Executing Managed Code
| < BACK NEXT > |
Assemblies provide a way to package modules containing MSIL and metadata into units for deployment. The goal of writing code is not to package and deploy it, however; it's to run it. The final section of this chapter looks at the most important aspects of running managed code.
Loading Assemblies
When an application built using the .NET Framework is executed, the assemblies that make up that application must be found and loaded into memory. Assemblies aren't loaded until they're needed, so if an application never calls any methods in a particular assembly, that assembly won't be loaded. (In fact, it need not even be present on the machine where the application is running.) Before any code in an assembly can be loaded, however, it must be found. How is this done?
Assemblies are loaded into memory only when needed
The answer is not simple. In fact, the process the CLR uses to find assemblies is too complex to describe completely here. The broad outlines of the process are fairly straightforward, however. First, the CLR determines what version of a particular assembly it's looking for. By default, it will look only for the exact version specified for this assembly in the manifest of the assembly from which the call originated. This default can be changed by settings in various configuration files, so the CLR examines these files before it commences its search.
The CLR follows well-defined but involved rules to locate an assembly
Once it has determined exactly which version it needs, the CLR checks whether the desired assembly is already loaded. If it is, the search is over; this loaded version will be used. If the desired assembly is not already loaded, the CLR will begin searching in various places to find it. The first place the CLR looks is usually the global assembly cache (GAC), a special directory intended to hold assemblies that are used by more than one application. Installing assemblies in this global assembly cache requires a process slightly more complex than just copying the assembly, and the cache can contain only assemblies with strong names.
The CLR looks first in the global assembly cache
If the assembly it's hunting for isn't in the global assembly cache, the CLR continues its search by checking for a codebase element in one of the configuration files for this application. If one is found, the CLR looks in the location this element specifies, such as a directory, for the desired assembly. Finding the right assembly in this location means the search is over, and this assembly will be loaded and used. Even if the location pointed to by a codebase element does not contain the desired assembly, however, the search is nevertheless over. A codebase element is meant to specify exactly where the assembly can be found. If the assembly is not at that location, something has gone wrong, the CLR gives up, and the attempt to load the new assembly fails.
The CLR can next look in the location referenced by a codebase element
If there is no codebase element, however, the CLR will begin its search for the desired assembly in what's known as the application base. This can be either the root directory in which the application is installed or a URL, perhaps on some other machine. (It's worth pointing out that the CLR does not assume that all necessary assemblies for an application are installed on the same machine; they can also be located and installed across an internal network or the Internet.) If the elusive assembly isn't found here, the CLR continues searching in several other directories based on the name of the assembly, its culture, and more.
If no codebase element exists, the CLR searches in other places
Despite the apparent complexity of this process, this description is not complete. There are other alternatives and even more options. For developers working with the .NET Framework, it's probably worth spending some time understanding this process in detail. Putting in the effort up front is likely to save time later when applications don't behave as expected.
Compiling MSIL
A compiler that produces managed code always generates MSIL. Yet MSIL can't be executed by any real processor. Before it can be run, MSIL code must be compiled yet again into native code that targets the processor on which it will execute. Two options exist for doing this: MSIL code can be compiled one method at a time during execution, or it can be compiled into native code all at once before an assembly is executed. This section describes both of these approaches.
JIT Compilation
The most common way to compile MSIL into native code is to let the CLR load an assembly and then compile each method the first time that method is invoked. Because each method is compiled only when it's first called, the process is called just-in-time (JIT) compilation.
MSIL code is typically JIT compiled before it's executed.
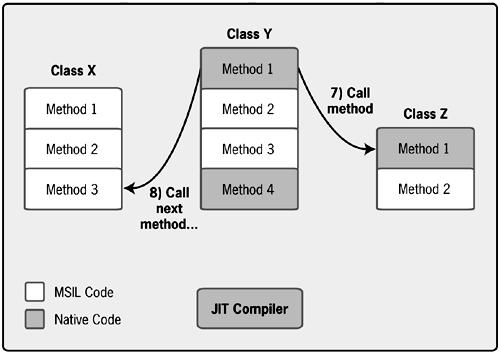
Figures 3-7, 3-8, and 3-9 illustrate how the code in an assembly gets JIT compiled. This simple example shows just three classes, once again called X, Y, and Z, each containing some number of methods. In Figure 3-7, only method 1 of class Y has been compiled. All other code in all other methods of the three classes is still in MSIL, the form in which it was loaded. When class Y's method 1 calls class Z's method 1, the CLR notices that this newly called method is not in an executable form. The CLR invokes the JIT compiler, which compiles class Z's method 1 and redirects calls made to that method to this compiled native code. The method can now execute.
Figure 3-7. The first time class Z's method 1 is called, the JIT compiler is invoked to translate the method's MSIL into native code.

A method is JIT compiled the first time it is called
Similarly, in Figure 3-8, class Y's method 1 calls its own method 4. As before, this method is still in MSIL, so the JIT compiler is automatically invoked and the method is compiled. Once again, a reference to the MSIL code for the method is replaced with one to the newly created native code, and the method executes.
Figure 3-8. When class Y's method 4 is called, the JIT compiler is once again used to translate the method's MSIL into native code.

A method always executes as native code
Figure 3-9 shows what happens when class Y's method 1 again calls method 1 in class Z. This method has already been JIT compiled, so there's no need to do any more work. The native code has been saved in memory, so it just executes. The JIT compiler isn't involved. The process continues in this same way, with each method compiled the first time it is invoked.
Figure 3-9. When class Z's method 1 is called again, no compilation is necessary.
When a method is JIT compiled, it's also checked for type safety. This process, called verification, examines the method's MSIL and metadata to ensure that the code makes no illegal accesses. The CLR's built-in security features, described in the next section, depend on this, as do other aspects of managed code behavior. Still, a system administrator can turn off verification it's not required which means that the CLR can execute managed code that is not type safe. This can be useful, since some compilers such as Visual Studio's Visual C++ can't generate type-safe code. In general, however, verification should be used whenever possible with .NET Framework applications.
Methods can be verified when they're JIT compiled
With JIT compilation, only those methods that get called will be compiled. If a method in an assembly is loaded but never used, it will stay in its MSIL form. Also, note that compiled native code is not saved back to disk. Instead, the process of JIT compilation is carried out each time an assembly is loaded. Finally, it's important to emphasize that the .NET Framework does not include an interpreter for MSIL. Executed code is either JIT compiled or compiled all at once, as described next.
Compiled code is not saved on disk
Creating a Native Image: NGEN
Instead of JIT compiling, an assembly's MSIL code can be translated into native code for a particular processor all at once using the Native Image Generator (NGEN). Contained in the file Ngen.exe, this command-line tool can be run on an assembly to produce a directly executable image. Rather than being JIT compiled one method at a time, the assembly will now be loaded as native code. This makes the initial phase of the application faster, since there's no need to pay the penalty of JIT compilation on the first call to each method. Using NGEN doesn't make the overall speed of the application any better, however, since JIT compilation slows down only the first call to a method. In general, JIT compilation should suffice for most .NET Framework applications.
NGEN allows compiling an assembly into native code before the assembly is loaded
Securing Assemblies
An assembly defines a scope for types, a unit of versioning, and a logical deployment unit. An assembly also defines a security boundary. The CLR implements two different types of security for assemblies: code access security and role-based security. This section describes both.
Code Access Security
Think about what happens when you run a traditional Windows executable on your machine. You can decide whether that code is allowed to execute, but if you let it run, you can't control exactly what the code is allowed to do. This was a barely acceptable approach when all of the code loaded on your machine came from disks you or your system administrator installed. When most machines are connected to a global network, however, this all-or-nothing approach is no longer sufficient. It's often useful to download code from the Internet and run it locally, but the potential security risks in doing this can be huge. A malicious developer can create an application that looks useful but in fact erases your files or floods your friends with e-mail or performs some other destructive act. What's needed is some way to limit what code, especially downloaded code, is allowed to do. The code access security built into the CLR is intended to provide this.
Code access security can limit what running code is allowed to do
Unlike today's typical Windows solution for controlling whether downloaded code can run asking the user the .NET Framework's code security doesn't rely on the user knowing what to do. Instead, what CLR-based code is allowed to do depends on the intersection of two things: what permissions that code requests and what permissions are granted to that code by the security policy in effect when the code executes. To indicate what kinds of access it needs, an assembly can specify exactly what permissions it requires from the environment in which it's running. Some examples of permissions an assembly can request are the following:
Code access security compares requested permissions with a security policy
UIPermission: Allows access to the user interface
FileIOPermission: Allows access to files or directories
FileDialogPermission: Allows access only to files or directories that the user opens in a dialog box
PrintingPermission: Allows access to printers
EnvironmentPermission: Allows access to environment variables
RegistryPermission: Allows access to the system registry on the machine
ReflectionPermission: Allows access to an assembly's metadata
SecurityPermission: Allows granting a group of permissions, including the right to call unmanaged code
WebPermission: Allows establishing or receiving connections over the Web
Within these general and other permissions (more are defined), finer-grained options can also be used. For example, FileIOPermission can specify read-only permission, write/delete/overwrite permission, append-only permission, or some combination of these. An assembly can also indicate whether the permissions it requests are absolutely necessary for it to run, or whether they would just be nice to have but aren't essential. An assembly can even indicate that it should never be granted certain permissions or demand that its callers have a specific set.
Fine-grained permissions are possible
There are two different ways for a developer to specify the permissions he'd like for an assembly. One option, called declarative security, lets the developer insert attributes into his code. (How attributes look in various CLR-based languages is shown in the next chapter.) Those attributes then become part of the metadata stored with that code, where they can be read by the CLR. The second approach, known as imperative security, allows the developer to specify permissions dynamically within his source code. This approach can't be used to request new permissions on the fly, but it can be used to demand that any callers have specific permissions.
An assembly can use declarative or imperative security
The Perils of Mobile CodeNobody knows better than Microsoft how dangerous code downloaded from the Internet can be. The company has received a large share of criticism in this area over the last few years. One of the first lightning rods for attack was Microsoft's support for downloading ActiveX controls from Web servers. An ActiveX control is just a binary, so if the user allows it to run, it can do pretty much anything that user is allowed to do. Microsoft's Authenticode technology allows a publisher to sign an ActiveX control digitally, but it's still up to the user to decide whether to trust that publisher and run the control. In practice, only ActiveX controls produced by large organizations (such as Microsoft itself) have seen much use on the Internet. Most people think, quite correctly, that it's too dangerous to run even signed code from any but the most trusted sources. Microsoft has received even more criticism and much more adverse publicity for e-mail-borne attacks. Various viruses have cost many organizations a lot of money, providing a very visible example of the dangers of running code received from a stranger. Yet educating the enormous number of nontechnical Windows users about these dangers is effectively impossible. Relying on the user not to run potentially dangerous code won't work. And even if we could educate every user, there would still be unintentional bugs that could be exploited by attackers. The Java world addressed this problem from the beginning. Because Java focused early on mobile code in the form of applets and because Java has always been built on a virtual machine, software written in Java could be downloaded with less risk. With the advent of the CLR, Microsoft has the opportunity to provide the same kind of sandboxing that Java offers. Both camps now offer more fine-grained control over what downloaded code is allowed to do; an all-or-nothing decision is no longer required. |
The creator of an assembly is free to request whatever permissions he wishes. The permissions actually granted to the assembly when it runs, however, depend on the security policy established for the machine on which the assembly is running. This security policy is defined by the machine's system administrator, and it specifies exactly which permissions should be granted to assemblies based on their identity and origin.
Administrators establish security policy
Each assembly provides evidence that the CLR can use to determine who created this assembly and where it came from. Evidence can consist of
An assembly provides evidence of its origins
The identity of an assembly's publisher, indicated by the publisher's digital signature on the assembly.
The identity of the assembly itself, represented by the assembly's strong name.
The Web site from which an assembly was downloaded, such as www.qwickbank.com.
The exact URL from which an assembly was downloaded, such as http://www.qwickbank.com/downloads/accounts.exe.
The zone, as defined by Microsoft Internet Explorer, from which an assembly was downloaded. Possible zones include the local intranet, the Internet, and others.
When an assembly is loaded, the CLR examines the evidence it provides. It also looks at the permissions this assembly requests and compares them with the security policy established for the machine on which the assembly is being loaded. The assembly is granted any requested permissions that are allowed by the security policy. For example, suppose an assembly downloaded from the Web site www.qwickbank.com carries the digital signature of QwickBank as its publisher and requests FileIOPermission and UIPermission. If the security policy on this machine is defined to allow only UIPermission to assemblies published by QwickBank and downloaded from QwickBank's Web site, the assembly will not be able to access any files. It will still be allowed to run and interact with a user, but any attempts to access files will fail.
The CLR determines what an assembly is allowed to do
As this simple example illustrates, permissions are checked at runtime, and an exception is generated if the code in an assembly attempts an operation for which it does not have permission. These runtime checks can also prevent an assembly with limited permissions from duping an assembly with broader permissions into performing tasks that shouldn't be allowed. An assembly can even demand that any code calling into it has a specific digital signature. Finally, note that all of the mechanisms used for code security depend on the verification process that's part of JIT compilation. If verification has been bypassed, these mechanisms can't be guaranteed to work.
An assembly's permissions are checked at runtime
While fully understanding the .NET Framework's code security takes some effort, two things should be clear. First, this mechanism is quite flexible, offering options that address a wide range of needs. Second, in a world of global networks and mobile code, providing an enforceable way to limit what code can do is essential.
Role-Based Security
Code access security allows the CLR to limit what a particular assembly is allowed to do based on the assembly's name, who published it, and where it came from. But code access security provides no way to control what an assembly is allowed to do based on the identity of the user on whose behalf the assembly is running. Providing this kind of control is the goal of role-based security.
The foundation for role-based security is a principal object. This object contains both the identity of a user and the roles to which she belongs. A user's identity is indicated by an identity object, which contains both the user's identity, expressed as a name or an account, and an indication of how that identity has been authenticated. In a Windows 2000 domain, for example, authentication might be done with Kerberos, while some other mechanism might be used on the Internet. The user's role typically identifies some kind of group the user belongs to that is useful for deciding what that user is allowed to access. For example, the fictitious QwickBank might have roles such as loan officer, teller, clerk, and others, each of which is likely to be allowed different levels of access.
A user can belong to one or more roles
Code in an assembly can demand that only users with a specific identity or a specific role be allowed to access it. This demand can be made for a class as a whole or for a specific method, property, or event. Whatever granularity is chosen, the demand can be made either imperatively or declaratively. For imperative demands, the code must make an explicit call to cause a check, while in declarative demands, the code contains attributes that are stored in metadata and then used by the CLR to check the user's identity automatically. In either case, the result is the same: The user will be granted access to this class, method, property, or event only if her identity or role matches what the assembly specifies.[3]
[3] If you're familiar with roles in COM+, the CLR's role-based security will look familiar. In fact, it's possible (although a little complex) to use both in the same application.
An assembly can use roles to limit what its users are allowed to do
Garbage Collection
The managed heap plays an important role in the execution of a .NET Framework application. Every instance of a reference type every class, every string, and more is allocated on the heap. As the application runs, the memory allotted to the heap fills up. Before new instances can be created, more space must be made available. The process of doing this is called garbage collection.
Garbage collection frees unused objects
Describing Garbage Collection
When the CLR notices that the heap is full, it will automatically run the garbage collector. (An application can also explicitly request that the garbage collector be run, but this isn't an especially common thing to do.) To understand how garbage collection works, think once again about the way reference types are allocated. As Figure 3-10 shows, each instance of a reference type has an entry on the stack that points to its actual value on the heap. In the figure, the stack contains the decimal value 32.4, a reference to the string Hello, the integer value 14, and a reference to the boxed integer value 169. The two reference types the string and the boxed integer have their values stored on the heap.
Figure 3-10. The space occupied on the heap by the object of class X is garbage.
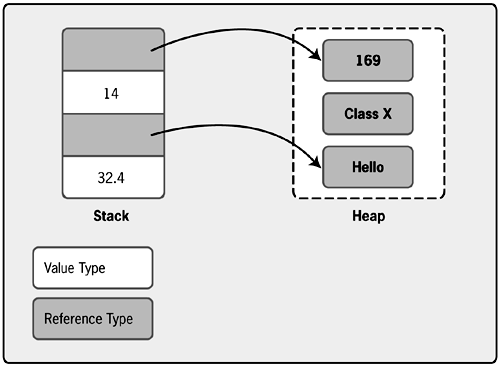
Garbage collection happens automatically
But notice that the heap also contains information for an object of class X. The figure isn't drawn to scale this object would likely take up much more space than either the string or the boxed integer but it's entirely possible that the chunk of heap memory allocated for the object would be in between the other two types. Maybe this object was created by a method that has completed execution, for example, so the reference that pointed to it from the stack is now gone. Whatever the situation, this object is just taking up space that could be used for something else. In other words, it's garbage.
Garbage objects can appear anywhere in the heap
When the garbage collector runs, it scans the heap looking for this kind of garbage. Once it knows which parts of the heap are garbage, it rearranges the heap's contents, packing more closely together those values that are still being used. For example, after garbage collection, the very simple case shown earlier would now look as illustrated in Figure 3-11. The garbage from the object of class X is gone, and the space it formerly occupied has been reused to store other information that's still in use.
Figure 3-11. The garbage collector rearranges data on the heap to free more memory.

Garbage collection can reposition the contents of the heap
As this example suggests, longer-lived objects will migrate toward one end of the heap over time. In real software, it's typical for the most recently allocated objects also to be the ones that most quickly become garbage. When looking for garbage, it makes sense to look first at the part of the heap where the most recently allocated objects will be. The CLR's garbage collector does exactly this, examining first this most recent generation of objects and reclaiming any unused space occupied by garbage. If this doesn't free up sufficient memory, the garbage collector will examine the next generation of objects, those that were allocated somewhat less recently. If this still doesn't free up enough space to meet current needs, the collector will examine all remaining objects in the managed heap, freeing anything that's no longer being used.
The garbage collector views objects in generations
Finalizers
Every object on the heap has a special method called a finalizer. When an object has been garbage collected, it is placed on the finalize list. Eventually, each object on this list will have its finalizer run. By default, however, this method does nothing. If a type needs to perform some final clean-up operations before it is destroyed, the developer creating it can override the default finalizer, adding code to do whatever is required.
An object's finalizer runs just before the object is destroyed
Note that a finalizer is not the same thing as the notion of a destructor provided in languages like C++. You can't be sure when the finalizer will run, or even if it will run (the program could crash before this happens). If an object needs deterministic finalization behavior, guaranteeing that a particular method will run at a specific time before the object is destroyed, it should implement its own method to do this and then require its users to call this method when they're finished using the object.
Finalizers are nondeterministic
Application Domains
The CLR is implemented as a DLL, which allows it to be used in a quite general way. It also means, however, that there must typically be an EXE provided to host the CLR and the DLLs in any assemblies it loads. A runtime host can provide this function. The runtime host loads and initializes the CLR and then typically transfers control to managed code. ASP.NET provides a runtime host, as does Internet Explorer. The Windows shell also acts as a runtime host for loading standalone executables that use managed code.
A runtime host is an EXE that hosts the CLR
A runtime host creates one or more application domains within its process. Each process contains a default application domain, and each assembly is loaded into some application domain within a particular process. Application domains are commonly called app domains, and they're quite a bit like a traditional operating system process. Like a process, an app domain isolates the applications it contains from those in all other app domains. But because multiple app domains can exist inside a single process, communication between them can be much more efficient than communication between different processes.
An app domain isolates the assemblies it contains
Yet how can app domains guarantee isolation? Without the built-in support for processes provided by an operating system, what guarantee is there that applications running in two separate app domains in the same process won't interfere with each other? The answer is, once again, verification. Because managed code is checked for type safety when it's JIT compiled, the system can be certain that no assembly will directly access anything outside its own boundaries.
App domain isolation depends on verification
App domains can be used in a variety of ways. For example, ASP.NET runs each Web application in its own app domain. This allows the applications to remain isolated from each other, yet it doesn't incur the overhead of running many different processes. The most recent versions of Internet Explorer, another runtime host, can download Windows Forms controls from the Internet and then run each one in its own app domain. Once again, the benefit is isolation without the expense of cross-process communication. And because applications can be started and stopped independently in different app domains in the same process, this approach also avoids the overhead of starting a new process for each application.
An app domain provides the benefits of a process without the overhead
Figure 3-12 shows how this looks. App domain 1, the default app domain, contains assemblies A, B, and C. Assemblies D and E have been loaded into app domain 2, while assembly F is running in app domain 3. Even though all of these assemblies are running in a single process, each app domain's assemblies are completely independent from those in the other app domains.
Figure 3-12. A process can contain one or more application domains.

App domains also serve another purpose. Recall that the .NET Framework is intended to run on Windows and at least potentially on other operating systems. Different systems have quite different process models, especially systems used on small devices. By defining its own process model with app domains, the .NET Framework can provide a consistent environment across all of these platforms.
App domains provide a consistent environment on multiple platforms
| < BACK NEXT > |
EAN: 2147483647
Pages: 60