Section 10.6. Cross-Domain Proxy
10.6. Cross-Domain ProxyAggregator, Fusion, Mash-Up, Mashup, Mediator, Mix, Proxy, Tunnel Figure 10-10. Cross-Domain Proxy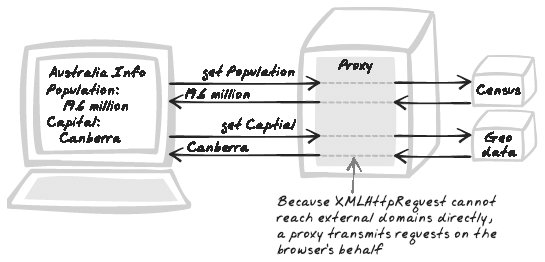 10.6.1. Developer StoryDave's working on a job-hunting web site and wants to "mash up" content from various other sites. Each job ad is accompanied by a review from a corporate forum web site, recent company news, and a stock ticker. To get these details into the browser, the server queries several sites and exposes their content as a web service that the browser can query. 10.6.2. ProblemHow can you augment your application with services available elsewhere on the Web? 10.6.3. Forces
10.6.4. SolutionCreate proxying and mediating web services to facilitate communication between the browser and external domains. As explained in XMLHttpRequest Call (Chapter 6), the same-origin policy means the browser script can only talk to the server from whence it came, which is the "base server." Hence, any communication with external domains must go via the base server. The simplest form of proxy is a dumb Web Service (Chapter 6) that simply routes traffic between browser and external server. The service can accept the remote URL as a parameter. That URL will then be accessed synchronously, and the service will output its response. All this follows the Proxy pattern (Gamma et al., 1995). A cleaner type of Cross-Domain Proxy is more closely based on the Facade or Adaptor pattern (Gamma et al.). In this case, the base server presents the interface that's most suitable to the browser script, and performs whatever manipulation is necessary to interact with the external script. For example, the external server might present a complex, over-engineered, SOAP-based RPC Service, but you want the browser to deal in simple Plain-Text Messages (Chapter 9). The likely solution is to present the plain-text Web Service, dress up requests into SOAP messages, and undress responses into Plain-Text Messages. The Facade/Adaptor approach is generally better for two reasons. First, it keeps the client simple, protecting it from dealing with the details of the protocol used to communicate with the external server. Second, it's more secure: the first approach will allow any client to call out to any server they feel like, whereas the second approach will allow you to exert much more control over what kind of communication takes place. A Cross-Domain Proxy is implemented using some form of HTTP client library to access the remote server. Generally, the connection should be quite straightforwardspecify the URL and grab the response as a string. However, it might get more complex if the remote web service relies on cookies and authentication, parameters that the proxy might have to pass on from the Ajax request that initiated the call. 10.6.5. Decisions10.6.5.1. What external content will be accessed?In theory, anything you can do with a browser can theoretically be accomplished by an automated HTTP client. However, there are likely to be legal constraints, and technical challenges too if there is serious usage of JavaScript or browser plugins. Furthermore, your script will be vulnerable to changes in the site layout, and many content providers have deliberately performed subtle changes to prevent automated access. Thus, relying on the ever-increasing collection of public APIs and structured data would make a better choice. You can find a collection of public APIs at http://wsfinder.com. Some popular APIs include Amazon, Delicious, EvDB, Flickr, Google Maps, Google Search, Technorati, and Yahoo Maps. 10.6.5.2. How will you connect to the external server?If you're scraping content directly from a public web site, you'll need to use the underlying web protocol, HTTP. And even if you're talking to an API, you'll probably be communicating with HTTP anyway. In some cases, API publishers will provide code to access the content, rather than just publishing the specification. Also, with more complex web services protocols like SOAP, you don't have to write a lot of low-level code yourself. In many cases, though, the easiest thing to do is talk HTTP and manually format and parse messages yourself. Many scripting languages feature built-in libraries to communicate in HTTP and are often well-equipped for Cross-Domain Proxy implementations due to strong support for regular expression manipulation. A PHP example is featured in the code example that follows shortly. In the Java world, for instance, the standard API provides some relatively low-level support for HTTP clients, but you can use some of the web site testing libraries to quickly extract content from external sites. HttpUnit is a good example, and it also has some support for JavaScript manipulation. To grab some content: import com.meterware.httpunit.WebConversation; import com.meterware.httpunit.GetMethodWebRequest; import com.meterware.httpunit.WebRequest; public class PatternSorter { public String getContent(String url) { try { WebConversation wc = new WebConversation( ); WebRequest request = new GetMethodWebRequest(url); String response = wc.getResponse(request).getText( ); } catch(Exception ex) { throw new RuntimeException("Could not get content from " + url, ex); } } public static void main(String[] args) { System.out.println("http://ajaxpatterns.org"); } } 10.6.5.3. How will you deal with errors and delays in accessing the service?At times, there will be errors accessing an external web service. Think twice before attributing blame because the problem might be at your end, or somewhere along the network. This has implications for any error messages you might show users. Ideally, you should be able to detect that an error has occurred, and then log the details for immediate attention. In responding to the user, you have several options:
10.6.5.4. Under what licensing terms will you access the remote service?The legals of invoking Web Services (Chapter 6) are tricky, vaguely-defined, and always evolving. Some services are open for public use, others require you hold an API key, and others are critical enough to warrant authentication via digital signatures. In each case, there are usage terms involved, even if they're not explicit, and you will need to investigate issues such as the authentication mechanism, the number of queries per day, how the data will be used, server uptime, and support level. 10.6.6. Real-World Examples10.6.6.1. WPLicenseThe WPLicense Wordpress plugin (http://yergler.net/projects/wplicense) presents the blogger with some forms to specify their preferred license statement, based on the Creative Commons model. The server is acting as a middleman between the browser and the Creative Commons API (http://api.creativecommons.org/rest/1.0/). 10.6.6.2. Housing Maps (Craigslist and Google Maps)Housing Maps (http://housingmaps.com) is a mashup between Google Maps (http://maps.google.com) and Craigslist (http://craigslist.com), a community-oriented classifieds advertising web site. What does that mean? It means you get to see a list of advertised homes on one side and view a map of those homes one the other side, using the familiar Google Maps thumbtacks to pinpoint the locations of the advertised homes. (See Figure 10-11.) Figure 10-11. Housing Maps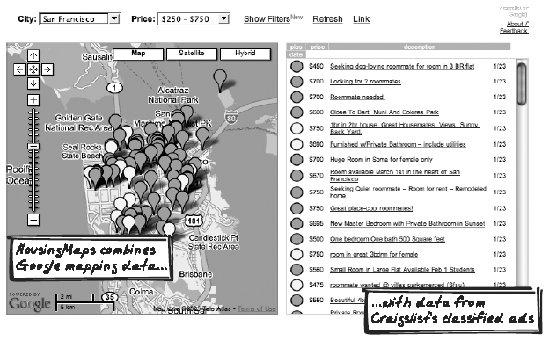 A few features:
Cross-Domain Proxy is used to grab housing data from Craigslist, while the map images are fetched directly from Google's server into the browser. 10.6.6.3. Bill Gates Wealth ClockThis was not Ajaxian, but noteworthy as the first prominent mashup application and a precursor to the Ajaxian Cross-Domain Proxy pattern. Web guru Philip Greenspun mixed data from several sources to produce a "wealth clock" showing Bill Gates' worth at any time (http://groups-beta.google.com/group/nf.general/browse_thread/thread/bc7fc7bfab19937f/88fa32f2cf6dd6bb). This is no longer working, unfortunately (http://rhea.redhat.com/bboard-archive/webdb/0006ad.html), but the code is still available (http://philip.greenspun.com/seia/examples-basics/wealth-clock.tcl.txt). See Figure 10-12. Figure 10-12. Bill Gates Wealth Clock The price per stock was extracted from Yahoo! Finance. The number of stocks in Gates' portfolio came from Microsoft reports (it was not automatically extracted). And the U.S. population came from the U.S. Census Bureau. Here's what Greenspun said back in 2001 (http://philip.greenspun.com/teaching/teaching-software-engineering):
Another prominent usage of Cross-Domain Proxying in "Web 1.0" was meta-searching, as performed by crawlers such as MetaCrawler.com (http://metacrawler.com). Again, all the work was done in the server, and the browser response was usually opened while the results came back to the server, so at least some information could be shown while requests were still out. 10.6.6.4. CPaint libraryCPaint (http://cpaint.sourceforge.net/:) is a Web Remoting (Chapter 6) library. A special "proxy" URL can be established (http://cpaint.sourceforge.net/doc/frontend.class.cpaint.set_proxy_url.html), pointing to a proxy on the originating server, so that remoting to external domains has virtually the same API as to the originating server. 10.6.7. Code Example: WPLicenseSee the Code Example in Live Form (Chapter 14) for a full background on the WPLicense's license selection process, but here's a quick summary:
What all this glosses over is the Cross-Domain Proxy pattern that goes on behind the scenes. At each of these three stages, the server is actually interacting with CreativeCommons.org via its public API (http://api.creativecommons.org/rest/1.0/), which you can read about at http://api.creativecommons.org. The plugin provides a clean separation between web server logic and cross-domain mediation: a separate PHP file (ccwsclient.php) hosts several API facade operations, accepting and returning data structures in standard PHP style. This client in turn delegates all the XML infrastructure stuff to a third-party library MiniXML, at http://minixml.psychogenic.com. Let's now zoom in on the three steps. 10.6.7.1. 1. Retrieving license typesThe server doesn't have the license types hardcoded. Instead, it retrieves them via a web service. This is the core of the Cross-Domain Proxy functionalitythe PHP function fs will retrieve content from the specified URL: $WS_ROOT = "http://api.creativecommons.org/rest/1.0/"; ... $xml = file_get_contents($WS_ROOT); In fact, you can see exactly what's pumped into $xml by visiting http://api.creativecommons.org/rest/1.0/, and then choose View Page Source. Alternatively, use a command-like application such as curl (curl http://api.creativecommons.org/rest/1.0/), which yields the following XML (reformatted): <licenses> <license >Creative Commons</license> <license >Public Domain</license> <license >Sampling</license> </licenses> Once we know what license types are available, it's a matter of transforming the XML into an HTML selector. XSLT could be used here, but it's just as easy to do it manually: foreach($license_classes as $key => $l_id) { echo '<option value="' . $key . '" >' . $l_id . '</option>'; }; 10.6.7.2. 2. Retrieving license questionsPresenting the questions gets interesting, because the server must now present questions and accept answers without the programmer knowing in advance what those questions will be. Browser requests for license questions invoke a URL that depends on the user's chosen license type. If the license type is Creative Commons, which has the ID "standard," the URL is http://api.creativecommons.org/rest/1.0/license/standard/. Visit that URL, and you'll see the questions and possible answers. For example: <field > <label xml:lang="en">Allows modifications of your work?</label> <description xml:lang="en">The licensor permits others to copy, distribute and perform only unaltered copies of the work, not derivative works based on it.</description> <type>enum</type> <enum > <label xml:lang="en">Yes</label> </enum> <enum > <label xml:lang="en">ShareAlike</label> </enum> <enum > <label xml:lang="en">No</label> </enum> </field> Equipped with all that information about each question, the server must now transform it into an HTML selector. Ultimately, a loop is used to traverse the entire data structure and generate a selector for each field: foreach ($fields as $f_id=>$f_data) { $result .= '<tr><th><nobr>' . $f_data['label'] . '</nobr></th><td>'; // generate the appropriate widget if ($f_data['type'] == 'enum') { $result .= '<select lic_q="true" size="1">'; foreach ($f_data['options'] as $enum_id=>$enum_val) { $result .= '<option value="'. $enum_id . '">' . $enum_val . '</option>'; } // for each option ... As explained in the Live Form (Chapter 14) discussion, this new form HTML is directly placed onto a div. 10.6.7.3. 3. Handling user answersThe Creative Commons' issueLicense web service accepts XML input of all the license criteria, and then outputs a document containing a URL for the license criteria, along with some other, related information. In a similar manner to the previous code, all of this information is transformed into HTML. This time, it's used to populate several fields, rather than generate any new input fields. 10.6.8. Alternatives10.6.8.1. On-Demand JavaScriptA fairly old cross-domain technique is to use On-Demand JavaScript; see the discussion of Cross-Domain Loading for that pattern in Chapter 6. The main benefit over Cross-Domain Proxy is reduced resourcesthe base server is bypassed, so there's no bandwidth or processing costs involved. However, there's a major constraint: the server must expose a suitable script to fetch, because it's not possible to just extract arbitrary information from a server. Additional problems include lack of server-side logging, inability to reach services that require authentication, and the security concerns described in On-Demand JavaScript. 10.6.8.2. Shared document.domainWhen we speak of the "same-origin" policy, we're not necessarily referring to the true domain a document is served from; each document has a mutable domain property (for example, document.domain) that turns out to be the critical factor in cross-domain calls. If two documents declare the same domain property, regardless of their true origin, they should be able to communicate with each other using XMLHttpRequest. Jotspot developer Abe Fettig has explained how to exploit this knowledge for making cross-domain communication practical (http://fettig.net/weblog/2005/11/28/how-to-make-xmlhttprequest-connections-to-another-server-in-your-domain/XMLHttpRequest Call). The trick relies on embedding the external document and having that documentas well as your own documentdefine the same document.domain property. Thus, as with the On-Demand JavaScript alternative, it does have one key constraint: the external server must explicitly cooperate. In addition, you can't just declare an arbitrary domain; it has to be a "parent" of the true domain (http://www.mozilla.org/projects/security/components/same-origin.html; i.e., "shop.example.com" can declare "example.com" but not "anyoldmegacorp.com". Due to these constraints, it's best suited to a situation where there's a direct relationship between the respective site owners. 10.6.8.3. ImagesImages have always worked across domains, with various benefits (syndication) and more than a few problems ("bandwidth theft") along the way. As noted in the "Alternatives" section of XMLHttpRequest Call (Chapter 6), images can be used for general-purpose remoting, usually with 1-pixel images that will never be rendered. While that's a hack you'll likely not need these days, transfer of legitimate images remains a useful capability. When you run the Google Maps API (http://www.google.com/apis/maps/) in your web page, for example, it pulls down map images directly from Google's own servers. 10.6.9. Related Patterns10.6.9.1. Performance Optimization patternsSince external calls can be expensive, the Performance Optimization patterns apply. They may be applied at the level of the browser, or the server, or both. For example, caching can take place in the browser, the server, or both. 10.6.10. Want to Know More?See WSFinder: a wiki of public web services (http://www.wsfinder.com/). |