Section 14.2. Process-Level File Abstractions
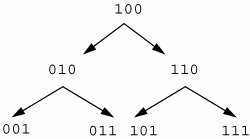
14.2. Process-Level File AbstractionsWithin a process, a file is referenced through a file descriptor. An integer space of file descriptors per process is shared by multiple threads within each process. A file descriptor is a value in an integer space. It is assigned when a file is first opened and freed when a file is closed. Each process has a list of active file descriptors, which are an index into a per-process file table. Each file table entry holds process-specific data including the current file's seek offset and has a reference to a systemwide virtual file node (vnode). The list of open file descriptors is kept inside a process's user area (struct user) in an fi_list array indexed by the file descriptor number. The fi_list is an array of uf_entry_t structures, each with its own lock and a pointer to the corresponding file_t file table entry. Although multiple file table entries might reference the same file, there is a single vnode entry, as Figure 14.2 highlights. The vnode holds systemwide information about a file, including its type, size, and containing file system. Figure 14.2. Structures Used for File Access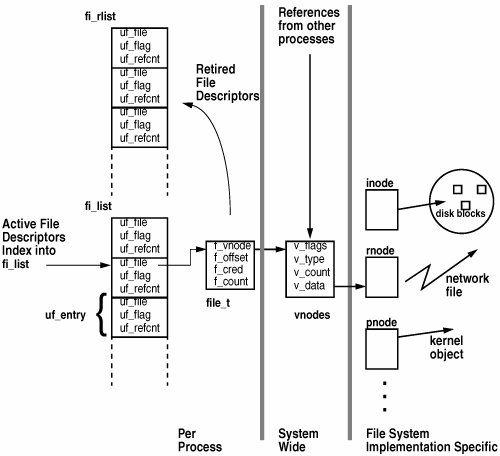 14.2.1. File DescriptorsA file descriptor is a non-negative integer that is returned from the system calls open(), fcntl(), pipe(), or dup(). A process uses the file descriptor on other system calls, such as read() and write(), that perform operations on open files. Each file descriptor is represented by a uf_entry_t, shown below, and the file descriptor is used as an index into an array of uf_entry_t enTRies. /* * Entry in the per-process list of open files. * Note: only certain fields are copied in flist_grow() and flist_fork(). * This is indicated in brackets in the structure member comments. */ typedef struct uf_entry { kmutex_t uf_lock; /* per-fd lock [never copied] */ struct file *uf_file; /* file pointer [grow, fork] */ struct fpollinfo *uf_fpollinfo; /* poll state [grow] */ int uf_refcnt; /* LWPs accessing this file [grow] */ int uf_alloc; /* right subtree allocs [grow, fork] */ short uf_flag; /* fcntl F_GETFD flags [grow, fork] */ short uf_busy; /* file is allocated [grow, fork] */ kcondvar_t uf_wanted_cv; /* waiting for setf() [never copied] */ kcondvar_t uf_closing_cv; /* waiting for close() [never copied] */ struct portfd *uf_portfd; /* associated with port [grow] */ /* Avoid false sharing - pad to coherency granularity (64 bytes) */ char uf_pad[64 - sizeof (kmutex_t) - 2 * sizeof (void*) - 2 * sizeof (int) - 2 * sizeof (short) - 2 * sizeof (kcondvar_t) - sizeof (struct portfd *)]; } uf_entry_t; See usr/src/uts/common/sys/user.h The file descriptor list is anchored in the process's user area in the uf_info_t structure pointed to by u_finfo. typedef struct user { ... uf_info_t u_finfo; /* open file information */ } user_t; /* * Per-process file information. */ typedef struct uf_info { kmutex_t fi_lock; /* see below */ kmutex_t fi_pad; /* unused -- remove in next release */ int fi_nfiles; /* number of entries in fi_list[] */ uf_entry_t *volatile fi_list; /* current file list */ uf_rlist_t *fi_rlist; /* retired file lists */ } uf_info_t; See usr/src/uts/common/sys/user.h There are two lists of file descriptor entries in each process: an active set (fi_list) and a retired set (fi_rlist). The active set contains all the current file descriptor entries (open and closed), each of which points to a corresponding file_t file table entry. The retired set is used when the fi_list array is resized; as part of a lockless find algorithm, once file_t entries are allocated, they are never unallocated, so pointers to file_t entries are always valid. In this manner, the algorithm need only lock the fi_list during resize, making the common case (find) fast and scalable. 14.2.2. The open Code PathAs an example, a common path through file descriptor and file allocation is through the open() system call. The open() system call returns a file descriptor to the process for a given path name. The open() system call is implemented by copen (common open), which first allocates a new file_t structure from the file_cache kernel allocator cache. The algorithm then looks for the next available file descriptor integer within the process's allocate fd integer space by using fd_find(), and reserves it. With an fd in hand, the lookup routine parses the "/"-separated components, calling the file-system-specific lookup function for each. After all path-name components are resolved, the vnode for the path is returned and linked into the file_t file table entry. The file-system-specific open function is called to increment the vnode reference count and do any other per-vnode open handling (typically very little else, since the majority of the open is done in lookup rather than the file systems' open() function. Once the file table handle is set up, it is linked into the process's file descriptor fi_list array and locked. -> copen Common entry point from open(2) -> falloc Allocate a per-process file_t file table entry -> ufalloc_file Allocate a file descriptor uf_entry -> fd_find Find the next available fd integer <- fd_find -> fd_reserve Reserve the fd integer <- fd_reserve <- ufalloc_file <- falloc -> fop_lookup Look up the file name supplied in open() -> ufs_lookup In this case, get UFS to do the hard work -> dnlc_lookup Check in the DNLC <- dnlc_lookup <- ufs_lookup Return a vnode to copen() <- fop_lookup -> fop_open Call the file system specific open function -> ufs_open Bump ref count in vnode, etc... <- ufs_open <- fop_open -> setf Lock the processes uf_entry for this file <- setf <- copen All done 14.2.3. Allocating and Deallocating File DescriptorsOne of the central functions is that of managing the file descriptor integer space. The fd_find(file_t *, int minfd) and fd_reserve() functions are the primary interface into the file descriptor integer space management code. The fd_find() function locates the next lowest available file descriptor number, starting with minfd, to support fcntl(fd, F_DUPFD, minfd). The fd_reserve() function either reserves or unreserves an entry by passing a 1 or -1 as an argument. Beginning with Solaris 8, a significantly revised algorithm manages the integer space. The file descriptor integer space is a binary tree of per-process file entries (uf_entry) structures. The algorithm is as follows. Keep all file descriptors in an infix binary tree in which each node records the number of descriptors allocated in its right subtree, including itself. Starting at minfd, ascend the tree until a non-fully allocated right subtree is found. Then descend that subtree in a binary search for the smallest fd. Finally, ascend the tree again to increment the allocation count of every subtree containing the newly allocated fd. Freeing an fd requires only the last step: Ascend the tree to decrement allocation counts. Each of these three steps (ascent to find non-full subtree, descent to find lowest fd, ascent to update allocation counts) is O(log n); thus the algorithm as a whole is O(log n). We don't implement the fd tree by using the customary left/right/parent pointers, but instead take advantage of the glorious mathematics of full infix binary trees. For reference, here's an illustration of the logical structure of such a tree, rooted at 4 (binary 100), covering the range 17 (binary 001111). Our canonical trees do not include fd 0; we'll deal with that later. We make the following observations, all of which are easily proven by induction on the depth of the tree:
Next, we need a few two's-complement math tricks. Suppose a number, N, has the following form: N = xxxx10...0 That is, the binary representation of N consists of some string of bits, then a 1, then all 0's. This amounts to nothing more than saying that N has a lowest-set bit, which is true for any N N - 1 = 1 = xxxx01...1: N & (N - 1) = xxxx000000 N | (N - 1) = xxxx111111 N ^ (N - 1) = 111111 In particular, this suggests several easy ways to clear all but the LSB, which by (T2) is exactly what we need to determine CSIZE(N) = 10...0. We opt for this formulation: (C1) CSIZE(N) = (N - 1) ^ (N | (N-1)) Similarly, we have an easy way to determine LPARENT(N), which requires that we clear the LSB of N: (L1) LPARENT(N) = N & (N-1) We note in the above relations that (N | (N - 1)) - N = CSIZE(N) - 1. When combined with (T4), this yields an easy way to compute RPARENT(N): (R1) RPARENT(N) = (N | (N - 1)) + 1 Finally, to accommodate fd 0, we must adjust all of our results by ± 1 to move the fd range from [1, 2^n) to [0, 2^n - 1). This is straightforward, so there's no need to belabor the algebra; the revised relations become (C1a) CSIZE(N) = N ^ (N | (N + 1)) (L1a) LPARENT(N) = (N & (N + 1)) - 1 (R1a) RPARENT(N) = N | (N + 1) This completes the mathematical framework. We now have all the tools we need to implement fd_find() and fd_reserve(). The fd_find(fip, minfd) function finds the smallest available file descriptor
We begin by comparing the number of allocated fds in the root to the number of allocated fds in its right child; if they differ by exactly CSIZE(child), we know the left subtree is full, so we descend right; that is, the right child becomes the search root. Otherwise, we leave the root alone and start following the right child's left children. As fortune would have it, this is simple computationally: by (T5), the right child of fd is just fd + size, where size = CSIZE(fd) / 2. Applying (T5) again, we find that the right child's left child is fd + size - (size / 2) = fd + (size / 2); its left child is fd + (size / 2) - (size / 4) = fd + (size / 4), and so on. In general, fd's right child's leftmost nth descendant is fd + (size >> n). Thus, to follow the right child's left descendants, we just halve the size in each iteration of the search. When we descend leftward, we must keep track of the number of fds that were allocated in all the right subtrees we rejected so that we know how many of the root fd's allocations are in the remaining (as yet unexplored) leftmost part of its right subtree. When we encounter a fully allocated left childthat is, when we find that fip->fi_list[fd].uf_alloc == ralloc + sizewe descend right (as described earlier), resetting ralloc to zero. The fd_reserve(fip, fd, incr) function either allocates or frees fd, depending on whether incr is 1 or -1. Starting at fd, fd_reserve() ascends the leftmost ancestors (see (T3)) and updates the allocation counts. At each step we use (L1a) to compute LPARENT(), the next left ancestor. 14.2.4. File Descriptor LimitsEach process has a hard and soft limit for the number of files it can have opened at any time; these limits are administered through the Resource Controls infrastructure by process.max-file-descriptor (see Section 7.5 for a description of Resource Controls). The limits are checked during falloc(). Limits can be viewed with the prctl command. sol9$ prctl -n process.max-file-descriptor $$ process: 21471: -ksh NAME PRIVILEGE VALUE FLAG ACTION RECIPIENT process.max-file-descriptor basic 256 - deny 21471 privileged 65.5K - deny - system 2.15G max deny - If no resource controls are set for the process, then the defaults are taken from system tuneables; rlim_fd_max is the hard limit, and rlim_fd_cur is the current limit (or soft limit). You can set these parameters systemwide by placing entries in the /etc/system file. set rlim_fd_max=8192 set rlim_fd_cur=1024 14.2.5. File StructuresA kernel object cache segment is allocated to hold file structures, and they are simply allocated and linked to the process and vnode as files are created and opened. We can see in Figure 14.2 that each process uses file descriptors to reference a file. The file descriptors ultimately link to the kernel file structure, defined as a file_t data type, shown below. /* * fio locking: * f_rwlock protects f_vnode and f_cred * f_tlock protects the rest * * The purpose of locking in this layer is to keep the kernel * from panicking if, for example, a thread calls close() while * another thread is doing a read(). It is up to higher levels * to make sure 2 threads doing I/O to the same file don't * screw each other up. */ /* * One file structure is allocated for each open/creat/pipe call. * Main use is to hold the read/write pointer associated with * each open file. */ typedef struct file { kmutex_t f_tlock; /* short term lock */ ushort_t f_flag; ushort_t f_pad; /* Explicit pad to 4 byte boundary */ struct vnode *f_vnode; /* pointer to vnode structure */ offset_t f_offset; /* read/write character pointer */ struct cred *f_cred; /* credentials of user who opened it */ struct f_audit_data *f_audit_data; /* file audit data */ int f_count; /* reference count */ } file_t; See usr/src/uts/common/sys/file.h The fields maintained in the file structure are, for the most part, self-explanatory. The f_tlock kernel mutex lock protects the various structure members. These include the f_count reference count, which lists how many file descriptors reference this structure, and the f_flag file flags. Since files are allocated from a systemwide kernel allocator cache, you can use MDB's ::kmastat dcmd to look at how many files are opened systemwide. The sar command also shows the same information in its file-sz column. This example shows 1049 opened files. The format of the sar output is a hold-over from the early days of static tables, which is why it is displayed as 1049/1049. Originally, the value on the left represented the current number of occupied table slots, and the value on the right represented the maximum number of slots. Since file structure allocation is completely dynamic in nature, both values will always be the same. sol8# mdb -k > ::kmastat !grep file cache buf buf buf memory alloc alloc name size in use total in use succeed fail ------------------------- ------ ------ ------ --------- --------- ----- file_cache 56 1049 1368 77824 9794701 0 # sar -v 3 333 SunOS ozone 5.10 Generic i86pc 07/13/2005 17:46:49 proc-sz ov inod-sz ov file-sz ov lock-sz 17:46:52 131/16362 0 8884/70554 0 1049/1049 0 0/0 17:46:55 131/16362 0 8884/70554 0 1049/1049 0 0/0 We can use MDB's ::pfiles dcmd to explore the linkage between a process and file table entries. sol8# mdb -k > 0t1119::pid2proc ffffffff83135890 > ffffffff83135890::pfiles -fp FILE FD FLAG VNODE OFFSET CRED CNT ffffffff85ced5e8 0 1 ffffffff857c8580 0 ffffffff83838a40 1 ffffffff85582120 1 2 ffffffff857c8580 0 ffffffff83838a40 2 ffffffff85582120 2 2 ffffffff857c8580 0 ffffffff83838a40 2 ffffffff8362be00 3 2001 ffffffff836d1680 0 ffffffff83838c08 1 ffffffff830d3b28 4 2 ffffffff837822c0 0 ffffffff83838a40 1 ffffffff834aacf0 5 2 ffffffff83875a80 33 ffffffff83838a40 1 > ffffffff8362be00::print file_t { f_tlock = { _opaque = [ 0 ] } f_flag = 0x2001 f_pad = 0xbadd f_vnode = 0xffffffff836d1680 f_offset = 0 f_cred = 0xffffffff83838c08 f_audit_data = 0 f_count = 0x1 } > 0xffffffff836d1680::vnode2path /zones/gallery/root/var/run/name_service_door For a specific process, we use the pfiles(1) command to create a list of all the files opened. sol8$ pfiles 1119 1119: /usr/lib/sendmail -Ac -q15m Current rlimit: 1024 file descriptors 0: S_IFCHR mode:0666 dev:281,2 ino:16484 uid:0 gid:3 rdev:13,2 O_RDONLY /zones/gallery/root/dev/null 1: S_IFCHR mode:0666 dev:281,2 ino:16484 uid:0 gid:3 rdev:13,2 O_WRONLY /zones/gallery/root/dev/null 2: S_IFCHR mode:0666 dev:281,2 ino:16484 uid:0 gid:3 rdev:13,2 O_WRONLY /zones/gallery/root/dev/null 3: S_IFDOOR mode:0444 dev:279,0 ino:34 uid:0 gid:0 size:0 O_RDONLY|O_LARGEFILE FD_CLOEXEC door to nscd[762] /zones/gallery/root/var/run/name_service_door 4: S_IFCHR mode:0666 dev:281,2 ino:16486 uid:0 gid:3 rdev:21,0 O_WRONLY FD_CLOEXEC /zones/gallery/root/dev/conslog 5: S_IFREG mode:0600 dev:102,198 ino:11239 uid:25 gid:25 size:33 O_WRONLY /zones/gallery/root/var/spool/clientmqueue/sm-client.pid In the preceding examples, the pfiles command is executed on PID 1119. The PID and process name are dumped, followed by a listing of the process's opened files. For each file, we see a listing of the file descriptor (the number to the left of the colon), the file type, file mode bits, the device from which the file originated, the inode number, file UID and GID, and the file size. |
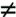 1; 0. If we look at
1; 0. If we look at 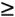 minfd. It does not actually allocate the descriptor; thats done by fd_reserve(). fd_find() proceeds in two steps:
minfd. It does not actually allocate the descriptor; thats done by fd_reserve(). fd_find() proceeds in two steps: minfd. We start at the right subtree rooted at minfd. If this subtree is not fullif fip->fi_list[minfd].uf_alloc != CSIZE(minfd)then step 1 is done. Otherwise, we know that all fds in this subtree are taken, so we ascend to RPARENT(minfd) using (R1a). We repeat this process until we either find a candidate subtree or exceed fip->fi_nfiles. We use (C1a) to compute CSIZE().
minfd. We start at the right subtree rooted at minfd. If this subtree is not fullif fip->fi_list[minfd].uf_alloc != CSIZE(minfd)then step 1 is done. Otherwise, we know that all fds in this subtree are taken, so we ascend to RPARENT(minfd) using (R1a). We repeat this process until we either find a candidate subtree or exceed fip->fi_nfiles. We use (C1a) to compute CSIZE().EAN: 2147483647
Pages: 244