Genetic Algorithms
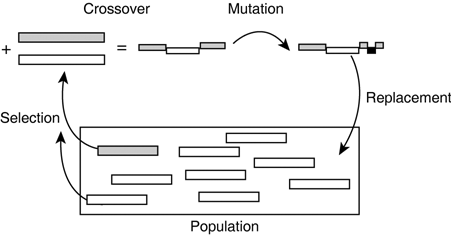
| Biological evolution relies on autonomous creatures living and reproducing within an environment. Most problems will not want such sophisticated creatures, or even the complexity of an environment that can drive evolution. Therefore, there is a need to understand the evolutionary process and replicate the important operations that drive evolution. Evolutionary algorithms model the process step by step, so it can be performed artificially within a computer (see Figure 32.3). Instead of relying on living artificial creatures, genetic algorithms can "apply" evolution to static data structures (for instance, strategies or behaviors). These may be solutions to any problem that requires a solution using the power of evolution. Figure 32.3. Bird's eye view of an evolutionary algorithm, including the main cycle that creates new offspring from existing parents. Here's the generic outline of such an evolutionary process:
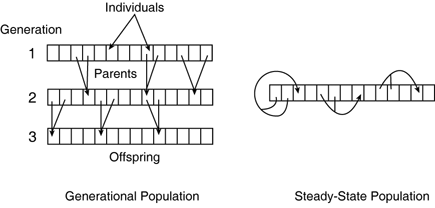
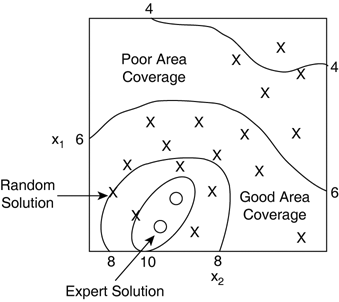
This is the template for artificially simulating life as we know it. Naturally, the techniques used at each stage will influence the outcome. The remaining part of this section presents the purpose of each stage and their major requirements. The next section introduces a wide variety of policies from which to choose. The PopulationThe population is essentially a set of individuals. In the software, the population is essentially the container that stores each of the genotypes. Like living populations, the ones in genetic algorithms change over time, too. Newly born offspring become part of the population, whereas others die out. The computer model has the luxury of being able to preserve individuals for any number of generations. This is a problem as much as an advantage, because we have to manually discard individuals when appropriate. Conceptually speaking, the population can be steady-state or generational. A steady-state population will change incrementally very slowly, on a per-individual basis. This means a new genotype is inserted into the current population, and the process starts again. For generational algorithms, a new population is created each generation, and new offspring from the previous individuals are added to the next generation until there are enough to continue. Figure 32.4 shows different types of populations. Figure 32.4. Different types of populations. On the left, three generational populations, and one steady-state population on the right. There are also different forms of storage, not as a data structure, but conceptually speaking. On one hand, the population can be seen as a group of individuals with no particular organization. Alternatively, it can have spatial coherence. The individuals can be organized in 1D or 2D space, in a line, or on a grid. This models some important properties of real environments in the simulation, and different stages in the algorithm can benefit in some way. The major advantage is that the propagation of genes can be constrained spatially. InitializationIdeally, the initial population must be a representative sample of the search space (that is, all the possible solutions). This gives the genetic algorithm a vague idea of the fitness in each area. To do this, initializing each individual completely randomly is a good policy. Given a good random number generator (such as the Mersenne Twister [Matumoto02]), and a procedure that can create a wide variety of random genotypes, the coverage of the initial search space will be very broad. The more the individuals are in the initial population, the better the coverage (see Figure 32.5). Figure 32.5. The initial population in a 2D search space. There is good coverage of most areas, as well as some expert solutions. During initialization, it is also possible to reuse existing genotypes (a.k.a. seeding the evolution). For example, the population can include good solutions that have been created with other mathematically based algorithms, or solutions modeled or inspired by human experts, or genotypes from previous evolutions. This has the advantage of immediately revealing areas of high fitness in the search space, for the genetic algorithm to explore and improve them. EvaluationBefore getting to the genetic algorithm itself, you need to understand the concept of fitness and evaluation. This is crucial; it allows biasing the process in favor of the fittest individuals, allowing the quality of the solutions to improve. Each individual in the population can be seen a solution to a problem. The purpose of the evaluation is to determine how good the solution is. This measure represents the fitness of the individual. The process of evaluating an individual is known as the fitness function. This function takes a phenotype, and returns its fitness as a floating-point number. The implementation of the function itself will simulate the problem with the proposed solution. Then, depending on how well the phenotype does, it is assigned a score. The scale for the scoring is quite flexible, as long as it ranks the individuals relatively to each other. The rest of the genetic algorithm can be developed to take care even of disparate fitness values. This fitness function is fundamental to genetic algorithms and multidimensional optimization strategies in general. It drives the optimization process by rating the benefits of individuals:
The fitness function is naturally problem dependent; if we want to evolve game characters that creep slowly, our fitness function will differ from the one evaluating animats at running. Even within each problem, there are many different ways to implement the fitness function. In fact, it's safe to say that creating fitness functions is the primary problem with genetic algorithms. With a perfect system and a poor evaluation, nothing worthwhile will arise from the evolution. On the other hand, it's possible to get good results with a minimal genetic algorithm and a well-considered fitness function.
SelectionThe selection process aims to pick out individuals from the population, in order for them to spawn offspring. Two different methodologies affect the selection process (although these are sometimes used together):
The selection process has a very influential role on the fitness of the offspring. Darwin observed that the genes of successful individuals are more likely to spread throughout the gene pool. By favoring better individuals during selection, the average fitness of the population tends to increase over the generations. This is known as elitism, selecting fit individuals in preference. Elitism can be applied to other stages of the genetic algorithm, but is especially important when selecting parents. When fit individuals are chosen for breeding, the offspring is likely to be fit, too although there is absolutely no guarantee. Unfit parents could also spawn miracle offspring. However, using elitism, the average fitness of the population will generally rise to find better solutions. There is a trade-off between exploration of the search space (that is, allowing any individual to breed) and the elitist approach. With lower elitism, more parts of the search space are explored. Higher elitism implies areas around the fitter individuals are under focus instead. Evolution is slower with little elitism but guarantees a better coverage of the search space. On the other hand, evolution with strong elitism tends to converge quicker to a result (although not necessarily the optimal one). CrossoverIn this phase, the genetic code of both parents is combined together to form an offspring. This is only possible if sexual reproduction is used; using crossover on one parent has no effect whatsoever (because the genes to be "mixed" are identical). This idea is modeled on the creation of the reproductive cells. Before becoming the sperm and ova, the pairs of chromosomes are split right down the middle and reassembled together in alternate pairs. This way, about half the genes of each parent are found in the reproductive cells. For living creatures, this process is done entirely by chemical reaction. In artificial evolution, we need to perform crossover manually. This is generally done by copying some genes from the father and others from the mother. Using random factors in this selection ensures that parents will not always have the same offspring as in real life. It's good practice for the crossover to preserve a good balance of genes between both parents, for example 60 percent / 40 percent. (Just swap the genes to create the complement offspring, as discussed in the following section.) Other unbalanced distributions aren't as common, because we want to borrow good traits from both parents. A genetic sequence of sufficient length is needed to transmit these attributes intact. (Of course, there are no guarantees this is always true, but it works in nature.) Distributions such as 95 percent / 5 percent negate the benefits of sexual crossover, becoming closer to asexual reproduction. This is generally modeled using a high mutation rate instead. MutationIn living organisms, mutation happens regularly during cell division, but this is especially likely when reproductive cells are created. The chemical reactions that happen during the division process are error prone; chromosomes and genes can be changed permanently. In some cases, the cells die or the fertilization fails. In other cases, the changes persist in the offspring, although mutation leads to "abnormal" individuals with arbitrary fitness. The mutation can happen on two levels, in the chromosome (genome level) or in the DNA (genotype level). Changes in the genome are generally much more threatening to the process, and happen quite rarely. In genetic algorithms, mutation is generally applied to the genotype of the offspring after it has been created to fake the errors that happen during fertilization. Typically, only alleles are mutated by changing their value with a small probability (for instance, 0.001). The structure of the genetic code (genome) is often left intact. The importance of mutation is underlined by evolution strategies that use only mutation and no crossover. It has many beneficial properties, notably maintaining diversity in the genetic code. That said, mutation is not as important as geneticists originally thought it was for the evolution of intelligence but mutation is more important than they believe it is now (no doubt somewhere in the middle of the spectrum). In a simulation, the way mutation can be performed really depends on the representation of the genome itself. Generally, only the genes will be mutable, so only a simple traversal is required to mutate some genes randomly. If the genome is open to mutation (that is, the rest of the genetic algorithm can deal with arbitrary genomes), it may be beneficial to mutate that too. ReplacementEach of the previous steps contributes to creating one (or more) offspring. The purpose of the replacement scheme is to determine whether to insert these individuals into the population. If not, they should be discarded. Otherwise, the replacement policy should decide how to reinsert the individual into the population. If the population has no particular organization, it's not important how, but whether replacement occurs. The genotype of offspring is fully known at this stage so it can be evaluated if necessary. Indeed, most replacement schemes rely on the fitness value to determine whether to replace the individual in the population. The replacement function affects the evolution of the population directly. Because we want to control the quality of the solutions, we need to favor fit individuals. The principle of elitism affects the design of a replacement scheme, too. Indeed, it's possible to prevent offspring's with low fitness from entering the population at all. Likewise, existing individuals with low fitness can be replaced in the population. The replacement function must take into account that evolution may be either steady state or generational. In the steady-state case, each individual is processed one by one and reinserted into the same population. In the second case, there is a different population containing the next generation, and individuals are inserted into that instead. A genetic algorithm has the luxury of being able to preserve individuals for any length of time. Using a generational approach, the genetic code of an individual will only survive in the offspring. However, using a steady-state approach, it's possible for fit individuals to remain throughout the evolution. The replacement policy is indirectly responsible for this, too, because old individuals or the parents can be replaced by new genotypes. |
EAN: 2147483647
Pages: 399