Fundamental Namespaces
| The .NET Framework class library provides so many services that it's challenging to decide which ones are most fundamental. One developer might use something in every application that another developer never needs. Still, a basic knowledge of the .NET technologies described nextinput and output, serialization, reflection, transactions, and inter operabilityshould be part of every .NET developer's arsenal. Input and Output: System.IOLike most software, .NET Framework applications need some way to input and output data. These operations are most commonly done against some kind of disk storage, but there are other possibilities too. The .NET Framework class library's System.IO namespace contains a group of types that developers can use to read and write files, work with directories in a file system, and do other kinds of straightforward data access.
Among the most important of these types is the Stream class. This class defines the useful abstraction of a stream, which is a sequence of bytes together with methods to read the stream's contents, write those contents, perhaps seek a specific location in the stream, and perform other operations. Stream is an abstract class, and so a number of specialized classes inherit from it. The goal is to let developers work with various kinds of information in a consistent way.
Information stored in files can be accessed using the File class. While an instance of File provides familiar methods for working with files such as Create, Delete, and Open, it doesn't provide methods for reading and writing a file's contents. Instead, a File object's Create and Open methods return an instance of a FileStream that can be used to get at the file's contents. Like all streams, a FileStream object provides Read and Write methods for synchronous access to a file's data, that is, for calls that block waiting for data to be read or written. Also like other streams, FileStream objects allow asynchronous access using the paired BeginRead/EndRead and BeginWrite/EndWrite methods. These methods allow a .NET Framework application to begin a read or write operation and then check later to get the result. Each FileStream also provides a Seek method to move to a designated point in the file, a Flush method to write data to the underlying device (such as a disk), a Close method to close the FileStream, and many more.
FileStreams work only with binary data, however, which isn't always what's needed. System.IO provides other standard classes to work with file data in other formats. For example, a class called FileInfo can be used to create FileStreams, but it can also be used to create instances of the classes StreamReader and StreamWriter. Unlike File, whose methods are mostly static, an instance of a FileInfo class must be explicitly created before its methods can be used. Once a FileInfo object exists, its OpenText method can be used to create a new StreamReader object. This StreamReader can then be used to read characters from whatever file is associated with the FileInfo object.
Here's a C# example that illustrates how these classes can be used: using System; using System.IO; class FileIOExample { static void Main() { FileStream fs; FileInfo f; StreamReader sr; byte[] buf = new byte[10]; string s; int i; for (i=0; i<10; i++) buf[i] = (byte) (65 + i); fs = File.Create("test.dat"); fs.Write(buf, 0, 10); fs.Close(); f = new FileInfo("test.dat"); sr = f.OpenText(); s = sr.ReadToEnd(); Console.WriteLine("{0}", s); } }This admittedly unrealistic example begins with appropriate using directives and then defines the single class FileIOExample. This class contains only a Main method, which begins with several declarations. After this, the 10-byte buffer buf is populated with the characters "A" through "J." Because buf can accept only bytes, this is done by explicitly calculating each character's value and then forcing the result to be of type byte. (This forced type conversion is called casting.) File's Create method is then used to create a file, followed by a call to File's Write method. This method writes buf's ten characters into that file and is followed by a Close call that closes the file. Because the File class declares all of these methods to be static, they can be invoked without explicitly creating a File instance. The example next opens the same file using an instance of the FileInfo class. Calling the FileInfo object's OpenText method returns a StreamReader object whose ReadToEnd method can be used to read the characters just written into a string. Stream Readers also provide methods to read single characters, blocks of characters, and lines of characters. Finally, the characters read from the file are written to the console, yielding the result ABCDEFGHIJ System.IO also defines several other useful types. The Directory class, for instance, provides methods such as CreateDirectory to create a new directory, Delete to destroy an existing directory and its contents, and several more. The MemoryStream class allows the typical operations defined for a stream, such as Read, Write, and Seek, to be carried out on an arbitrary set of bytes in memory. StringWriter and StringReader provide analogous functions to StreamWriter and StreamReader, except that instead of working with files, they work with in-memory strings. BinaryReader and BinaryWriter allow reading and writing values of types such as integers, decimals, and characters from a stream. While information stored in relational databases is more important for many applications, data stored in files still matters. The classes in System.IO provide a flexible set of options for working with that data.
Serialization: System.Runtime.SerializationObjects commonly have state. An instance of a class, for example, can have one or more fields, each of which contains some value. It's often useful to extract this state from an object, either to store the state somewhere or to send it across a network. Performing this extraction is called serializing an object, while the reverse process, recreating an object from serialized state, is known as deserializing. Somewhat confusingly, the term serialization is commonly used to refer to the ability to do both.
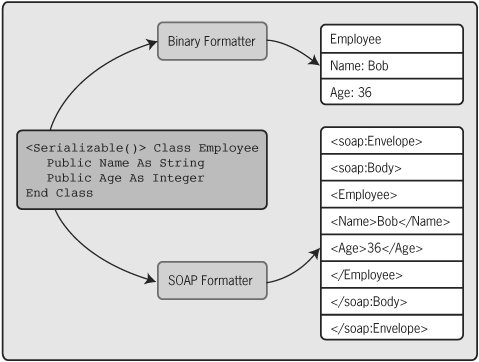
The .NET Framework class library provides support for serialization. The work of serialization is done by a particular formatter, each of which provides a Serialize and Deserialize method. The NET Framework class library provides two varieties of formatter. The binary formatter, implemented by the BinaryFormatter class in the System.Runtime.Serialization.Formatters.Binary namespace, serializes an object into a straightforward binary form designed to be compact and quick to parse. The SOAP formatter, implemented by the SoapFormatter class in the System.Runtime.Serialization.Formatters.Soap namespace, serializes an object into a SOAP message.
Figure 4-1 illustrates the serialization process. As the figure shows, an instance of a class can be run through a formatter that extracts the state of this object in a particular form. The binary formatter emits that state information in a simple and compact form, while the SOAP formatter generates the same information wrapped in XML and formatted as a SOAP message.[1] While the outputs shown in the figure are simplifiedthe binary formatter actually stores integers in binary form, for instancethey illustrate the key difference between the two serialization options built into the .NET Framework class library.
Figure 4-1. The System.Runtime.Serialization namespace provides two different formatters to serialize an object's state.
When a formatter serializes an object, the resulting state is placed into a stream. As described in the previous section, a stream is an abstraction of a sequence of bytes and so can hold any serialization format. Once it's in a stream, an object's state can be stored on disk (or in the jargon of objects, be made persistent), sent across a network to another machine, or used in some other way.
For a type to be serializable, its creator must mark it with the Serializable attribute, as Figure 4-1 illustrates. The Serializable attribute can be assigned to classes, structures, and other types or just to specific fields within a type to indicate that only they should be serialized. Also, a type marked with the Serializable attribute can indicate that certain fields should not be saved when an instance of this type is serialized by marking them with the NonSerialized attribute.
Here's a simple VB example that shows how serialization works: Imports System Imports System.IO Imports System.Runtime.Serialization Imports _ System.Runtime.Serialization.Formatters.Binary Module SerializationExample <Serializable()> Class Employee Public Name As String Public Age As Integer End Class Sub Main() Dim E1 As Employee = New Employee() Dim E2 As Employee = New Employee() Dim FS As FileStream Dim BinForm As BinaryFormatter = _ New BinaryFormatter() E1.Name = "Bob" E1.Age = 36 FS = File.Create("test.dat") BinForm.Serialize(FS, E1) FS.Close() FS = File.Open("test.dat", FileMode.Open) E2 = BinForm.Deserialize(FS) Console.WriteLine("E2 Name: {0}", E2.Name) Console.WriteLine("E2 Age: {0}", E2.Age) End Sub End ModuleThis example begins with several Imports statements, the VB analog to C#'s using directive. As always, these statements aren't required, but they make the code that follows more readable by removing the need to type fully qualified names. Following these, the module begins with the definition of a very simple Employee class. This class contains just two fields representing an employee's name and age and has no methods at all. (This is unrealistic, of course, but information about methods isn't stored anyway when a class is serialized.) The example's Sub Main routine creates two instances of the Employee class, E1 and E2, and then declares a FileStream called FS. It next creates an instance of the BinaryFormatter class that will be used to serialize and deserialize the objects' state. Once that state has been created by initializing E1's fields to contain a name and an age, the file test.dat is created to hold the serialized state. The binary formatter's Serialize method is then called, which serializes the state in E1 into the stream FS. When the stream is closed, its contents are written to the file test.dat. The example then reopens test.dat, associating it once again with the stream FS. This stream is passed into the binary formatter's Deserialize method, with the result assigned to E2. Although E2 has had just its default state so far, the deserialization process gives it the state that was extracted earlier from E1. Accordingly, the output of this simple program is E2 Name: Bob E2 Age: 36 Serialization can also be customized. For example, if a class implements the ISerializable interface, it can participate in its own serialization. This interface has only a single method that allows controlling the details of what gets serialized. Also, although it's not shown in this simple example, serializing an object will also serialize objects it refers to, causing them all to be serialized (or deserialized) at once. And for the brave, it's possible to build your own formatter that does serialization in a completely customized way by inheriting from the abstract class System.Runtime.Serialization.Formatter. However it's done, serialization is useful, and in its basic form, at least, it's simple to use. As described later, serialization plays a role in several parts of the .NET Framework class library.
Reflection: System.ReflectionEvery assembly includes metadata. Always having metadata available is handy, since it allows creating useful features such as Visual Studio's IntelliSense, which automatically displays the methods available for a class and other useful information. But metadata is just information sitting in a file. It's useless without software that knows how to read and interpret that metadata. To support this software, it's useful to have a standard interface to an assembly's metadata, one that can be used by all kinds of applications.
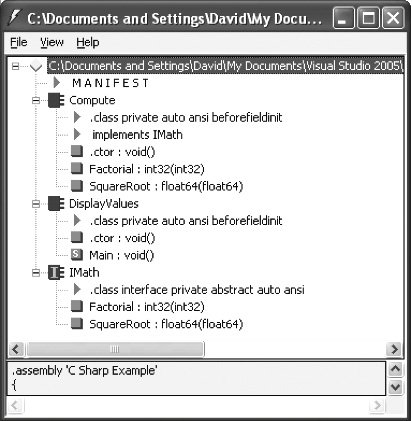
For managed code, that interface is provided by the types contained in the System.Reflection namespace. Before taking a look at these types, recall what metadata consists of: information about the types in an assembly, such as what methods they implement, along with information about the assembly itself, stored in the assembly's manifest. As mentioned in Chapter 2, the Ildasm tool can be used to examine an assembly's metadata. Figure 4-2 shows how Ildasm displays the metadata stored with the simple example application from Chapter 3. The manifest appears first, followed by entries for each of the three outermost types in the program: the classes Compute and DisplayValues and the interface IMath. Each of these has associated information, the most interesting of which is the methods each type implements. Note that along with the methods shown in Chapter 3's code, each class also has a constructor, labeled ".ctor" in the Ildasm display. Figure 4-2. The metadata stored with Chapter 3's simple example application can be displayed using Ildasm.
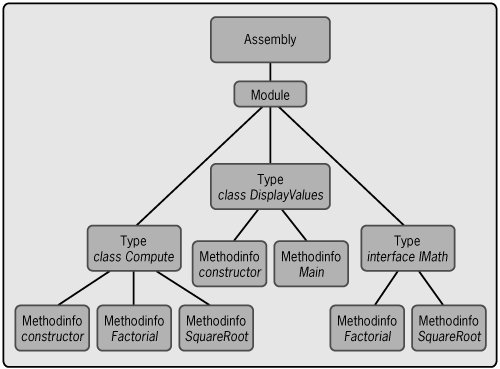
To allow programmatic access to this information, the System.Reflection namespace includes a class for each type of information in an assembly's metadata. An application can create instances of these classes as needed and then populate them with the appropriate information from a particular assembly. As Figure 4-3 shows, instances of these classes are organized into a hierarchy. Once the appropriate instances have been createdFigure 4-3 shows a fairly complete picture for Chapter 3's sample applicationthe assembly's metadata can be accessed[2]. Although it's not shown in the diagram, it's also possible to access any attributes this metadata contains.
Figure 4-3. The classes in System.Reflection can be used to create a hierarchical in-memory structure that contains an assembly's metadata.
For example, to list all methods contained in this assembly's Compute class, an application could create an instance of the Assembly class and then call this class's LoadFrom method with the name of the file containing the assembly. The Assembly class also provides a GetModule method that can be used to return an instance of the Module class that describes the module containing the Compute class. Once this Module instance exists, the application can call GetType with the name of the desired type in this module, which in this case is Compute. The result is an object of the class Type that contains information about the Compute class. The Type class provides a large set of methods and properties for learning about its contents. For example, a call to Type.GetMethods can return a description of all methods that type implements, each contained in an instance of the class MethodInfo. In this case, three MethodInfo objects would be returned, each containing information about one of Compute's three methods. By examining the properties of each MethodInfo, the application can learn whatever it needs to know about these methods. Among the information available is the method's name, the types of its parameters, its return type, whether the method is final (sealed), and much more. The Reflection namespace also contains the subordinate namespace Reflection.Emit. To understand what the types in this namespace do, it's first important to understand the two types of assemblies that can be used by the .NET Framework. As described in Chapter 2, the most common variety, static assemblies, are stored on and loaded from disk. All assemblies described so far have in fact been static assemblies. It's also possible to create dynamic assemblies, assemblies that are created directly in memory. With this approach, a running application creates MSIL code and metadata, building an assembly on the fly, and then executes it. The types in the Reflection.Emit namespace are used to do this.
Creating dynamic assemblies is not for the faint of heart. Reflection.Emit contains types that do very low-level things, including generating MSIL code one instruction at a time. (The CodeDom, described briefly earlier in this chapter, provides a somewhat simpler way to generate dynamic CLR-based applications.) Yet while most developers probably won't work directly with Reflection.Emit, it's useful to know that these types exist. Class libraries are meant to make developers' lives easier, and you can't use code in a library if you don't know the code is there.
XML: System.XmlXML is certainly among the most important new technologies to emerge in the last few years. Recognizing this, Microsoft has chosen to use XML in many different ways throughout the .NET Framework. The company also recognizes that its customers wish to use XML in a variety of ways. Accordingly, the .NET Framework class library includes a substantial amount of support for working with XML technologies, most of it contained in the System.Xml namespace.
The XML Technology FamilyTo get a sense of what the System.Xml namespace provides requires understanding a bit about the family of XML technologies. From its beginning as a way to define documents, elements in those documents, and namespaces for those elements, XML has evolved into a significantly more powerfuland significantly more complexgroup of technologies.
The familiar angle bracket form of XML implies a logical hierarchy of related information. This abstract set of information and relationships is known as the XML document's Information Set, a term that's usually shortened to just Infoset. An Infoset consists of some number of information items, each of which represents some aspect of the XML document from which this Infoset was derived. For example, every Infoset has a document information item that acts as the root of the tree, with a single root element information item just beneath it. Most Infosets have some number of child element information items below this root element.
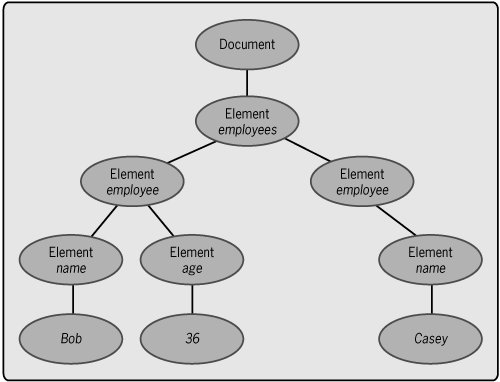
For example, consider this simple XML document: <employees> <employee> <name>Bob</name> <age>36</age> </employee> <employee> <name>Casey</name> </employee> </employees> The Infoset for this document can be represented as shown in Figure 4-4. The root of the Infoset's tree is a document information item, while below it is a hierarchy of element information items, one for each element in the XML document. The leaves of the tree are the values of the elements in this simple document. Figure 4-4. An XML document's Infoset is an abstract representation of the document's contents. XML documents and the Infosets they imply can provide the foundation for tools that manipulate a document's data. Among the most important of these is XPath, which provides a mechanism for identifying a subset of an Infoset. A simple and quite accurate way to think of XPath is as a query language for information in XML documents (that is, for XML Infosets). Just as SQL provides a standard language for querying information contained in a relational database, XPath provides a language for querying information represented as a hierarchy.
Using an XPath expression, a user can identify specific nodes in a tree. For example, imagine that this query is issued against the simple XML document just described: /employees/employee/name This simple XPath request first identifies each employee element below the root employees element and then identifies the values of each name element in each of those employee elements. Far more complex queries are also possible, including queries that use comparison operators, compute sums, include wildcards, and much more. With XPath, a developer need not write her own code to search through information. Instead, this standard language can be used to find information represented as an in-memory XML document. Another technology built on the abstract foundation provided by XML Infosets is the Extensible Stylesheet Language Transformations, universally referred to as XSLT. XSLT is a mechanism for specifying transformations of XML documents using an XSLT stylesheet. For instance, a set of XSLT rules that transforms an XML document from one schema to another can be defined. XSLT also relies on the abstract form of an XML document represented by its Infoset, and it relies on XPath for some of its functionality.
Figure 4-5 summarizes the relationships among the fundamental XML technologies. An XML Schema definition describes the structure and contents of an XML documentit defines a group of typeswhile an XML document itself can be thought of as an instance of the document type defined by some schema[3]. This XML document, in turn, is the foundation for an Infoset, which provides an abstract view of the document's data. Technologies for working with that data, such as XPath and XSLT, are effectively defined to work against the Infoset, allowing them to remain independent of the specific representation used for the XML document itself. Note that because these technologies rely on the Infoset rather than the familiar angle bracketbased syntax of an XML document, they can actually be used with any data that can be represented in a strict hierarchy. That data need not necessarily come from a traditional XML document as long as it can be represented as an Infoset. For example, hierarchical data such as a file system or the Windows registry might be accessed in this way.
Figure 4-5. XML is a family of technologies, with the Infoset at the center.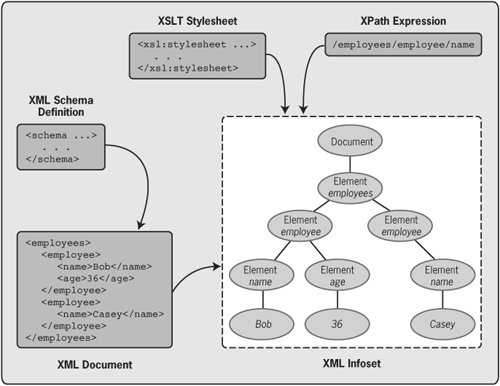
The XML standards don't mandate any particular approach to processing the information in an XML document. As it happens, two styles of APIs have come into common use. In one approach, the information in an XML document is read sequentially, traversing a document's tree in a depth-first search. An API that supports this kind of access is referred to as a streaming API, and one common choice for this is the Simple API for XML (SAX). SAX was created by a group of volunteers independent of the W3C or other formal standards groups, but it is supported by many vendors today.
In the second approach, the entire document is represented as an in-memory data structure (conceptually, at least), which allows an application to navigate through it, moving back and forth as needed. The most commonly used API for this option is an implementation of the Document Object Model (DOM) defined by the W3C. Because of the style of access it allows, the DOM is an example of a navigational API.
What System.Xml ProvidesThe System.Xml namespace has a variety of support for working with XML. Among the features available are support for both streaming and navigational APIs, the ability to use XPath queries, the ability to perform XSLT transformations, and more. While describing all of these features in any detail is well beyond the scope of this book, this section provides an overview of their most important aspects.
The most fundamental types for handling XML-defined data are contained directly in System.Xml itself. Among these fundamental types is the class XmlReader, which provides a streaming interface for reading the information in an XML document sequentially. (Note while this is similar to the SAX API, the .NET Framework does not directly support SAX; instead it bases all streaming access on XmlReader.) This is the fastest option for reading XML-defined data, but it's also somewhat limited in that no navigation is possible through the document.
The XmlReader class provides a Create method that can be passed an instance of the XmlReaderSettings class. Based on the properties specified in XmlReaderSettings, the newly created XmlReader instance can behave in different ways. The properties that can be specified via XmlReaderSettings include (among many others) the following:
It's worth pointing out that this style of working with an XmlReader is new in version 2.0 of the .NET Framework. Previous releases provided a standard set of more specialized classes that inherited from XmlReader, such as XmlTextReader and XmlValidatingReader, allowing a developer to choose whichever class best met her needs. Given version 2.0's more flexible approach, these classes are now deprecated.
System.Xml also includes an XmlWriter class. The methods in this class allow writing XML information, angle brackets and all, to a stream. As described earlier in this chapter, a stream can be maintained in memory, written to a file, or used in some other way. Much like XmlReader, version 2.0 of the .NET Framework provides a Create method on the XmlWriter class, along with an XmlWriterSettings class that can be passed in when a new XmlWriter instance is created. Some example properties that can be specified using XmlWriterSettings are:
System.Xml also includes the XmlDocument class. This class provides an implementation of the DOM API. While using an XmlReader is the fastest way to access information in an XML document, the XmlDocument class is more general because it allows navigation, moving backward and forward through the document at will. A developer is free to choose whichever approach best meets the needs of his application. The methods and properties provided by XmlDocument give some idea of the kinds of operations the DOM allows. Those methods include the following:
XmlDocument also exposes a number of properties that allow navigation through the tree. They include the following:
In version 2.0 of the .NET Framework, it's also possible to use an XmlDocument object to create an object of the class XPathNavigator. An XPathNavigator provides a way to use XPath expressions to navigate through and modify the information in this XmlDocument. Several other namespaces are defined beneath System.Xml:
XML has become an essential part of modern computing. By providing a standard way to describe information, it fills an important hole in the complex, multivendor world we live in. The .NET Framework's large set of namespaces and types devoted to XML are intended to make this important technology significantly easier to use.
Transactions: System.TransactionsThe idea of a transactiona group of two or more operations that succeed or fail as a single unitis fundamental to many applications. The idea itself is simple: Either everything happens or nothing happens. Yet because of the thousand natural shocks that software is heir to, ensuring that a group of operations can result in only these two outcomes isn't simple at all. Accordingly, the .NET Framework provides services that make it easier to create transactional applications.
Transactions are most commonly used with DBMSs. As described in Chapter 6, a .NET developer can use ADO.NET to explicitly start a DBMS transaction, perform operations inside that transaction such as updating records in the DBMS, then explicitly commit or abort the transaction. (In the jargon of transactions, a DBMS and anything else capable of correctly carrying out transactional requests is known as a resource manager or RM, a more general term that will be used from now on.) This simple approach works well when all of a transaction's operations are requested from one application and are performed by a single RM, such as a DBMS.
A developer's life gets more complicated when the operations in a single transaction can be issued from multiple entities, such as two or more objects in the same application, or carried out by multiple RMs. While these situations are less common, they're nonetheless important. The .NET Framework's support for this more complex style of transactional application is provided by Enterprise Services. This technology allows grouping operations issued by one or more objects into a single transaction, and it also allows the operations in a single transaction to be carried out by multiple RMs. Enterprise Services does more than just support transactions, however. It also provides services for managing object lifetimes and more, sometimes inextricably mingling these services together with transactions. (For more on this, see the description of Enterprise Services in Chapter 7.)
New with version 2.0 of the .NET Framework, System. Transactions provides another way for developers to work with transactions. Rather than bundling transaction control together with object lifetime management and other things, as is done in Enterprise Services, System.Transactions is focused entirely on controlling transactions. It's important to emphasize that the advent of System.Transactions doesn't break anything; Enterprise Services still works just as before, as does the transaction support in ADO.NET. System.Transactions does make using transactions somewhat simpler, however, since they're no long bound up with other unrelated ideas.
Controlling Transactions with Transaction ScopesThe easiest way to control transactional behavior with System.Transactions is to use an object of the type TransactionScope. Here's the basic skeleton of how an application can use this class to create a new transaction, do work within it, then commit that transaction: using System.Transactions; using (TransactionScope ts = new TransactionScope()) { // Do work, e.g., update different DBMSs ts.Complete; }
As this example shows, System.Transactions allows using transactions in concert with a using statement. Unlike using a namespace at the start of a C# program (a usage that's actually an example of a using directive), a using statement allows creating an instance of an object, then having this object automatically disposed of when the statement's scope is exited. In this example, the using statement creates a TransactionScope object, then automatically disposes of it when the using statement ends. The TransactionScope object defines a new transaction, sometimes referred to as the ambient transaction. All of the operations within the using block belong to the same transaction scope, and so all will become part of this transaction. The last line in this example, calling the TransactionScope object's Complete method, is effectively a vote to commit the transaction when the block is exited. If all goes wellif all RMs involved can successfully commit the transactionand if this block isn't nested within a larger transaction scope (a notion described later in this section), the transaction will commit, making all work done within it permanent. If Complete is not called within the scope, however, or if an unhandled exception is raised within the scope, the transaction will abort. In this case, all of the work done within the transaction will revert to the state it was in before the transaction began. Interestingly, TransactionScope provides no method that's the opposite of Complete. Since either raising an exception or just failing to call Complete before leaving the scope will cause the transaction to abort, there's no need to add this extra option.
Starting and ending a transaction using a TransactionScope object is simple to understand and simple to do. Other aspects of a transaction's behavior are a bit more complex, however. What happens when the transaction scopes defined using TransactionScope objects are combined, for example? Controlling this and other aspects of a transaction's behavior are described next.
Controlling the Behavior of a TransactionFrom 50,000 feet, a transaction is just a group of operations that either all succeed or all fail. Closer to the ground, however, more complexity emerges. For example, it's legal to explicitly nest transaction scopes, like this: using System.Transactions; using(TransactionScope ts1 = new TransactionScope()) { // Do work, e.g., update two different DBMSs using(TransactionScope ts2 = new TransactionScope()) { // Do more work, e.g., issue two more DBMS updates ts2.Complete; } ts1.Complete; }It's also possible for one TransactionScope to invoke a method that in turn contains a TransactionScope of its own. In both this case and the example above, one TransactionScope winds up nested inside another one. Are the two scopes separate, so that two independent transactions are created? Or is the work done inside both scopes combined into a single transaction? The answer depends on the value specified when each TransactionScope is created. Rather than creating a scope with just new TransactionScope( ), it's possible to pass in a value on creation that controls how this scope will behave when it's combined with other scopes. The possible values and their meanings are as follows:
These options can be set whenever a new TransactionScope object is created. For example, a scope set to RequiresNew can be created with using (TransactionScope ts = new TransactionScope(RequiresNew)) {...}and one with a scope set to Suppress can be created with using(TransactionScopets = new TransactionScope(Suppress)) {...}Scopes can be combined in arbitrarily complex ways. However they're grouped together, each scope always votes on how it wishes to end the transaction it's part of. If the code in every scope contained within a particular transaction calls that TransactionScope's Complete method, that transaction will commit (assuming no errors occur in the RMs the transaction accesses or elsewhere). If the code in any scope contained within a particular transaction fails to call its TransactionScope's Complete method or raises an unhandled exception, the transaction will abort. In this case, all changes made to any RMs in all of the scopes in this transaction will be rolled back.
Other aspects of a transaction's behavior, such as its timeout value, can also be set via options passed in when a new TransactionScope is created. Whatever the details, though, transactions have been important since the early days of mainframe computing, and they're still important today. System.Transactions provides a straightforward and focused way for .NET developers to create transactional applications.
Interoperability: System.Runtime.InteropServicesBefore the release of the .NET Framework, the world of Windows development was dominated by the Windows DNA technologies. Lots of applications were built using COM, Active Server Pages, COM+, and the rest of the DNA family, and those applications still exist. Many of them play an important role in running businesses, so they're certain to remain in use for at least the next few years. No matter how successful the .NET Framework is, the Windows DNA technologies that preceded it are not going away anytime soon.
Given the huge investment Microsoft's customers have made in these applications, the .NET Framework must provide some way for new applications to connect with them. Just as important, the Framework must provide an effective way for managed code to access existing DLLs that weren't built using COM and to invoke the raw services provided by the underlying operating system. Solutions to all of these problems are provided by the classes in the System.Runtime.InteropServices namespace.
Accessing COM ObjectsInteroperating with COM objects requires mapping between the CLR's type system and that defined by COM. Changing COM to better match the CLR wasn't an option for Microsoft. Even though they own the technology, COM is frozen in stone. The millions of lines of existing COM-based code in the world won't change to accommodate the new type system of the CLR, so the .NET Framework's solution for COM interoperability must adapt itself to the reality of the installed base.
Doing this can be simple. In some cases, mapping from a COM interface to a CLR type is straightforward. It can also be quite difficult, however, especially when the COM interface involved uses complex types. While it's virtually always possible to map the two together in some way, it isn't always easy. To make even difficult mappings possible, the classes in System.Runtime.InteropServices provide very fine-grained control over how the mapping is done as well as many, many options. While most people won't use most of these options most of the time, it's still good to know that they're available.
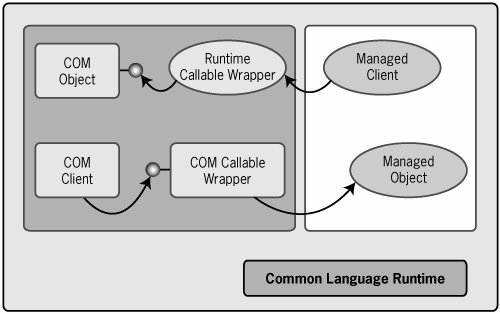
The fundamental model for interoperation between managed code and COM-based code is that each side sees the other in the form it expects: Managed code sees COM-based code as managed types, while COM-based code sees managed code as COM objects. How this looks is shown in Figure 4-6. To provide this illusion, the .NET Framework relies on two kinds of wrappers. One, known as a runtime callable wrapper (RCW), allows managed code to call a COM object. The other, a COM callable wrapper (CCW), allows COM code to access managed code. Figure 4-6. The .NET Framework's COM interoperability services can make a COM object look like managed code and managed code look like a COM object.
But where does the information needed to create these wrappers come from? Managed code sees the world in terms of assemblies, so to access a COM object as managed code, an assembly that mimics the COM class must exist. Furthermore, this assembly must contain metadata that accurately reflects the COM class's interfaces. To create this interoperability assembly, the .NET Framework provides a tool called Tlbimp, also known as the Type Library Importer. The input to this tool is a COM type library, and the output is an assembly that contains metadata for the CLR analogs of the COM types in the type library.
Once this assembly has been created, managed code can treat the library's COM classes just like any other managed code. When the managed code creates an instance of the class, the RCW actually creates the COM object. When the managed code invokes a method, the RCW makes a corresponding method invocation on the COM object. If an error occurs and the COM method returns an error HRESULT, as COM requires, the RCW automatically turns this into an exception that can be caught by the managed code. And when the managed code is finished using the object, it can behave just as it does when using any other managed object. The RCW will decrement the COM object's reference count before it is itself destroyed by the CLR's garbage collector.
When a COM client uses a managed class, the same kinds of things happen in the opposite direction. Rather than producing an assembly from a type library, the developer can now produce a type library from an assembly. The Type Library Exporter tool, known as Tlbexp, provides a way to do this. Also, because COM uses the registry to determine which code should be loaded for a particular class, assemblies that will be accessed by COM clients must have appropriate registry entries. The Assembly Registration tool, Regasm, can be used to do this and optionally to register the assembly's generated type library as well. When a COM client creates and uses an instance of a managed class, translations between the two worlds are performed as before, but this time they're done by the CCW rather than the RCW.
All of this sounds simple and straightforward, and it often is. Yet what's not been addressed so far is the process of converting between the CLR type system and the COM type system. To do this, the wrappers must translate data between the two environments. Default mappings are defined, and if those defaults work, using code from the other world is simple. Marshaling an integer, for example, is straightforward, since a value of this type is the same in both environments. If the default mappings aren't appropriate, however, a developer's life gets more complex. What should a CLR string map to in the COM world, for example? COM has more than one string format, and it's not always obvious which one should be used. To control this and other marshaling choices, a developer can use the MarshalAs attribute to indicate the choice she prefers. Figuring out the right thing to do isn't always easy, but the fine-grained control the types in this namespace provide at least makes it possible.
One last point worth noting is that making calls across the boundary between managed and unmanaged code is noticeably more expensive than making calls solely within either environment. Marshaling data between the two takes time, and so writing managed code that interoperates with unmanaged code has performance implications. It's a good idea to do as much work as possible on each call across this boundary. If each one does only a small amount of work, an application that makes a large number of calls between the two worlds might not perform especially well.
Accessing Non-COM DLLsWhile much of the existing code a .NET Framework application needs to use is accessible as COM classes, much of it isn't. Plenty of useful DLLs that don't use COM have been created. One important example of this is the Win32 API, exposed as a set of DLLs that allow direct access to Windows services. To allow managed code to call functions in these DLLs, the .NET Framework provides what are called platform invoke services, a phrase that's commonly shortened to just PInvoke.
To use these services, a developer must specify the name of some DLL he wishes to use, the entry point to be called, the parameter list, and possibly other information. How this is done varies with the language in use. In VB, for example, the Declare statement is used, while C# relies on an attribute called DllImport. Whichever choice is made, once a DLL function has been appropriately specified, it can be invoked as if it were a function in a managed object. The platform invoke services provide the necessary translations, including marshaling of parameter types, to carry out the call. System.Runtime.InteropServices is a critically important part of the .NET Framework class library. Although the notion of legacy software is sometimes viewed pejoratively, it has one enormous thing going for it: It works. If new code written on the .NET Framework had no way to communicate with the installed base, this new platform would have been much less attractive. The Framework's strong support for interoperability with existing code recognizes this reality, doing its part to smooth the transition to the brave new .NET world.
Windows GUIs: System.Windows.FormsMost Windows applications interact with people in some way. To allow this, the .NET Framework provides three primary approaches to creating user interfaces:
ASP.NET applications, a large topic, are described in Chapter 5. This section takes a brief look at creating Windows GUIs with Windows Forms. Building Application with Windows FormsIt can sometimes seem as if browser-based applications have taken over the world. Many developers who once focused on getting the Windows GUI right now instead sweat technical bullets over details of HTML and JavaScript. Browsers have become the new default interface for a whole generation of software. But Windows GUIs still matter. The ascendancy of browsers notwithstanding, applications that access pixels on a local screen are not going away. Recognizing this fact, the designers of the .NET Framework provided Windows Forms, a full set of classes that allow CLR-based applications to build Windows GUIs.
Stripped to its essentials, an application that presents a GUI displays a form on the screen and then waits for input from the user. This input is typically processed by a message loop, which passes the input on to the appropriate place, generally as one or more events. (Events, which are based on delegates, were described in Chapter 3.) For example, when the user clicks a button or hits a key or moves the mouse, events are sent to the form the user is accessing. Code associated with this form handles these events, perhaps writing output to the screen or performing other tasks.
In Windows Forms, every form is an instance of the Form class, while the message loop that accepts and distributes events is provided by a class called Application. Using these and other classes in System.Windows.Forms, a developer can create a single-document interface (SDI) application, able to display only one document at a time, or a multiple-document interface (MDI) application, able to display more than one document simultaneously.
Each instance of the Form class has a large set of properties that control how that form looks on the screen. Among them are Text, which indicates what caption should be displayed in the title bar; Size, which controls the form's initial on-screen size; DesktopLocation, which determines where on the screen the form appears; and many more. Developers set these properties to customize a form's appearance and behavior.
Forms commonly contain other classes called Windows Forms controls. Each of these controls typically displays some kind of output, accepts some input from the user, or both. The System.Windows.Forms namespace provides a large set of controls, many of which will be familiar to anyone who's built or even used a GUI. The control classes available in this namespace include Button, TextBox, CheckBox, RadioButton, ListBox, ComboBox, and many more. Also provided are more complex controls such as OpenFileDialog, which encapsulates the operations that let a user open a file; SaveFileDialog, which encapsulates the operations that let a user save a file; PrintDialog, which encapsulates the operations that let a user print a document; and several others. Version 2.0 of the .NET Framework added even more controls, including a WebBrowser that allows hosting Web pages in a Windows Forms application.
Like a form, each control has properties that can be set to customize its appearance and behavior. Many of these properties are inherited from System.Windows.Forms.Control, the base class for every control. (In fact, even the Form class inherits from System.Windows.Forms.Control.) The Button control, for example, has a Location property that determines where the button will appear relative to its container and a Size property that determines how big the on-screen button will be, both of which are directly inherited from the parent Control class. Button also has properties that aren't directly inherited from this parent, such as a Text property that controls what text will appear in the button.
Forms and controls also support events. Some examples of common events include Click, indicating that a mouse click has occurred; GotFocus, indicating that the form or control has been selected by the user; and KeyPress, indicating that a key has been pressed. All of these events and several more are defined in the base Control class from which all forms and controls inherit. As with properties, a control can also support unique events that have meaning only to it.
As shown in Chapter 3, a developer can create code to handle events received by a form or control. Called an event handler, this code determines what happens when the event occurs. Here's a very simple C# example that illustrates the basic mechanics of forms, controls, and event handlers. While this example works, some things are simpler than they really should be, so you shouldn't necessarily view this as paradigmatic for your own code.
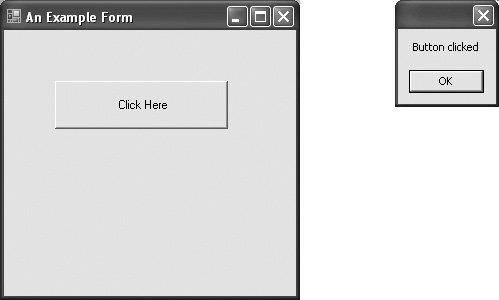
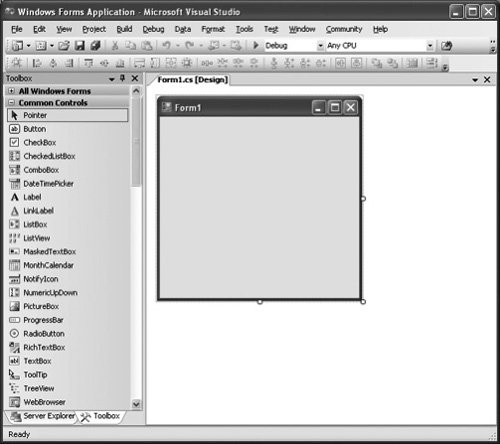
public class ExampleForm : System.Windows.Forms.Form { private System.Windows.Forms.Button myButton; public ExampleForm() { Text = "An Example Form"; myButton = new System.Windows.Forms.Button(); myButton.Location = new System.Drawing.Point(50, 50); myButton.Size = new System.Drawing.Size(175, 50); myButton.Text = "Click Here"; myButton.Click += new System.EventHandler(myButton_Click); Controls.Add(myButton); } private void myButton_Click(object sender, System.EventArgs e) { System.Windows.Forms.MessageBox.Show( "Button clicked"); } } class DisplayForm { static void Main() { System.Windows.Forms.Application.Run( new ExampleForm()); } }This example begins by declaring the class ExampleForm. Like all forms, this one inherits from System.Windows. Forms.Form. (This code contains no using statements, partly to make it shorter and partly to make clear where the various types can be found in the .NET Framework class library.) The ExampleForm class then declares a private instance of the System.Windows.Forms.Button class, one of the controls mentioned earlier, called myButton. The next thing to appear is the constructor for the ExampleForm class. The constructor is automatically run whenever an instance of this class is created, and in this example, the constructor's job is to initialize appropriately the form and the control it contains. The first step in that initialization is to set the form's Text property. The constructor then creates an instance of the Button class and sets several of its properties. Those properrties include Location, Size, and Text, all of which were described earlier. Once this is done, the constructor sets up an event handler for the Click event on myButton. This is done using EventHandler, a standard delegate provided in the System namespace. (Like events in general, the EventHandler type was described in Chapter 3.) Finally, the myButton control is added to the control collection for this form, something that must be done to allow the control's output to be displayed. Following the ExampleForm class's constructor is the method that will handle the Click event on myButton. By convention, the format of this method's name is the name of the control followed by an underscore and the name of the event: myButton_Click. This isn't required, however, and in fact any name can be used. The standard arguments to the event handler method allow learning more about the event, but they're not used in this simple example. Instead, the event handler just calls the Windows Forms MessageBox method to output a simple message. The example ends with a class containing just one methodMainwhich itself has only one statement, a call to the Run method of the System.Windows.Forms.Application class. This method provides a message loop that accepts and processes events. Passing it an instance of a form, as in this case, causes it to make that form visible when the application runs. The output of this program is shown in Figure 4-7. As you would expect, it consists of a single form containing a button with the text "Click Here." The figure shows how things look after a user has clicked the button, causing the event handler for the Click event to run. The result is the message box that appears to the right of the form. Figure 4-7. The simple application described in this section puts up a form containing a button, then displays a message box when the button is clicked. It's certainly possible to hand-code GUIs using the types in System.Windows.Forms, but only a masochist would do it. While it's useful to see a simple example to get a sense of how the mechanism works, the vast majority of Windows GUIs are created using Visual Studio 2005 or some other tool. Like its predecessors, Visual Studio 2005 provides a full-featured designer that allows dragging controls onto a form, directly setting their properties, and adding code to handle events. The full implementation is then generated automatically by this tool. Creating a GUI in this way is faster, more accurate (since you can see what you're doing), and much less error-prone. Figure 4-8 shows a basic picture of how this GUI-builder tool looks to a developer. Figure 4-8. Visual Studio 2005 provides a graphical designer for creating Windows Forms GUIs.
Windows Forms ControlsWindows Forms controls are a useful way to package reusable chunks of functionality. Although the .NET Framework class library provides a large set of controls, the inventiveness of developers knows no bounds. Accordingly, the .NET Framework makes it straightforward to write custom Windows Forms controls. As already mentioned, every Windows Forms control must inherit either directly or indirectly from the class Control. It's also possible to inherit from one of the standard controls provided with the .NET Framework class library, basing a new control on existing functionality, or to combine two controls into one new one. Whatever choice the control's creator makes, a good chunk of the work is done for her.
Windows applications built before the .NET era relied on COM-based components known as ActiveX controls. Despite being fairly complicated to create, huge numbers of these were created by third parties. Many containers capable of running ActiveX controls also exist, such as Internet Explorer. Given this large installed base of both ActiveX controls and containers for those controls, Microsoft needed to provide some way for Windows Forms controls to interoperate with this world. To use an ActiveX control in a Windows Form environment, the ActiveX Control Importer, Aximp, can be used to create a wrapper for the control. As with other parts of the .NET Framework's support for COM interoperability, this tool reads the ActiveX control's type library and produces an assembly containing analogous metadata. To allow a Windows Forms control to be used in a container that expects only ActiveX controls, the Windows Forms control can inherit from the class UserControl. This class implements everything required to make the Windows Forms control look like an ActiveX control and thus be hostable in the many ActiveX control containers that exist today. Also, because ActiveX controls are COM-based, any Windows Forms control used in this way must have an entry in the Windows registry, just as in the COM interoperability scenarios described earlier in this chapter.
Before the creation of the .NET Framework, Visual Basic 6 and C++ had completely different approaches to building GUIs. Because of this, ActiveX controls were based on COM, which allowed them to work with both languages. The predictable result was complexity. Windows Forms swept away the accumulation of GUI technologies that had built up on the Windows platform, replacing them with a single consistent approach for all .NET applications.
Installing Windows Forms Applications Remotely: ClickOnceWhich is better: a Windows Forms interface or a browser interface? The answer, of course, depends on the situation. Browsers allow access to the entire world of the Web, and since everybody knows how to click links, a browser-based application is instantly familiar to its users. Still, from a pure user interface point of view, Windows Forms applications have a lot going for them. They're much more responsive, since a round trip to a remote Web server isn't required to interact with the application, and they can also be more Windows-specific, since they're not required to adhere largely to Web standards such as HTML. Especially for people who use a custom application frequently, such as workers in a call center, these differences can be very beneficial.
Despite this, a majority of .NET applications written today target browsers. An important reason for this is the challenge of deploying new versions of native Windows applications. If anything changes in the assemblies running on clients, all client systems must be updated. Deploying a new version of a browser-based application, by contrast, typically requires updating only the server(s) on which this application runs. If installation of Windows Forms applications were easier, developers would have one less reason to build browser-based software, allowing the benefits of native Windows applications to be more widely applied.
ClickOnce, a new technology in version 2.0 of the .NET Framework, exists to make deploying and updating Windows Forms applications easier[4]. ClickOnce applications can be installed from a Web page, a shared file system somewhere on the network, or from a local device such as a CD-ROM. Once it's installed, a ClickOnce application can automatically detect when updates have occurred, then copy and install only those parts of itself that were changed. Updates or the entire installation can also be rolled back if necessary.
To allow an application to be deployed using ClickOnce, a developer creates an application manifest that describes the assemblies in this application, their dependencies, and other information. An administrator must also create a deployment manifest that indicates where to find the application manifest, where to check for updates to the application, and more. The deployment manifest is then copied to the location from which this application will be deployed, such as a Web page or file share. The application manifest, along with the application itself, might be placed at this same location or perhaps live somewhere elseboth are possible. In either case, a user accesses the deployment manifest, typically by clicking on an icon, and the installation process begins. When the application is executed, it runs in the sandbox created by the .NET Framework's code access security, which was described in Chapter 2.
Checks for updates to the application, followed by installation of any changes, are made based on an update strategy specified in the deployment manifest. By default, a ClickOnce application will check for updates in the background while the application is running. If any are found, the user will be prompted to copy and install them the next time he starts this application. It's also possible to configure the application to check for and download any updates each time it's started, or to force users to download and install updates, preventing them from running an earlier version.
ClickOnce installation doesn't require administrative permissions, and it can also do useful things such as making a newly installed application visible in the system's Start menu. Still, ClickOnce isn't appropriate for every Windows Forms application. This approach can't be used to install assemblies in the global assembly cache, for example, nor is it useful for installing device drivers. The standard Windows Installer with its MSI files is a better choice in cases like these. Yet providing the ability to update applications automatically from a remote location is a useful thing. And the simplicity this technology bringsit's not called "ClickOnce" for nothingalso makes it an attractive choice for Windows applications. Browser applications aren't going away any time soon, but the advent of ClickOnce will certainly cause some developers to lean a bit more toward building Windows Forms applications instead.
|
EAN: 2147483647
Pages: 67