Measuring Network Performance
| Performance management is an umbrella term that actually incorporates the configuration and measurement of distinct areas. This section discusses four areas of performance that are useful for measurement in distributed networks:
AvailabilityAvailability is the measure of time for which a network system or application is available to a user. From a network perspective, availability represents the reliability of the individual components in a network. Different events can interrupt the reliability of network devices:
Unlike the mainframe world, accurately measuring the availability of a distributed network is extremely difficult and not very practical. This would require measuring the availability of services from every point in the network to every other point in the network, or measuring from the perspective of one or more polling stations. If a polling station fails or becomes disconnected, data will become missing and lead to skewed availability reporting. Measuring availability requires coordinating real-life measures (phone calls from the help desk) with the statistics collected from the managed devices. The availability tools cannot capture all occurrences that may keep a packet from getting to its destination. For instance, perhaps a network operator erroneously modifies an access list by entering the wrong TCP port number and filtering SMTP (email) instead of another protocol. As a result, all email to a particular set of servers is no longer accessible and users are affected. However, the availability tools report that the affected router and its interfaces are up and passing packets. This example demonstrates the difference between network device availability and service availability. Even if measurements may indicate a certain level of network availability, the reality may indicate something different. In this case, the network device and routes are available, but the particular service (email) is not. Another factor to consider when measuring availability is network redundancy. The failure of a particular port may not be as important if a redundant path is available the traffic routes around the failure. However, with certain technologies, redundant paths can be used for traffic load balancing, as opposed to having one link operational and one link in standby (doing nothing). As a result, if one of the links fails, the traffic still has a route to take, but the overall capacity of the path may be diminished, perhaps in half. Rather than being down, the loss of redundancy indicates a decrease in service. The result, depending on the technology and traffic load, may be slower response time and perhaps loss of data due to dropped packets. These results will show up in the other areas of performance measurement such as utilization and response time. Different methods exist to measure availability in a distributed network that can provide approximate representation without the complexity. Each method varies in implementation difficulty, and thus varies in the reported results. The key is to implement one method and use it consistently across your network. Implementation is discussed next. Measuring AvailabilityAccording to Stallings (Stallings 1996), availability is expressed by the mean time between failures with the following formula:
where MTTR is Mean Time To Repair. Please refer to Stallings (Stallings 1996) for mathematical examples that use this approach for measuring availability in both redundant and non-redundant connections. We recommend the following practical approach to begin monitoring availability in your network. This method is similar to those methods used by network management stations that indicate device availability through GUI maps. ICMP pings are the easiest to use and report on when measuring availability. Equation 4-1 shows the relevant formula: Equation 4-1
Here's how to implement availability measuring in your network using ICMP pings:
NOTE If you are held responsible for meeting a Service Level Agreement, it may be important to take scheduled outages into account. These outages could be the result of moves, adds and changes, plant shutdowns, or other events that you may not want reported. Typically, accurately measuring outages is not an easy task and may actually be manual in nature. Response TimeNetwork response time is the time required for traffic to travel between two points, and is typically measured for a round trip the time it takes a packet to reach its destination and a response to return to the source. Slower than normal response time can indicate congestion or a network fault, for instance if a redundant network connection goes down. Response time is the best measure to gauge how users perceive the network's performance. Users get frustrated as a result of delayed traffic. No matter what the source of the slow response is, user reaction is usually "the network is slow." With distributed networks, many factors affect the response time. Some examples include the following:
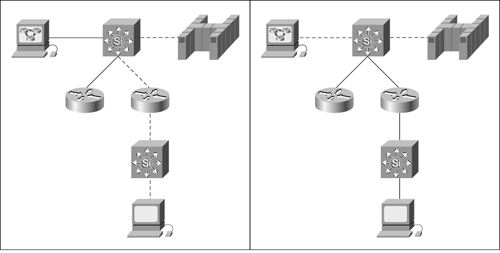
For networks employing QoS-related queuing (such as priority or custom queuing), response-time measurement is important for determining whether types of traffic are moving through the network as expected. For instance, when implementing voice traffic over IP networks, voice packets must be delivered on time and at a constant rate in order to keep the call from sounding horrible. By generating traffic classified as voice traffic, you can measure the response time of the traffic as it appears to users. Measuring response time helps resolve the battles between server and network folks. Network administrators find themselves in the position of being presumed guilty rather than innocent when an application or server appears to be slow. The network administrator is then in the position of having to prove that the network is NOT the problem. Response time data collection provides an indisputable means for proving or disproving that the network is the source of application troubles. You should measure response time as it appears to users. A user perceives response as the elapsed time from when they press Enter or click a button until the resultant screen displays. This elapsed time includes the time required for each network device, the user workstation, and the destination server to process the traffic. Unfortunately, measuring at this level is nearly impossible due to the number of users and lack of tools. Further, incorporating user and server response time provides little value when determining future network growth or troubleshooting network problems. You can use the network devices and servers to measure response time. Through the use of ICMP or related mechanisms, you can measure the time a transaction takes; this approach provides a usable approximation of response time for an IP packet. It does not take into effect (nor is it designed to) the delays introduced in a system as the packet gets processed by the upper layers. This approach solves the problem of understanding how the network is performing. Chapter 9 describes the types of tools that will measure response time. Measuring Response TimeAt a simplistic level, you can measure response time by timing the response to pings from the network management station to key points in the network, such as a mainframe interface, end point of a service provider connection, or key user IP addresses. The problem with this method is that it does not accurately reflect the user's perception of response time between their machine and whatever destination they try to connect with. It simply collects information and reports response time from the network management station's perspective. Figure 4-2 demonstrates this. Figure 4-2. The Two Possible Paths in the Network
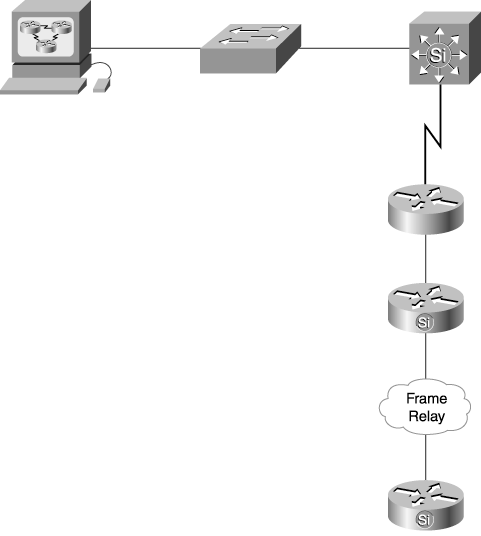
The dashed lines in this figure represent the pathways traveled by data. On the left, data travels from the user PC to the host with a round-trip response time of 75ms. On the right, the data travels from the network management station to the host with a round-trip response time of 55ms. This method also masks response time issues on a hop-by-hop basis throughout the network. For instance, if you measure ping responses at the far end of a Frame Relay connection (see Figure 4-3), the measure reflects the time required for the packet to make its way through the various elements (the two switches, three routers, and various switches in the Frame Relay cloud). If you detect a slower response time than usual, there is no indication in the measure where the actual delay occurs. Your first reaction may be to blame the Frame Relay service provider, when the delay may be occurring at one of the local routers. Figure 4-3. Example of How End-to-End Response Time Can Mask Hop-by-Hop Response Time Issues
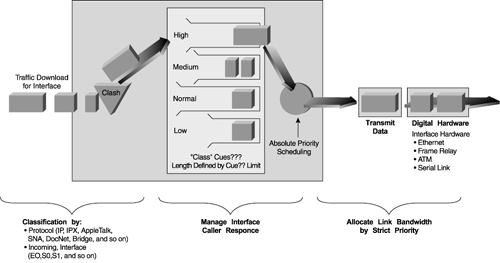
However, there are advantages to this method as well. It is a relatively easy method of collecting a consistent measure of response time trends. A noticeable increase in response time may indicate congestion or errors somewhere and can be used to initiate troubleshooting. Or you can track the response time to various points over time for trending purposes. An alternative to server-centric polling is to distribute the effort closer to the source and destination you want to simulate for measure. This can be achieved through the use of distributed network management pollers, as well as implementing Cisco IOS Response Time Reporter (RTR) functionality. Enabling RTR on routers allows you to measure response time between a router and a destination device such as a server or another router. You can also specify a TCP or UDP port, thus forcing traffic to be forwarded and directed in the same manner as the traffic it is simulating. With the integration of voice, video, and data on multi-service networks, customers are implementing QoS prioritization in their network. Simple ICMP or UDP measurement will not accurately reflect response time because different applications will receive different priorities. Also, with tag switching, the routing of traffic may vary, based on the application type contained in a specific packet. Thus, an ICMP ping may receive a different priority in the way each router handles it and may receive different, less efficient routes (refer to Figure 4-3). In Figure 4-4, notice how different traffic types come into the router, and the queuing mechanisms ensure that high priority traffic gets the bandwidth or time slices needed. Figure 4-4. Example of Router Priority Queuing Mechanisms
This image was lifted from http://www.cisco.com/warp/public/cc/cisco/mkt/ios/tech/tch/qosio_wp/qosio_w2.gif. In this case, the only way to measure response time is to generate traffic that resembles the particular application or technology of interest. This forces the network devices to handle the traffic as they would for the real stuff. You may be able to achieve this level with RTR or through the use of other application-aware probes. For more details, see Chapter 9. AccuracyAccuracy is the measure of interface traffic that does not result in error. Accuracy can be expressed in terms of a percentage that compares the success rate to total packet rate over a period of time. You must first measure the error rate. For instance, if two out of every 100 packets result in error, the error rate would be 2 percent and the accuracy rate would be 98 percent. With earlier network technologies, especially in the wide area, a certain level of errors was acceptable. However, with high-speed networks and present day WAN services, transmission is considerably more accurate and error rates are close to zero unless there is an actual problem. Some common causes of interface errors include the following:
A decreased accuracy rate should be used to trigger a closer investigation. You may discover that a particular interface is exhibiting problems and decide that the errors are acceptable. In that case, you should adjust the accuracy threshold for this interface in order to reflect where the error rate is unacceptable. The unacceptable error rate may have been reported in an earlier baseline. If you see a steady increase of errors on an interface, it usually indicates some sort of physical problem and should probably be checked out. On the other hand, you may decide that for some segments, higher error rates are okay. From the baseline, you will be able to determine where in the network you should allow higher rates of errors. Measuring AccuracyTo measure accuracy, collect the error rates regularly from a given interface and compare the rate with overall traffic for that interface. Determine what you will consider an acceptable error rate for that type of interface: this will determine your threshold. Table 4-2 describes the variables used in accuracy and error rate formulas.
The formula for error rate is usually expressed as a percentage, as shown in Equation 4-2: Equation 4-2
NOTE Please notice that outbound errors are not considered in the error rate (see Equation 4-2) and accuracy (see Equation 4-3) formulas. That is because a device should never knowingly place a packet with errors on the network, and the outbound interface error rates should never increase. Hence, inbound traffic and errors are the only measures of interest for interface errors and accuracy. The formula for accuracy takes the error rate and subtracts it from 100 (again, in the form of a percentage): Equation 4-3
These formulas reflect error and accuracy in terms of MIB II interface (RFC 2233) generic counters. The result is expressed in terms of a percentage that compares errors to total packets seen and sent. The resultant error rate is subtracted from 100, which produces the accuracy rate. An accuracy rate of 100 percent is perfect, whereas less than 100 percent might be less than optimal. Because the MIB II variables are stored as counters, you must take two poll cycles and figure the difference between the two. Hence, the delta (D) used in the equation. For example, assuming that the cabling is within specification and that you've conducted a baseline analysis, you decide to use 2 5 (0.00002 or 0.002 percent) as an acceptable rate threshold for your fast Ethernet connections. As you measure, you find the following: Out of 234,000 packets transferred and received over a 15-minute interval, 110 resulted in error. This generates an error ratio of 0.00004700854 (approximately 0.005 percent), which translates into an accuracy measurement of 99.995 percent. This exceeds the threshold of anything less than 99.998 percent and thus raises a cause for concern. Different protocols have different types of errors. For instance, with Ethernet there are runts, giants, alignment, and FCS errors. The ifInErrors variable used in the previous formula reflects all of these errors. If you need to break down errors by specific types, there generally are additional MIBs that measure the different error types. For instance, with Ethernet, RFC 1757 defines variables that handle each of the error types (etherStatsCRCAlignErrors, etherStatsUndersizePkts, etherStatsOversizePkts, etherStatsFragments, and etherStatsJabbers). These and other variables are examined in more detail throughout Part II of this book. A final note: Some protocol features are misconstrued as errors. For example, with half-duplex Ethernet, collisions are a natural and expected part of the protocol. The presence of collisions is not necessarily a bad thing. But collisions above a certain threshold do interfere with the capability for devices to put traffic on the network. In this case, measuring collision rates using the error rate formula makes sense, although the thresholds for collisions will be set higher than thresholds for errors. For more details about how to handle Ethernet collisions, see Chapter 13, "Monitoring Ethernet Interfaces." UtilizationUtilization measures the use of a particular resource over time. The measure is usually expressed in the form of a percentage in which the usage of a resource is compared with its maximum operational capacity. Through utilization measures, you can identify congestion (or potential congestion) throughout the network. You can also identify under-utilized resources. Utilization is a handy measure in determining how full the network pipes are. Measuring CPU, interface, queuing, and other system-related capacity measurements allows you to determine the extent at which network system resources are being consumed. High utilization is not necessarily a bad thing. Low utilization may indicate that traffic is flowing in the wrong place. As lines become over-utilized, the effects can become huge. Over-utilization occurs when there is more traffic queued to pass over an interface than it can handle. Sudden jumps in resource utilization can indicate a fault condition. As an interface becomes congested, the network device must either store the packet in a queue or discard it. If a router attempts to store a packet in a full queue, the packet will be dropped. Forwarding traffic from a fast interface to a slower interface can result in dropped packets. When a packet gets dropped, the higher layer protocol may force a retransmit of the packet. If lots of packets get dropped, the result could be that of excessive retry traffic. This type of reaction can again result in backups on devices further on down the line. You should consider setting varying degrees of thresholds, as described in Chapter 5. Measuring UtilizationCalculating utilization depends on how the data is presented for the particular thing you want to measure. For instance, when calculating CPU utilization for a router, the busyPer object from http://www.cisco.com/public/mibs/v1/OLD-CISCO-CPU-MIB.my is reported as a percentage value. However, when calculating interface utilization for a half-duplex 10BaseT interface, you have a choice using MIB II (RFC 2233) variables or vendor-specific variables. In the case of MIB II variables, your application must calculate the percentage manually by doing the following:
There are also Cisco-specific variables in http://www.cisco.com/public/mibs/v1/OLD-CISCO-INTERFACES-MIB.my called locIfInBitsSec and locIfOutBitsSec, which eliminate the need for step 1 in the previous example. Please note that sub-interfaces are not supported consistently by this MIB. Please see the section "Special Considerations for Sub-Interfaces" in Chapter 12 for details.
Concerning utilization, a rule of thumb is that you should not assume that 0 percent is necessarily good and 100 percent is necessarily bad. Theoretical maximum utilization does not always reflect problem thresholds. You must use your baseline analysis to determine which thresholds are of concern for your organization. For example, a router CPU utilization that peaks at 100 percent occasionally is not necessarily a bad thing. This just indicates that the device has very little idle time. However, if a CPU remains at 100 percent for periods of time, it may indicate that packets are being dropped, in which case you should check other information, such as packet drops. A converse example is half-duplex, shared media 10BaseT Ethernet utilization. Even if the theoretical maximum capacity of 10BaseT is 10 MB, reaching half its capacity can render the medium unusable in some cases. In this particular case, the reason is that as utilization rises, so does the Ethernet collision rate. Based on your baseline analysis, you may determine that a particular shared Ethernet segment should threshold an event at 30 percent in order to indicate a high water mark. Interface utilization is the primary measure used for network utilization. The following formulas should be used, based on whether the connection you measure is half-duplex or full-duplex. Shared LAN connections tend to be half-duplex, mainly because contention detection requires that a device listen before transmitting. WAN connections typically are full-duplex because the connection is point-to-point; both devices can transmit and receive at the same time because they know there is only one other device sharing the connection. Because the MIB II variables are stored as counters, you must take two poll cycles and figure the difference between the two (hence, the delta (D) used in the equation). Table 4-3 explains the variables used in the formulas.
For half-duplex media, use Equation 4-4 for interface utilization: Equation 4-4
For full-duplex media, calculating the utilization is trickier. For example, with a full T-1 serial connection, the line speed is 1.544 Mbps. What this means is that a T-1 interface can both receive and transmit 1.544 Mbps for a combined possible bandwidth of 3.088 Mbps! When calculating interface bandwidth for full-duplex connections, you could use Equation 4-5, in which you take the larger of the in and out values and generate a utilization percentage: Equation 4-5
However, this method hides the utilization of the direction that has the lesser value and provides less accurate results. A more accurate method is to measure the input utilization and output utilization separately, such as the following: Equation 4-6
and
As a final note, these formulas are somewhat simplified because they do not take into consideration any overhead associated with the particular protocol. Although more precise formulas exist to handle the unique aspects of each protocol, for most cases, the general formulas presented in this chapter can be used reliably across all LAN and WAN interface types. As an example, please refer to RFC 1757 for Ethernet-utilization formulas that take into consideration packet overhead. |
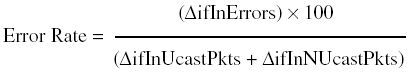
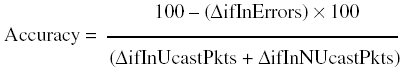


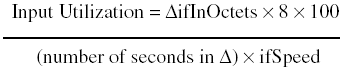

EAN: 2147483647
Pages: 200