) inode contents */ kmutex_t i_tlock; /* protects time fields, i_flag */ offset_t i_nextr; /* */ /* next byte read offset (read-ahead) */ /* No lock required */ /* */ uint_t i_flag; /* inode flags */ uint_t i_seq; /* modification sequence number */ boolean_t i_cachedir; /* Cache this directory on next lookup */ /* - no locking needed */ long i_mapcnt; /* mappings to file pages */ int *i_map; /* block list for the corresponding file */ dev_t i_rdev; /* INCORE rdev from i_oldrdev by ufs_iget */ size_t i_delaylen; /* delayed writes, units=bytes */ offset_t i_delayoff; /* where we started delaying */ offset_t i_nextrio; /* where to start the next clust */ long i_writes; /* number of outstanding bytes in write q */ kcondvar_t i_wrcv; /* sleep/wakeup for write throttle */ offset_t i_doff; /* dinode byte offset in file system */ si_t *i_ufs_acl; /* pointer to acl entry */ dcanchor_t i_danchor; /* directory cache anchor */ kthread_t *i_writer; /* thread which is in window in wrip() */ } inode_t; See usr/src/uts/common/sys/fs/ufs_inode.h New with Solaris 10, an inode sequence number was added to the in-core inode structure to support NFSv3 and NFSv4 detection of atomic changes to the inode. Two caveats with this new value: i_seq must be updated if i_ctime and i_mtime are changed; the value of i_seq is only guaranteed to be persistent while the inode is active. 15.3.2. Inode CacheWhen the last reference to a vnode is released, the vop_inactive() routine for the file system is called. (See vnode reference counts in Section 14.6.8.) UFS uses vop_inactive() to free the inode when it is no longer required. If we were to destroy each vnode when the last reference to a vnode is relinquished, we would throw away all the data relating to that vnode, including all the file pages cached in the page cache. This practice could mean that if a file is closed and then reopened, none of the file data that was cached would be available after the second open and would need to be reread from disk. To remedy the situation, UFS caches all unused inodes in its global cache. The UFS inode cache contains an entry for every open inode in the system. It also attempts to keep as many closed inodes as possible so that inactive inodes/ vnodes and associated pages are around in memory for possible reuse. This is a global cache and not a per-file system cache, and that unfortunately leads to several performance issues. The inode cache consists of several disconnected queues or chains, and each queue is linked with the inode's i_forw and i_backw pointers (see Figure 15.10). Starting with Solaris 10, hashing of inode entries is done with the inode number (because of recent devfs changes) rather than with the inode number and the device number (Solaris 9 and earlier). These queues are managed according to least recently used (LRU) scheme. Figure 15.10. UFS Inode Hash Queues An inode free list is also maintained within the cache which is built upon the i_freef and i_freeb pointers. These enable the free list to span several hash chains. If an inode is not on the free list, then the i_freef and i_freeb values point back to the inode itself. Inodes on the free list can be part of two separate queues:
15.3.3. Block AllocationThe UFS file system is block based where each file is represented by a set of fixed sized units of disk space, indexed by a tree of physical-meta-data blocks. 15.3.3.1. Layout PolicyUFS uses block sizes of 4 and 8 Kbytes, which provides significantly higher performance than the 512-byte blocks used in the System V file system. The downside of larger blocks was that when partially allocated blocks were created, several kilo-bytes of disk space for each partly filled file system block was wasted. To overcome this disadvantage, UFS uses the notion of file system fragments. Fragments allow a single block to be broken up into 2, 4, or 8 fragments when necessary (4 Kbytes, 2 Kbytes or 1 Kbyte, respectively). UFS block allocation tries to prevent excessive disk seeking by attempting to co-locate inodes within a directory and by attempting to co-locate a file's inode and its data blocks. When possible, all the inodes in a directory are allocated in the same cylinder group. This scheme helps reduce disk seeking when directories are traversed; for example, executing a simple ls -l of a directory will access all the inodes in that directory. If all the inodes reside in the same cylinder group, most of the data are cached after the first few files are accessed. A directory is placed in a cylinder group different from that of its parent. Blocks are allocated to a file sequentially, starting with the first 96 Kbytes (the first 12 direct blocks), skipping to the next cylinder group and allocating blocks up to the limit set by the file system parameter maxbpg (maximum-blocks-per-cylinder-group). After that, blocks are allocated from the next available cylinder group. By default, on a file system greater than 1 Gbyte, the algorithm allocates 96 Kbytes in the first cylinder group, 16 Mbytes in the next available cylinder group, 16 Mbytes from the next, and so on. The maximum cylinder group size is 54 Mbytes, and the allocation algorithm allows only one-third of that space to be allocated to each section of a single file when it is extended. The maxbpg parameter is set to 2,048 8-Kbyte blocks by default at the time the file system is created. It is also tunable but can only be tuned downward since the maximum cylinder group size is 16-Mybte allocation per cylinder group. Selection of a new cylinder group for the next segment of a file is governed by a rotor and free-space algorithm. A per-file-system allocation rotor points to one of the cylinder groups; each time new disk space is allocated, it starts with the cylinder group pointed to by the rotor. If the cylinder group has less than average free space, then it is skipped and the next cylinder group is tried. This algorithm makes the file system attempt to balance the allocation across the cylinder groups. Figure 15.12 shows the default allocation that is used if a file is created on a large UFS. The first 96 Kbytes of file 1 are allocated from the first cylinder group. Then, allocation skips to the second cylinder group and another 16 Mbytes of file 1 are allocated, and so on. When another file is created, we can see that it consumes the holes in the allocated blocks alongside file 1. There is room for a third file to do the same. Figure 15.12. Default File Allocation in 16-Mbyte Groups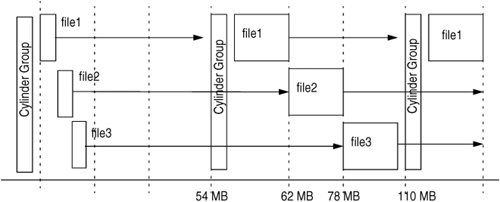 The actual on-disk layout will not be quite as simple as the example shown but does reflect the allocation policies discussed. We can use an add-on tool, filestat, to view the on-disk layout of a file, as shown below. sol8# /usr/local/bin/filestat testfile Inodes per cyl group: 128 Inodes per block: 64 Cylinder Group no: 0 Cylinder Group blk: 64 File System Block Size: 8192 Block Size: 512 Number of 512b Blocks: 262288 Start Block End Block Length (512 byte Blocks) ----------- ----------- ------------------------ 144 -> 335 192 400 -> 33167 32768 110800 -> 143567 32768 221264 -> 221343 80 221216 -> 221263 48 221456 -> 254095 32640 331856 -> 331999 144 331808 -> 331855 48 332112 -> 364687 32576 442448 -> 442655 208 442400 -> 442447 48 442768 -> 475279 32512 The filestat output shows that the first segment of the file occupies 192 (512-byte) blocks, followed by the next 16 Mbytes, which start in a different cylinder group. This particular file system was not empty when the file was created, which is why the next cylinder group chosen is a long way from the first. We can observe the file system parameters of an existing file system with the fstyp command. The fstyp command simply dumps the superblock information for the file, revealing all the cylinder group and allocation information. The following example shows the output for a 4-Gbyte file system with default parameters. We can see that the file system has 8,247,421 blocks and has 167 cylinder groups spaced evenly at 6,272 (51-Mbyte) intervals. The maximum blocks to allocate for each group is set to the default of 2,048 8-Kbyte, 16 Mbytes. sol8# fstyp -v /dev/vx/dsk/homevol |more ufs magic 11954 format dynamic time Sat Mar 6 18:19:59 1999 sblkno 16 cblkno 24 iblkno 32 dblkno 800 sbsize 2048 cgsize 8192 cgoffset 32 cgmask 0xffffffe0 ncg 167 size 8378368 blocks 8247421 bsize 8192 shift 13 mask 0xffffe000 fsize 1024 shift 10 mask 0xfffffc00 frag 8 shift 3 fsbtodb 1 minfree 1% maxbpg 2048 optim time maxcontig 32 rotdelay 0ms rps 120 csaddr 800 cssize 3072 shift 9 mask 0xfffffe00 ntrak 32 nsect 64 spc 2048 ncyl 8182 cpg 49 bpg 6272 fpg 50176 ipg 6144 nindir 2048 inopb 64 nspf 2 nbfree 176719 ndir 10241 nifree 956753 nffree 21495 cgrotor 152 fmod 0 ronly 0 logbno 0 The UFS-specific version of the fstyp command dumps the superblock of a UFS file system, as shown below. sol8# fstyp -v /dev/vx/dsk/homevol |more ufs magic 11954 format dynamic time Sat Mar 6 18:19:59 1999 sblkno 16 cblkno 24 iblkno 32 dblkno 800 sbsize 2048 cgsize 8192 cgoffset 32 cgmask 0xffffffe0 ncg 167 size 8378368 blocks 8247421 bsize 8192 shift 13 mask 0xffffe000 fsize 1024 shift 10 mask 0xfffffc00 frag 8 shift 3 fsbtodb 1 minfree 1% maxbpg 2048 optim time maxcontig 32 rotdelay 0ms rps 120 csaddr 800 cssize 3072 shift 9 mask 0xfffffe00 ntrak 32 nsect 64 spc 2048 ncyl 8182 cpg 49 bpg 6272 fpg 50176 ipg 6144 nindir 2048 inopb 64 nspf 2 nbfree 176719 ndir 10241 nifree 956753 nffree 21495 cgrotor 152 fmod 0 ronly 0 logbno 0 fs_reclaim is not set file system state is valid, fsclean is 0 blocks available in each rotational position cylinder number 0: position 0: 0 4 8 12 16 20 24 28 32 36 40 44 48 52 56 60 64 68 72 76 80 84 88 92 96 100 104 108 112 116 120 124 position 2: 1 5 9 13 17 21 25 29 33 37 41 45 49 53 57 61 65 69 73 77 81 85 89 93 97 101 105 109 113 117 121 125 position 4: 2 6 10 14 18 22 26 30 34 38 42 46 50 54 58 62 66 70 74 78 82 86 90 94 98 102 106 110 114 118 122 126 position 6: 3 7 11 15 19 23 27 31 35 39 43 47 51 55 59 63 67 71 75 79 83 87 91 95 99 103 107 111 115 119 123 127 cs[].cs_(nbfree,ndir,nifree,nffree): (23,26,5708,102) (142,26,5724,244) (87,20,5725,132) (390,69,5737,80) (72,87,5815,148) (3,87,5761,110) (267,87,5784,4) (0,66,5434,4) (217,46,5606,94) (537,87,5789,70) (0,87,5901,68) (0,87,5752,20) . . cylinders in last group 48 blocks in last group 6144 cg 0: magic 90255 tell 6000 time Sat Feb 27 22:53:11 1999 cgx 0 ncyl 49 niblk 6144 ndblk 50176 nbfree 23 ndir 26 nifree 5708 nffree 102 rotor 1224 irotor 144 frotor 1224 frsum 7 7 3 1 1 0 9 sum of frsum: 102 iused: 0-143, 145-436 free: 1224-1295, 1304-1311, 1328-1343, 4054-4055, 4126-4127, 4446-4447, 4455, 4637- 4638, 15.3.3.2. Mapping Files to Disk BlocksAt the heart of a disk-based file system are the block map algorithms, which implement the on-disk file system format. These algorithms map UFS file and offsets pairs into disk addresses on the underlying storage. For UFS, two main functionsbmap_read() and bmap_write()implement the on-disk format. Calling these functions has the following results:
int bmap_read(struct inode *ip, u_offset_t off, daddr_t *dap, int *lenp) See usr/src/uts/common/fs/ufs/ufs_bmap.c The file system uses the bmap_read() algorithm to locate the physical blocks for the file being read. The bmap_read() function searches through the direct, indirect, and double-indirect blocks of the inode to locate the disk address of the disk blocks that map to the supplied offset. The function also searches forward from the offset, looking for disk blocks that continue to map contiguous portions of the inode, and returns the length of the contiguous segment (in blocks) in the length pointer argument. The length and the file system block clustering parameters are used within the file system as bounds for clustering contiguous blocks to provide better performance by reading larger parts of a file from disk at a time. See ufs_getpage_ra(), defined in usr/src/uts/common/fs/ufs_vnops.c, for more information on read-aheads. int bmap_write(struct inode *ip, u_offset_t off, int size, int alloc_only, struct cred *cr); See usr/src/uts/common/fs/ufs/ufs_bmap.c The bmap_write() function allocates file space in the file system when a file is extended or a file with holes has blocks written for the first time and is responsible for storing the allocated block information in the inode. bmap_write() traverses the block free lists, using the rotor algorithm (discussed in Section 15.3.3), and updates the local, direct, and indirect blocks in the inode for the file being extended. bmap_write calls several helper functions to facilitate the allocation of blocks. daddr_t blkpref(struct inode *ip, daddr_t lbn, int indx, daddr32_t *bap) Guides bmap_write in selecting the next desired block in the file. Sets the policy as described in Section 15.3.3.1. int realloccg(struct inode *ip, daddr_t bprev, daddr_t bpref, int osize, int nsize, daddr_t *bnp, cred_t *cr) Re-allocates a fragment to a bigger size. The number and size of the old block size is specified and the allocator attempts to extend the original block. Failing that, the regular block allocator is called to obtain an appropriate block. int alloc(struct inode *ip, daddr_t bpref, int size, daddr_t *bnp, cred_t *cr) Allocates a block in the file system. The size of the block is specified which is a multiple of (fs_fsize <= fs_bsize). If a preference (usually obtained from blkpref()) is specified, the allocator will try to allocate the requested block. If that fails, a rotationally optimal block in the same cylinder is found. Failing that a block in the same cylinder group is searched for. And in case that fails, the allocator quadratically rehashes into other cylinder groups (see hashalloc() in uts/common/fs/ufs/ufs_alloc.c) to locate an available block. If no preference is given, a block in the same cylinder is found, and failing that the allocator quadratically searches other cylinder groups for one. See uts/common/fs/ufs/ufs_alloc.c static void ufs_undo_allocation(inode_t *ip, int block_count, struct ufs_allocated_block table[], int inode_sector_adjust) In the case of an error, bmap_write() will call ufs_undo_allocation to free any blocks which were used during the allocation process. See uts/common/fs/ufs/ufs_bmap.c 15.3.3.3. Reading and Writing UFS BlocksA file system read calls bmap_read() to find the location of the underlying physical blocks for the file being read. UFS then calls the device driver's strategy routine for the device containing the file system to initiate the read operation by calling bdev_strategy(). A file system write operation that extends a file first calls bmap_write() to allocate the new blocks and then calls bmap_read() to obtain the block location for the write. UFS then calls the device driver's strategy routine, by means of bdev_strategy(), to initiate the file write. 15.3.3.4. Buffering Block MetadataThe block map functions access metadata (single, double and triple indirect blocks) on the device media through the buffer cache, using the bread_common() and bwrite_common() buffered block I/O kernel functions. The block I/O functions read and write device blocks in 512-byte chunks, and they cache physical disk blocks in the block buffer cache (note: this cache is different from the page cache, used for file data). The UFS file system requires 1 Mbyte of metadata for every 2 Gbytes of file space. This relationship can be used as a rule to calculate the size of the block buffer cache, set by the bufhwm kernel parameter. 15.3.4. Methods to Read and Write UFS FilesFiles can be read or written in two ways: by the read() or write() system calls or by mapped file I/O. The read() and write() system calls call the file system's ufs_read() and ufs_write() method. These methods map files into the kernel's address space and then use the file system's ufs_getpage() and ufs_putpage() methods to transfer data to and from the physical media. 15.3.4.1. ufs_read()An example of the steps taken by a UFS read system call is shown in Figure 15.13. A read system call invokes the file-system-dependent read function, which turns the read request into a series of vop_getpage() calls by mapping the file into the kernel's address space with the seg_kpm driver (through the seg_map driver), as described in Section 14.7. Figure 15.13. ufs_read() The ufs_read method calls into the seg_map driver to locate a virtual address in the kernel address space for the file and offset requested with the segmap_getmapflt() function. The seg_map driver determines whether it already has a mapping for the requested offset by looking into its hashed list of mapping slots. Once a slot is located or created, an address for the page is located. segmap then calls back into the file system with ufs_getpage() to soft-initiate a page fault to read in the page at the virtual address of the seg_map slot. The page fault is initiated while we are still in the segmap_getmap() routine, by a call to segmap_fault(). That function in turn calls back into the file system with ufs_getpage(), which calls out file system's _getpage(). If not, then a slot is created and ufs_getpage() is called to read in the pages. The ufs_getpage() routine brings the requested range of the file (vnode, offset, and length) from disk into the virtual address, and the length is passed into the ufs_getpage() function. The ufs_getpage() function locates the file's blocks (through the block map functions discussed in Section 15.3.3.2) and reads them by calling the underlying device's strategy routine. Once the page is read by the file system, the requested range is copied back to the user by the uiomove() function. The file system then releases the slot associated with that block of the file by using the segmap_release() function. At this point, the slot is not removed from the segment, because we may need the same file and offset later (effectively caching the virtual address location); instead, it is added to a seg_map free list so that it can be reclaimed or reused later. 15.3.4.2. ufs_write()Writing to the file system is performed similarly, although it is more complex because of some of the file system write performance enhancements, such as delayed writes and write clustering. Writing to the file system follows the steps shown in Figure 15.14. Figure 15.14. ufs_write()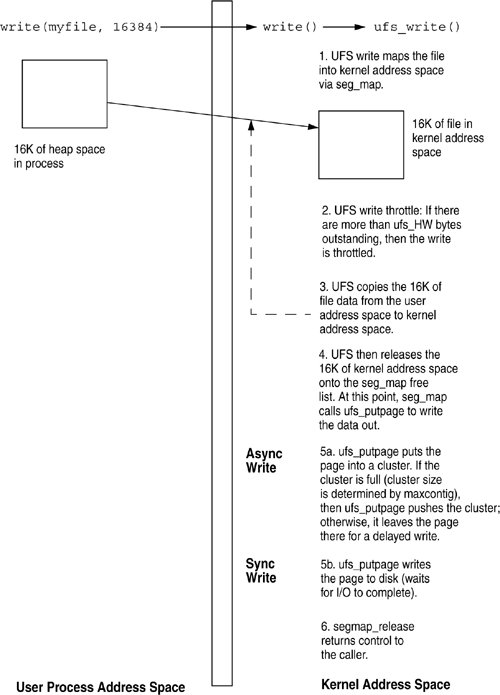 The write system call calls the file-system-independent write, which in our example calls ufs_write(). UFS breaks the write into 8-Kbyte chunks and then processes each chunk. For each 8-Kbyte chunk, the following steps are performed.
The file system calls the seg_map driver to map in the portion of the file we are going to write. The data is copied from the process's user address space into the kernel address space allocated by seg_map, and seg_map is then called to release the address space containing the dirty pages to be written. This is when the real work of write starts, because seg_map calls ufs_putpage() when it realizes there are dirty pages in the address space it is releasing. |
EAN: 2147483647
Pages: 244
- Assessing Business-IT Alignment Maturity
- Measuring and Managing E-Business Initiatives Through the Balanced Scorecard
- A View on Knowledge Management: Utilizing a Balanced Scorecard Methodology for Analyzing Knowledge Metrics
- Technical Issues Related to IT Governance Tactics: Product Metrics, Measurements and Process Control
- Governance in IT Outsourcing Partnerships