Performance vs. Scalability
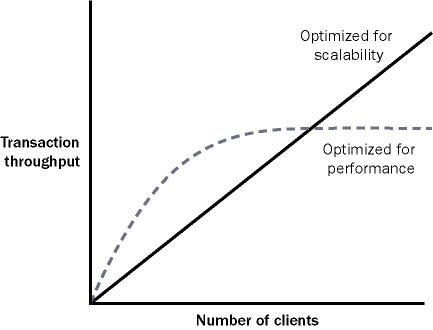
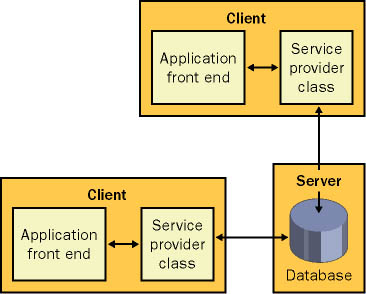
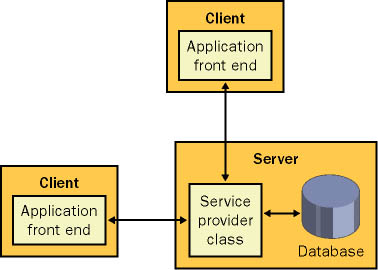
| One key theme in distributed application design is the tradeoff between performance and scalability. Performance is a measure of the application's speed, whereas scalability indicates how this speed varies as the client load increases or the server hardware is upgraded. We've already considered one example of the difference between performance and scalability with session state. In ASP (the previous version of ASP.NET), Web pages that use session state almost always perform faster for small numbers of clients. Somewhere along the way, however, as the number of simultaneous clients increases, they reach a bottleneck and perform terribly. Figure 10-1 diagrams this relationship. Figure 10-1. Performance vs. scalability The distinction between performance for small numbers of users and scalability to large numbers is alive and well in the .NET world. One of the best examples occurs with database connection pooling. Consider, for example, a system with a stateless database component and two Windows clients (on two separate computers). Each method in the database component follows best practices: It creates a connection, performs an operation, and then closes the connection immediately. In configuration A, both clients have local copies of the database component (as shown in Figure 10-2). Therefore, they can use it locally (and speedily) in-process. Connections can't be pooled between the two, however, because the component is always instantiated in the process of the client. In configuration B, the database component lives on the database server and communicates with out-of-process clients through .NET Remoting (as shown in Figure 10-3). This intrinsically adds overhead because all calls must travel over process boundaries and the network. However, it allows connections to be pooled among all clients. Figure 10-2. Configuration A: best performance for small client numbers Figure 10-3. Configuration B: best scalability So which approach is better? Typically, configuration A is best for small client situations. For systems with a large number of clients that perform a relatively small number of database transactions, configuration B is the best choice because it leverages all the advantages of connection pooling. The conclusion you should draw is that you can't design every type of system in the same way (although you can often use the same technologies and very similar code). Distributing the layers of a small-scale system might only slow it down. On the other hand, a system that supports a heavy client load needs the features; otherwise, it will encounter a bottleneck essentially becoming a victim of its own success. There is one piece of good news, however. If you follow good design practices, the amount of work required to transfer design A into design B can be quite small. Ideally, you would design the database component using the service provider model presented in the earlier chapters. This approach works equally well for a local object as for a server-side object. In fact, you can even derive the local service provider from MarshalByRefObject and mark the information package with the Serializable attribute. These features won't add any extra overhead if you choose not to use them. When you need to make the transition from design A to design B, you simply modify how the client creates the service provider object. The code used to interact with this object is unchanged. More Information Chapter 12 takes a closer look at best practices for using connection pooling with .NET Remoting and XML Web services. The Lessons LearnedThe best approach is to design your components with distributed architecture in mind but distribute them to separate computers only when required. So when is distributed architecture required? You might need to shift to a distributed architecture for either of the following reasons:
As you've seen, when you design components for a distributed environment, you must keep a number of considerations in mind. Here are some points to remember:
Finally, remember that remote objects aren't true players in object-oriented design. If you are in danger of forgetting this principle, remind yourself of some of these limitations:
Not only is it a mistake to try to create remote components that model ordinary objects, but it's also bad idea to try to create an intermediary layer of objects that masks this reality. The more you distance yourself from the practical reality of your system, the more you risk encouraging a client to ignore this reality and use your component inefficiently. A successful distributed application should guide the client toward proper use and restrict options (such as a GetAllAccounts method) that might reduce performance. This approach isn't insulting. In fact, it's the same principle that Microsoft has followed in constraining the ADO.NET DataSet to disconnected use and in defaulting XML Web services and remote objects to stateless behavior. |
EAN: 2147483647
Pages: 174