Section 9.1. RESTful Service
9.1. RESTful ServiceAPI, HTTP, REST, Standard, Universal, Web Figure 9-1. RESTful Service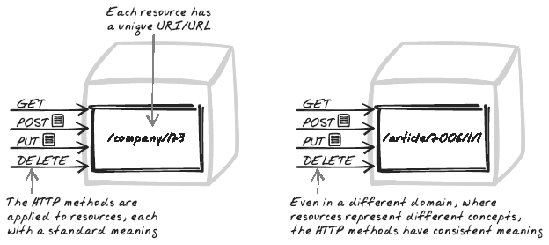 9.1.1. Developer StoryDevi's producing a public web site explaining pharmaceuticals to the public. The browser applications will pull down drug data from the server, and authorized userssuch as drug manufacturerswill be allowed to upload new information. It's envisioned that third-party applications will also connect to the web server and provide their own user interfaces. For example, pharmacies will be able to use the information via their point-of-sale systems, and doctors will have access from their specialized consulting software. Devi opts to follow a RESTful architecture for all of the services exposed on the server. This makes it easy for the browser side of her own web app to access the data and exposes services in a standardized manner. 9.1.2. ProblemHow do you expose services on the Web? 9.1.3. Forces
9.1.4. SolutionExpose web services according to RESTful principles. Representational State Transfer (REST) is an architectural styleor "pattern"guiding the architecture of web services. Like "Ajax" itself, "REST" is a broad term and can be broken down into many smaller patterns and idioms (enough to fill up an entire book!). The explanation here can't possibly do justice to the entire concept, but it's worthwhile being familiar with the general principles of REST. Because REST is such a large topic, be prepared for the reality that most real-world systems you'll encounter are only somewhat RESTful; they'll follow some principles and break others. Some people are now making the distinction between "High REST"sticking closely to RESTand "Low REST"following just a couple of core REST guidelines (http://lesscode.org/2006/03/19/high-low-rest/). 9.1.4.1. Motivating REST: many ways to skin a callTo motivate REST, let's consider a football service. Sufficiently authorized clients can read game records, upload new games, correct existing games, or delete games. We'll assume your backend's already written, but how would you offer it as a web service? How will client developers call it, and how will they learn about its interface? To wit, following are a few random ways you might expose a game servicenote that these aren't necessarily RESTful!
And we could go on. And then we could look at the other functions here. The point is this: as a service designer, you have many options for representing a single function. Is that, in itself, a problem? You might argue it's not a problem at alljust choose any old option, using some darts and a blindfold if need be. Then just create the service and document its usageany competent developer will then be able to deal with it, right? That argument, however, is flawed on several counts:
So we've seen the argument for a convention-based approach to web services, but what's the convention? REST is one such convention, consisting of many different guidelines, that has broad industry support. Just about any functionality can be presented as a RESTful API, and by doing so, it gains the advantage of a familiar, intuitive style. Many services on the Net already follow RESTful principles, to differing degrees. Also, many real-world entities such as browsers and caches tend to assume REST. These entities work better if REST is in placea browser, for instance, might give better feedback; a cache will retain all the data that the programmer expected it to retain. And what will happen if REST is not in place? It's probably not the end of the world, but you'll find little things will go wrong and work in unexpected ways. For instance, hitting the browser's Reload button might cause a purchase order to be resubmitted. Or a cache might end up caching data it shouldn't, or it might not cache any data at all. Why these unfortunate events might occur will become clear as we learn about the RESTful principles. 9.1.4.2. Introduction to RESTful principlesSo much for abstract motivation: what exactly are the RESTful principles (http://www.xfront.com/REST-Web-Services.html) all about? REST ultimately presents the server as a big blob of "resources" such as people, cars, or football games. Clients interact by inspecting and changing that state. Putting a purchase order on the server, for example, will trigger the server to affect the purchase described in the order. This contrasts with the Remote Procedural Call (RPC) approach, where the client would call a remote purchase( ) procedure. REST is based on data manipulation, RPC is based on procedural calls. REST sees the universe as consisting of resources and operations performed on, and with, those resources. The resources and the operations can be represented as the HTTP concepts of URLs and call methods.
Another way to say it is in HTTP, any request a client can make involves a URL and an HTTP method. With REST, the URL is designed to represent a noun and the HTTP method always maps to one of several standard verbs, which will be performed against that noun. How is the URL combined with the HTTP methods in practice? Returning to the example, a game is clearly an entity in this API. So REST says we create a scheme to expose each particular game as a unique URLfor example, http://example.com/games/995. So far, this is all pretty unequivocal. Anyone familiar with REST will always be driven to create a unique URL for each game. There might be differences of opinion about the precise naming, but the basic concept will always be the same if you follow REST. Now that we have this unique URL, we can implement many functions around it, by leveraging the standard HTTP methods (http://rest.blueoxen.net/cgi-bin/wiki.pl?RestFaq#nid1UP).
In summary, each HTTP method will cause a well-defined action on the resource represented by the URL it operates on. The methods can be compared to SQL commands: GET is like "SELECT," DELETE is like "DELETE," POST is like "INSERT" with an auto-generated ID, and PUT is like "INSERT OR UPDATE IF EXISTS" with an ID specified. Again, notice how most of this is unequivocal. True, you still have to decide on a precise URL convention and message formats, but that's fairly minimal. Just by declaring "this is a REST interface," you're conveying many implicit rules to a REST-savvy developer. Inform that developer of the URL and message conventions, and they'll be able to intuit most of the API. Compare that to an ad hoc, roll-your-own API, where each detail must be explained piecemeal. Considering that there are thousands of web services out there, it soon becomes clear why REST is an attractive option. 9.1.5. RESTful principlesLet's now look at the main REST principles in more detail. 9.1.5.1. URLs reflect resourcesAs explained in the previous section, each resource receives a unique URL. URLs generally look like nouns. REST doesn't tell you what names to call your resourcesthere are infinite possibilities and the choice is up to you. They'll often reflect your conceptual model of the system and look similar to your database table names. 9.1.5.2. HTTP methods reflect actionsWith REST, each HTTP method indicates the kind of action to be performed. Moreover, the REST API designer doesn't have to decide what each method means, because there are only a handful of methods, and REST standardizes the meaning of eachGETs for queries, POSTs for inserts, and so on, as explained above. Notice how resource names are not standardized in the same way. Businesses have different models, so you can't standardize on those things. But REST is saying that you can indeed model the resources so that the set of required actions is standard, thus ensuring APIs are consistent with one another. Fortunately, the standard HTTP methodswhen combined with a well-designed URL and resource schemeare enough to let a client express just about anything it needs to. It's true that in an ideal world, there would be a few extra actions to make life a bit easier. For example, it would be convenient if there was a standard LOCK action to let a client deal exclusively with a particular resource.[*] However, you can still work around this by introducing a lock resource and letting clients lock things by manipulating those resources with the standard HTTP methods.
9.1.5.3. GET for queries, and only for queriesRefining the previous point, GET calls must be read-only. When you perform a read-only query of any kind, always use GET. Conversely, when your call will affect any data on the server, use one of the other methods: PUT, POST, and DELETE all change state. There are some caveats herefor example, if issuing a query ends up leaving a log message somewhere, does that constitute a change? Technically, yes; but common sense says no, it's not a significant change to the underlying resource, so it's acceptable to log the message in response to a GET request. Just be aware that the log might not read as intended; for instance, some clients will get the content from a cache, which means no log message will occur. The reverse problem can happen too. GET requests are often cached, but the other types of requests are not. When you perform a query with POST, you deny the possibility of caching in the browser, within the client's network, or on your own server. If you learn nothing else about REST, be sure to learn this guideline; of all the REST conventions, this is the best known and widely applied across the net (see the sidebar "The Backpack-Accelerator Incident" in this chapter).
9.1.5.4. Services should be statelessIn stateful interaction, the server remembers stuff from the past. For example, you could do this: Greg's Browser: Give me the next game to work on. Server: Work on game 995. ... Greg's Browser: Here's the result: bluebaggers 150, redlegs 60. Server: Thanks. (Server stores "bluebaggers 150, redlegs 60" for game 995.) The server here has an implicit conversational state; it remembers the game Greg's working on. That makes testing harder, because you have to set the whole history up to test any particular interaction. Another problem is the fragile nature of the transaction; what if Greg's browser fails and ends up requesting two different games? When Greg uploads the score, the server could easily misinterpret which game he's talking about. Also, you can't cache effectively because a query result might depend on something that happened earlier. Furthermore, an objective of REST is to be able to switch clients at any time and receive the same result. If you switch "Greg's Browser" to "Marcia's Browser," the server will respond differently to the game result above, because it will assume Marcia's Browser is working on a different game number. While users are unlikely to switch browsers mid-conversation, other clients like caches and robots may well switch. Substitutability makes networks more scalable. The upshot is that everything should be passed in at once. It's okay for the client to remember details about the conversationREST says nothing about the client's activitybut the server must not. The server responses should be based on the server's global state and not on the state of the conversation; i.e.:
So are cookies used at all? Yes, cookies can be used, but mainly for authentication. They should only determine whether or not the server will accept a call, by not in any way how the server will respond. If authentication fails, an appropriate response, such as a 401 (Forbidden) header, will result. If authentication succeeds, the same call will always have the same effect, independent of the client who made the call. So if Greg's Browser says "Get All Games," Greg will see exactly the same thing as if the all-powerful administrator asked for the same thing, as long as Greg's allowed to see them. If the security policy forbids Greg from seeing all games, Greg's query will be denied. What won't happen is for Greg to receive just a minimal list of his own gamesif that happened, the server would be using the cookie to determine the browser's response. To get a minimal list, the query must be explicit"Get All of Greg's Games"and of course, it must be Greg or the administrator that issues this request. If Marcia made that request, she'd get an authentication error. An alternative to cookies is to use HTTP Basic Authentication, but this doesn't work too well in an Ajax context, because you don't have any control over the UI. The browser will typically pop up a dialog box, whereas you probably want to integrate any authentication directly into the interface, especially if using a pattern like Lazy Registration. HTTP Digest Authentication does allow more flexibility, but browser and server support is limited. Thus, while HTTP authentication is seen as "more pure," cookies are a reasonable workaround, provided you use them only for authentication. 9.1.5.5. Services should be idempotent"Idempotent" means that once you pass a message to service, there's no additional effect of passing the same message again. Consider the deletion message, "Delete Game 995." You can send it once, or you can send it 10 times in succession, and the world will be the same either way. Likewise, a RESTful GET is always idempotent, because it never affects state. The basic conventions on GET/DELETE/PUT/POST, described earlier, are intended to support idempotency. 9.1.5.6. Services use hyperlinksIn resource representations returned by GET queries, use hyperlinks liberally to refer to related resources. With judicious use of hyperlinks, you can and should break information down. Instead of providing one massive response, include a modicum of information and point to further information using resource identifiers. 9.1.5.7. Services documents themselvesRESTful services can and should document themselves. The exact mechanism is not well-defined. But a couple of examples include:
9.1.5.8. Services constrain data formatsAs an extension to the previous point, RESTful services rely on standards such as Document Type Definitions (DTDs) and XML Schema to verify data formats as well as to document what's acceptable. 9.1.5.9. Handling arbitrary transactionsThe REST definition is especially geared for creatingsuch as Amazonreading, updating, and deleting (CRUD) operations. How about transactions and arbitrary actions, such as "Pause the printer" or "Email the catalogue to this user"? By definition, application-specific actions don't fit neatly with the standard REST actions. There will always be some pragmatic judgment required as to a suitably RESTful interface. A few possibilities have been mooted, with viewpoints varying (http://rest.blueoxen.net/cgi-bin/wiki.pl?VerbsCanAlsoBeNouns):
9.1.5.10. Weighing Up RESTBeing a broad architectural style, REST will always have different interpretations. The ambiguity is exacerbated by the fact that there aren't nearly enough standard HTTP methods to support common operations. The most typical example is the lack of a search method, meaning that different people will design search in different ways. Given that REST aims to unify service architecture, any ambiguity must be seen as weakening the argument for REST. Another issue is portability while GET and POST are standard, you may encounter browsers and servers that don't deal consistently with DELETE, PUT, and other methods. The main alternative to REST is RPC (see RPC Service, later). It's equally broad in definition, but the essential idea is that services are exposed at procedures. You end up POSTing into verb-like URLs such as /game/createGame?gameId=995 instead of RESTful, noun-like URLs such as /game/995. In fact, the distinction is significant enough that some service providers, such as Amazon, actually provide separate APIs for each. As a general rule, any set of services could be exposed as either REST or RPC; it's just a question of API clarity and ease of implementation. Note also there is some overlap; as discussed in the RPC Service solution, RPC can still follow certain RESTful principles. From an implementation perspective, REST and RPC differ in that REST requires some explicit design, whereas RPC tends to follow directly from the backend software model. In the example, it's likely there will be a Game class with a createGame( ) methodthat's just how most server-side software gets done. So it's a no-brainer to tack on a /game/createGame web service that mediates between the client and the backend method. In fact, there are many frameworks that will completely automate the process for you. With REST, there's no direct mapping between web service and backend implementationan impedance mismatch. You need to take a step back and explicitly design your API to be RESTful. If you're following feature-driven design, the API is the first thing you'll produce anyway, since the design will be "pulled" by the needs of clients, rather than "pushed" from the available technology. Once you've designed the API, the web service implementation will effectively be a kind of middleware Adaptor (see Gamma et al., 1995) to the backend services. To summarize crudely:
9.1.6. Real-World ExamplesI'm not aware of any Ajax Apps that access a truly RESTful interface on the server side. Consequently, the example here is a public API that conforms closely to REST. Note that several prominent industry interfaces are not covered here, because though they promote themselves as RESTful, they tend to break quite a few basic principlesfor example, Amazon's REST API (http://rest.blueoxen.net/cgi-bin/wiki.pl?HowAmazonsRESTComparesWithREST). In industry parlance, REST is sometimes synonymous with "not SOAP," and it's incorrectly assumed that an interface is RESTful as long as it uses GET for reads and POST for writes. 9.1.6.1. Blogger APIAtom is a feed protocol built around RESTful principles. Blogger offers a good description on its use of Atom in its public API (http://code.blogger.com/archives/atom-docs.html). The API lets third-party applications read and change Blogger blogs. Blogger themselves could theoretically build an Ajax App that directly calls on the API. A blog entry is one important resource in Blogger's API. For example, entry ID 1000 for user 555 "lives at" http://blogger.com/atom/555/1000. So to read that entry, just issue a GET on that URL. To change the entry there, just PUT an XML document to the same URL. To add a new entry, you don't yet know its ID, so you POST to a URL containing only the user IDfor example, http://blogger.com/atom/555. Note that each of these operations uses HTTP Basic Authentication and runs over HTTPS. 9.1.7. Code Example: AjaxPatterns RESTful Shop DemoThe Basic Shop Demo (http://ajaxify.com/run/shop/) employs an ad hoc web service to expose and manipulate store items and user shopping carts. In this demo, the cart service is refactored to become more RESTful. You can contrast this to the Refactoring Illustration in RPC Service. Note that some constraints make the RESTful service less than ideal here:
There are three resources: categories, items, and carts. GET is used to read each of these. Only carts can be modified, either by adding an item or clearing the cart. Both of these are handled by POST rather than PUT, since they are changes rather than replacements. Let's look at each service in more detail. 9.1.7.1. Reading categories listAn XML list of categories is exposed by GETting http://ajaxify.com/run/shop/categories.phtml. Here, categories is the resource and the HTTP method is GET since we're reading the resource. To avoid listing all category information here, there's a link to each specific category resource: <categories> <category xlink="http://ajaxify.com/run/shop/rest/category.phtml?name=Books"> Books</category> <category xlink="http://ajaxify.com/run/shop/rest/category.phtml?name=Songs"> Songs</category> <category xlink="http://ajaxify.com/run/shop/rest/category.phtml?name=Movies"> Movies</category> </categories> 9.1.7.2. Reading an individual categoryTo drill down to an individual category, say "Movies," you GET http://ajaxify.com/run/shop/category.phtml?name=Movies, which provides the name and items. Since an item is defined solely by its name, and we can't perform operations on items themselves, there's no need to give it a URL. <category> <name>Movies</name> <item>Contact</item> <item>Gatica</item> <item>Solaris</item> </category> As the system scales up, the list of all items gets excessive for someone who just wants to know the category name. So the next service provides just the items. If we want, we could then remove the list of items in the category name. 9.1.7.3. Reading cart contentsBeing RESTful, we can't just access the shopping cart out using the current sessioneach operation must specify the cart's owner. The session is used here, but only for authentication. To read the shopping cart of user 5000, we GET http://ajaxify.com/run/shop/rest/cart.phtml?userId=5000: <cart user> <item> <name>Hackers and Painters</name> <amount>2</amount> </item> <item> <name>Accidental Empires</name> <amount>4</amount> </item> </cart> To test the authentication, visit the web app http://ajaxify.com/run/shop/rest and add a few items. Cut and paste your assigned user ID over the "5000" in the above URL. You'll be able to see your cart. Then try a different user ID, say 6000, and you'll be greeted with the following message along with a 401 (Forbidden) header: You don't have access to Cart for user 6000. 9.1.7.4. Changing cart contentsBeing RESTful, the cart URL remains the same whether we're manipulating or reading it. So when we make changes to user 5000's cart, we use the same URL as for reading it, http://ajaxify.com/run/shop/rest/cart.phtml?userId=5000 (which would instead end with the cleaner /cart/5000 if we could use URL-rewriting). To update the cart, we simply PUT a new cart specification to the cart's URL. If the user's just cleared the cart, the following will be uploaded: <cart> </cart> If the user's added an item, the browser still does the same thing: just upload the whole cart; e.g.: <cart user> <item> <name>Hackers and Painters</name> <amount>2</amount> </item> <item> <name>Accidental Empires</name> <amount>5</amount> </item> </cart> Note that working with PUT is quite similar to working with POST. As explained in XMLHttpRequest Call (Chapter 6), XMLHttpRequest has a requestType parameter. In the example here, the details are in any event abstracted by the AjaxCaller wrapper library: ajaxCaller.putBody("cart.phtml?usertext/xml", cartXML); How to mail the cart contents is more subjective, as discussed in the "Arbitrary Actions" section in the Solution. The approach here is to post an email address to the cart URL, e.g.: <email-address> ajaxmail@example.com </email-address>
9.1.8. Alternatives9.1.8.1. RPC ServiceRPC Service (see later in this chapter) is an alternative to RESTful Service, as highlighted earlier in the "Solution." 9.1.9. Related Patterns9.1.9.1. XML MessageXML Messages (see later in this chapter) are often used as the format of a REST service's response, and sometimes its input as well. XML fits well here because it's standards-based, broadly supported and understood, self-documenting, and capable of self-verifying when used with DTDs and XML Schemas. XML Messages tend to appear as the body of PUT and POST calls as well as in responses. 9.1.9.2. XML Data IslandA RESTful transaction often involves passing a resource back and forth, with each side augmenting its state. For instance, a server can deliver an initially empty shopping cart, the client can add an item to it, the server can set the total price, and so on. Instead of transforming to and from a custom data structure, it sometimes makes sense for the browser to retain the incoming XML Messages in an XML Data Island (Chapter 11) and transform it according to the interaction. 9.1.9.3. Unique URLsUnique URLs (Chapter 17) also relates to URL design, though they differ in scope. Unique URLs relates to the URLs of the Ajax App itself, while RESTful Service involves the URLs of web services it uses. It's sometimes said that "Ajax breaks REST" because many Ajax Apps have a single URL regardless of state. Ironically, though, Ajax actually facilitates REST by encouraging a clean API to service the browser application. As for the browser application, Unique URLs do help make an Ajax App a bit more RESTful, though that's somewhat beside the point since it's the web services that a client would want to use. 9.1.10. MetaphorREST is often likened to Unixwith its consistent usage of pipes and filtersand to SQLwith its standard persistence and querying commandsbut can also be compared to Windows-based GUI platforms. There are standard actions like "Cut," "Paste," and "Popup Context Menu." Each object (e.g., documents, icons, and folders) accepts such actions and interprets them in a manner consistent with the action's meaning. 9.1.11. Want To Know More?
9.1.12. AcknowledgmentsThanks to Tony Hill from the Thomson Corporation for reviewing this pattern and providing some great insights into REST. |