5.4 Filesystems
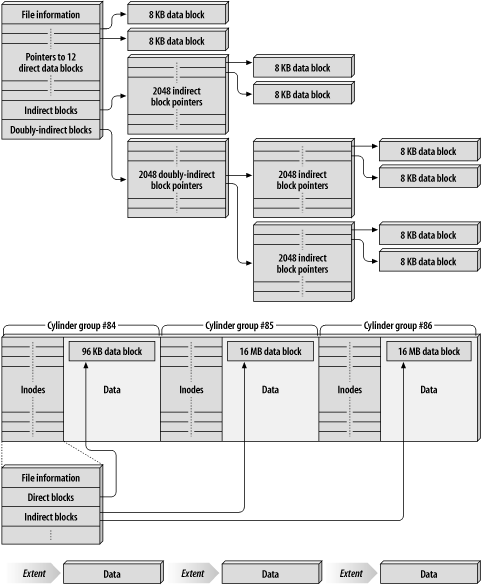
Modern filesystems come in two flavors: block-based and extent-based . An indirect block-based filesystem breaks all files into 8 KB data blocks and spreads them all over the disk; additional 8 KB indirect blocks keep track of where the data blocks reside. For files that are more than a few megabytes in size , doubly indirect blocks are used to store the location of the indirect blocks. When a file is created, only the minimum number of blocks are used. When a file is extended, extra blocks are taken from a map of unused blocks. The disk allocation system tries to optimize these spatial relationships so that the majority of file accesses are contiguous and don't require extensive seeking. Every time a block is assigned, however, this data must be written to disk. The metadata is always written synchronously, without the benefits of any caching. Metadata operations can have a substantial impact on I/O subsystem performance, precisely because they are synchronous.
An extent-based filesystem defines files in terms of extents , which contain a starting point and a size. If a 1 GB file is written, it is a single 1 GB extent. There are no indirect blocks: a sequential reads the extent, then all of the data. This means that there is very little metadata overhead in sequential file access. Unfortunately, extent-based filesystems tend to suffer from severe fragmentation problems. After many files have been created and deleted, it's hard to find the space to allocate a large file. As a result, all extent-based filesystems come with tools to defragment the filesystem. Note that filesystem defragmentation tends to be quite I/O intensive , for obvious reasons, and therefore, the timing of this event in relation to critical production tasks must be carefully decided. Figure 5-2 shows block-based versus extent-based filesystems.
Figure 5-2. Block-based versus extent-based filesystems
5.4.1 vnodes, inodes, and rnodes
Unix systems traditionally use inodes to keep track of information required to access a file (such as the file size, owner, permissions, where the data blocks are stored, etc.) System V systems, including Solaris, use a higher-level abstraction called a virtual node , or vnode . This simplifies implementing new filesystems: the kernel works in terms of vnodes, each of which contains some kind of inode that matches the underlying filesystem time. For UFS, these structures are still called inodes; for NFS, they are called rnodes .
5.4.1.1 The directory name lookup cache (DNLC)
Any time a file is opened, the directory name lookup cache , or DNLC, comes into play. This is a low level cache in kernel memory of what filenames are associated with which vnodes. When a file is opened, the DNLC figures out the right inode from the filename given; if the name is in the cache, the system does a fast lookup to avoid scanning directories. Each DNLC entry is a fixed size, so there is only space for a pathname component (e.g., /etc and password are distinct pathname components of the pathname /etc/passwd ) of up to 30 characters , and longer filenames are not cached. Directories that have thousands of entries often take quite a while to search for a specific file, so a good DNLC hit rate is important if lots of files are being opened and the directories are quite large. As a result, you should strive to keep heavily used directory and symbolic link names down to less than 30 characters. In practice, this is not usually a problem.
You generally do not need to tune the DNLC, unless you are providing NFS service on a machine with less than 512 MB of memory. A good value in these situations is 8,000 or so. The maximum tested value is 34,906, which corresponds to a value of 2,048 for the maxusers parameter. The default size for a given system is determined by maxusers x 17) + 90, with a maximum value of 17,498 without explicit tuning. (We discuss parameters influenced by maxusers in Section 2.2.2.)
The vmstat -s command shows the DNLC hit rate since the system came up. In general, a hit rate of less than 90% indicates that some attention is required:
% vmstat -s grep 'name lookups' 34706339 total name lookups (cache hits 98%)
You can determine how many name lookups per second are being performed by inspecting the namei/s field reported by the sar -a command:
% sar -a 1 5 ... 16:44:54 iget/s namei/s dirbk/s 16:44:55 111 603 203
There are two similar caches for inodes and rnodes. We will discuss these in the sections specific to those filesystems (Section 5.4.2.7 later in this chapter and Section 7.5.2.2).
5.4.2 The Unix Filesystem (UFS)
The Unix Filesystem (UFS) is the default Solaris filesystem; it is an indirect, block-based filesystem. Every file stored in the filesystem actually consists of several components:
-
The directory entry , which contains the name of the file, its permission mask, and creation, modification, and access dates.
-
The data blocks , which contain the actual data.
-
The access control list entries (optional), which provide a more robust mechanism for access control than the standard Unix permission model does.
When the filesystem is created, space is allocated for inodes, which store the directory entries and access control list entries. This number is static, and may not be increased without recreating the filesystem. You can find out how many free inodes are available by examining the output of df -e :
% df -e Filesystem ifree /proc 862 /dev/dsk/c0t0d0s0 294838 fd 0 /dev/dsk/c0t0d0s4 246965 swap 9796 /dev/dsk/c1t0d0s0 3256077
5.4.2.1 inode density
By default, the UFS filesystem allocates 1 inode for every 2-8 KB of usable disk space, as summarized in Table 5-7.
Table 5-7. Default UFS inode densities
| Filesystem size | KB per inode |
|---|---|
| < 1 GB | 2,048 |
| < 2 GB | 4,096 |
| < 3 GB | 6,144 |
| > 3 GB | 8,192 |
Each inode consumes a small amount (512 bytes) of disk space, but it adds up quickly. One inode per 16 KB of disk space is a much more reasonable default in most cases. In cases where the filesystem holds very large files, such as in a scientific workload, a much lower density is appropriate; as little as one inode per megabyte of disk space might be reasonable. Similarly, filesystems that are populated with a large number of very small files might do well with the default allocation. An excellent example is a filesystem that contains a Usenet news spool, which creates one file for every news article (typically very short).
The inode density can be configured when running newfs by using the -i bytes-per-inode switch.
5.4.2.2 Filesystem cluster size
When a file is being extended, the filesystem clusters data in 8 KB blocks whenever possible. This behavior permits the entire cluster to be written to disk in a single operation. It gives rise to two important advantanges:
-
Writing in a single operation is more efficient from the operating system's point of view, since I/O overhead is constant regardless of how much data is written.
-
When the file is read later, the entire cluster can be read in a single operation. This saves I/O overhead, but more importantly saves a disk seek between the retrieval of each block.
The number of contiguous filesystem blocks that will be stored on the disk for a single file is defined by the maxcontig filesystem parameter. In Solaris releases prior to 8, this parameter is set to seven disk blocks, or 56 KB, by default. This is the default because of a design limitation present in older Sun hardware. [19] Solaris 8 changed the default to 128 KB (16 blocks). Changing this parameter has the greatest impact in sequential operation, but should not severely impact randomly accessed filesystems, since such accesses generally do not read entire clusters. Even though a filesystem may have entirely random access patterns, keep in mind that the process of data backup is inherently sequential: configuring a large cluster size may accelerate backups substantially. The biggest gain in tuning maxcontig is achieved in RAID 5 devices, since with the default value each write almost ensures a very expensive read/modify/write operation (see Section 6.2.6).
[19] Specifically, systems based on the sun4 architecture are unable to transfer more than 64 KB in a single operation. The sun4c , sun4m , sun4d , and sun4u architectures do not have this problem.
The filesystem cluster size is specified by the -C blocks switch to newfs when the filesystem is being created, or it can be modified on existing filesystems by specifying the -a switch for tunefs .
|

In general, maxcontig should be set to an integer multiple of the data width of the stripe on filesystems that reside on striped or RAID 5 devices. [20] For example, on a 6-disk RAID 5 volume with a 32 KB interlace , the stripe width is 160 KB (since one disk is used for parity computation), and a reasonable value of maxcontig is 160 or 320 KB (20 or 40 blocks, respectively). On filesystems that contain very large, sequentially accessed files, maxcontig should be set to a value equal to at least double the data width of the storage device.
[20] Remember that RAID 5 arrays have a data width of one disk less than the number of disks in the array.
It may also be necessary to tune the maximum I/O transfer size in order to derive the maximum benefit from tuning maxcontig to values above 128 KB. This can be done by setting the maxphys , md_maxphys , and vxio:vol_maxio kernel tunables in /etc/system . The first two are in units of bytes, and vxio:vol_maxio is in units of 512 bytes.
In random access workloads, different guidelines will apply. In summary, you should try and match the I/O size and the filesystem cluster size, then enable as large a filesystem cache as possible (if this parameter is tunable), and disable prefetching and read-ahead.
5.4.2.3 Minimum free space
When a filesystem is created, some fraction of the storage space is reserved in case of future emergencies. This fraction is governed by the minfree parameter, which is historically 10% of the filesystem size. This dates back to computing antiquity; in addition to giving a reasonable overflow amount, it provided a means of ensuring that the system could easily find a free disk block when the disk was nearly full. In modern environments, where 200 GB filesystems are quite common, a 10% free space reserve accounts for 20 GB of disk space! Since locating free blocks within even a 20 MB area is easy, the original performance concerns are moot as well.
In order to minimize the impact of this overhead, set minfree to be 1%. The minimum free space can be set when you are creating the filesystem by specifying -m percentage to newfs .
5.4.2.4 Rotational delay
The rotational delay parameter is a throwback to the days when disk controllers weren't able to handle data at the speed that the disk platter could provide it. In such cases, a strategy of storing blocks physically out-of-order was developed, in which two blocks were stored with enough radial position between them that the disk would rotate into position to read the second block just as the processing of the first block finished.
For example, consider a disk that rotates at 11 ms per revolution (about 5,400 rpm) but whose controller takes 2 ms to process each block. If data blocks are sequential, by the time the first one is read and processed , the second block has already passed under the heads, so we must wait for the platter to spin back into position; satisfying the read takes over 20 ms. If the blocks are physically located a quarter-revolution (2.75 ms) apart, however, the controller can handle the second block as soon as it is presented, and we can perform the whole operation in about 9 ms. These days disk controllers are fast enough to not be bothered by this problem, so rotdelay is best set to zero, which is the default. [21]
[21] If you are using magneto-optical disks, or another sort of unusually slow media, you may still want to set the rotdelay parameter.
The rotational delay can be set at filesystem creation by specifying the -d rotational-delay option to newfs .
5.4.2.5 fstyp and tunefs
You can determine information about a specific filesystem via the fstyp command. This command generates a lot of output, of which the first 18 lines are useful:
% fstyp -v /dev/dsk/c0t0d0s3 head -18 ufs magic 11954 format dynamic time Fri Feb 16 15:01:02 2001 sblkno 16 cblkno 24 iblkno 32 dblkno 456 sbsize 5120 cgsize 5120 cgoffset 72 cgmask 0xffffffe0 ncg 272 size 7790674 blocks 7670973 bsize 8192 shift 13 mask 0xffffe000 fsize 1024 shift 10 mask 0xfffffc00 frag 8 shift 3 fsbtodb 1 minfree 1% maxbpg 2048 optim time maxcontig 16 rotdelay 0ms rps 120 csaddr 456 cssize 5120 shift 9 mask 0xfffffe00 ntrak 27 nsect 133 spc 3591 ncyl 4339 cpg 16 bpg 3591 fpg 28728 ipg 3392 nindir 2048 inopb 64 nspf 2 nbfree 886360 ndir 2149 nifree 888732 nffree 6320 cgrotor 249 fmod 0 ronly 0 logbno 1216 fs_reclaim FS_RECLAIM file system state is valid, fsclean is -3
The most important options are those that we've discussed previously: minfree , maxcontig , and rotdelay .
It's possible to tune a filesystem after it has been created by the means of the tunefs command. [22] In fact, all three UFS attributes we've focused on can be tuned : maxcontig via the -a switch, rotdelay via the -d switch, and minfree by -m . For example, to change the maximum number of contiguous blocks on a filesystem:
[22] "You can tune a filesystem, but you can't tune a fish." -- BSD tunefs manpage
# fstyp -v /dev/dsk/c0t0d0s3 grep maxcontig maxcontig 16 rotdelay 0ms rps 120 # tunefs -a 32 /dev/dsk/c0t0d0s3 maximum contiguous block count changes from 16 to 32 # fstyp -v /dev/dsk/c0t0d0s3 grep maxcontig maxcontig 32 rotdelay 0ms rps 120
5.4.2.6 Bypassing memory caching
If you are performing sequential I/O on very large files (in hundreds of megabytes to gigabytes range), or if you have an extremely random I/O pattern on small files, you may want to disable the buffering that is normally performed by the filesystem code. You may turn this buffering off for a UFS filesystem by using the directio option to mount_ufs(1M) . However, UFS still suffers from some indirect block limitations, so using directio is not as fast as true raw access. Because direct I/O bypasses the filesystem cache, it also disables filesystem read-ahead; small reads and writes result in many separate I/O requests to the storage device, instead of being clustered into larger requests . Another side effect of direct I/O is that it does not put load on the Solaris memory subsystem, and removes the paging activity that is typically seen in pre-Solaris 8 systems without priority paging enabled (see Section 4.4.3).
5.4.2.7 The inode cache
The first of two interesting in-kernel caches relating to the UFS filesystem is the inode cache. Whenever an operation is performed on a file residing on a UFS filesystem, that inode must be read. The rate of inode reads is reported as iget/s by the sar -a command. The inode read from disk is cached in case it is needed again. When a file is not in use, its data is cached in memory by an inactive inode cache entry (each inode cache entry has the pages for the corresponding file attached to it); if an inactive entry that has pages attached to it is recycled for reuse, its associated pages are freed and placed on the free list. This is reported as %ups_ipf by sar -g . Any nonzero values reported here mean that the inode cache is too small.
The inode caching algorithm is implemented by keeping a "reuse list" of blank inodes. These are available instantly. The number of active inodes isn't limited, but the number of idle inodes (inactive, but cached) is kept between the value of ufs_inode and 75% of ufs_inode by a scavenging kernel thread. The only upper limit is the amount of kernel memory consumed by the inodes. The tested upper limit is 34,906, which corresponds to a maxusers value of 2,048. To get the raw statistics regarding the inode cache, run netstat -k inode_cache or kstat -n ufs:0:inode_cache :
% netstat -k inode_cache inode_cache: size 22207 maxsize 68156 hits 1044055 misses 23085 kmem allocs 22207 kmem frees0 maxsize reached 22218 puts at frontlist 95088 puts at backlist 544 queues to free 45284 scans 2558333385 thread idles 0 lookup idles 0 vget idles 0 cache allocs 23085 cache frees 880 pushes at close 0
If the maxsize_reached value is greater than the maxsize (which is equal to ufs_ninode ), then the number of active inodes has exceeded the cache size at some point in the past, and you should probably increase ufs_ninode .
5.4.2.8 The buffer cache
UFS utilizes a second caching mechanism, called the buffer cache . In BSD Unix derivatives, the buffer cache is used to cache all disk I/O; in SVR4 Unices, such as Solaris, it is used to cache inode, indirect block, and cylinder- group related disk I/O only. The nbuf tunable controls how many page- sized buffers have been allocated, and a variable called p_nbuf controls how many buffers are allocated at once. By default, p_nbuf is set to 100. A variable called bufhwm , which is set by default to 2% of system memory, defines the maximum amount of memory that the buffer can use. You can see how big the buffer cache is on your system by /usr/bin/sysdef grep bufhwm :
# /usr/sbin/sysdef grep bufhwm 20914176 maximum memory allowed in buffer cache (bufhwm)
You can get statistics on the buffer cache by looking at kstat unix:0:biostats : [23]
[23] The kstat command is a recent addition to Solaris. Historically, there was an undocumented -k switch to netstat that would let you get these statistics. If your system doesn't have kstat , try netstat -k biostats .
% kstat unix:0:biostats module: unix instance: 0 name: biostats class: misc buffer_cache_hits 40596836 buffer_cache_lookups 40707195 buffers_locked_by_someone 8221 crtime 49.729349302 duplicate_buffers_found 0 new_buffer_requests 0 snaptime 3630491.75512563 waits_for_buffer_allocs 0
Comparing the buffer cache hits with the number of lookups indicates that the hit rate since the system came up is 99.981%, which is pretty reasonable. Contrary to some past writing in some Sun publications , you should not generally need to tune any of the buffer cache parameters.
If you see a hit rate less than 90% in the buffer cache, and your filesystem is more than 40,000 times the amount of physical memory (e.g., if you have 1 GB memory and your filesystem is ~40TB), then you should increase the buffer cache to some larger value.
5.4.3 Logging Filesystems
In order to implement the robustness required of modern systems, a filesystem must be able to provide reliable storage to its applications, and if a failure occurs, it needs to recover rapidly to a known state. This has not always been the case: system crashes have traditionally left the filesystem in an inconsistent state, and recovering that consistency took a long time. [24] One approach to overcoming these issues is to use a mechanism called logging (also known as journaling ), in which we try to prevent the filesystem structure from damage by only applying changes through a rolling sequential log.
[24] On the scale of many hours, for a large filesystem with many files.
Logging allows us to maintain an accurate view of the filesystem state, so that despite a power failure or other catastrophe we know exactly what state the filesystem is in. Rather than scanning the entire filesystem (via fsck ), we can check just the log and correct the disk against the last few entries if necessary. This can mean the difference between 20 seconds and 48 hours for checking filesystem integrity, during which the system is almost certainly not available for use. Unfortunately, logging does not come for free; it requires that a lot of writes be conducted synchronously, and metadata logging requires at least three writes for each file update. If we are concerned about performance alone -- damn the chances of data loss, full speed ahead! -- then logging isn't a good choice. But if we are building a high performance-clustered transaction server, reliable filesystems are probably worth the performance tradeoff .
There are three common ways of implementing logging:
- Metadata logging
-
Only filesystem structure changes are logged; this is the most popular mechanism.
- File and metadata logging
-
All changes to the filesystem are logged.
- Log-structured
-
The entire filesystem is a log.
In a nonlogged filesystem, several disconnected, synchronous writes are used to implement a filesystem change. If an outage occurs in the middle of an operation, the state of the filesystem is unknown, and the entire filesystem must be checked for consistency. Metadata logging is based around a cyclic, append-only log area that it uses to record the state of each transaction. Before any on-disk structures are modified, an "intent-to-change data" record is written to the log. The directory structure is then changed, and a completion record is written to the log. Since every state change involved in processing every transaction is recorded in the log, we can check filesystem consistency by scanning the log rather than checking the entire filesystem. If we find an intent-to-change entry without a corresponding completion entry, we check the appropriate block, and adjust if necessary. Some mechanisms allow this log to reside on a disk separate from the filesystem, and some embed the log in the same partition as the data.
Several filesystems allow you to store data in the log, as well as the metadata. The data is written to the log, and then replayed into the filesystem. This ensures data integrity right up until the last block written, and helps performance for small writes. A small write in a nondatalogging filesystem incurs two seek and writes: the first one for the data itself and the second for the log write. Putting the data in the log reduces the number of steps to one.
Log-structured filesystems (also known as write- anywhere filesystems ) implement the entire filesystem structure as a log. In such an environment, writing to the filesystem appends data blocks to the end of the log as data is written, marking earlier blocks invalid as it goes. This approach lets every file be written sequentially, regardless of block order, which makes writes very fast. Unfortunately, it also cripples read performance, since blocks are allocated in the order written -- which may mean that files are completely scattered across the disk. Log-structured filesystems also require a mechanism to scan through the filesystem and remove invalid blocks. It's also necessary to cache the location of the data blocks, since they can be in a random order, and this caching is very complex. These sorts of filesystems are efficient in metadata-intensive environments, but are not as efficient for data-intensive environments. In fact, there are currently no log-structured filesystems that I know of.
5.4.3.1 Solstice:DiskSuite
Sun's Solstice:DiskSuite product provides an enhancement known as the metatrans device, which adds a transaction logging mechanism to the existing filesystem structure. It provides metadata-only logging functionality, and allows the log to be split away from the filesystem. In an environment without any nonvolatile cache memory, this can provide a low-cost (albeit slower) equivalent.
5.4.3.2 Solaris
Starting with Solaris 7, there is a way to implement a logging mechanism without using the DiskSuite product. This mechanism is simple to use, and does not require any changes to the filesystem. Just mount the filesystem with the -o logging option to mount :
# mount -F ufs -o logging /dev/dsk/c1t0d0s0 /mnt
You can have this done at boot-time, as well:
# device device mount fs fsck mount mount # to-mount to fsck point type pass at boot options /dev/dsk/c1t0d0s0 /dev/rdsk/c1t0d0s0 /mnt ufs 2 yes logging
5.4.4 The Second Extended Filesystem (EXT2)
The Second Extended Filesystem, devised by Rmy Card, is used in all shipping Linux distributions as of this writing. It is an indirect block-based filesystem, quite similar to UFS.
You can find the number of free inodes on an ext2fs partition by using df -i :
% df -i Filesystem Inodes IUsed IFree IUse% Mounted on /dev/hda1 513024 111953 401071 22% /
The single largest problem with ext2fs is that, by default, it writes metadata asynchronously. This means that power failures and other abrupt, unusual system halt operations often cause significant damage to the filesystem. Confounding this problem is that ext2fs does not support logging; for that, the use of IBM's JFS filesystem, the Third Extended Filesystem (ext3), or the Reiser filesystem, is required.
5.4.5 The Third Extended Filesystem (EXT3)
The Third Extended Filesystem (ext3fs) is a revision of ext2fs -- the most significant revision is support for journaling. It supports journaling of metadata only as well as journaling of file data. It also coexists peaceably with ext2: ext3 filesystems can be mounted as ext2 filesystems (although without journaling support). Furthermore, despite writing some data more than once, ext3 filesystems can exhibit higher throughput than ext2 filesystems, because the journaling process optimizes the motion of the hard drive read/write heads. As can be expected, I focus here on the performance tuning aspects of ext3.
The ext3 filesystem, by journaling all metadata changes, can magnify the effect of access time updates significantly. This can be disabled by mounting the filesystem with the noatime flag in order to disable access time updates.
5.4.5.1 Tuning the elevator algorithm
Most Linux block device drivers use a generic "elevator" algorithm for scheduling block I/O. This algorithm tries to minimize the amount of disk read/write head movement required. The /sbin/elvtune program can be used to trade throughput for latency, and vice versa. There are two key parameters to feed elvtune : the maximum read latency ( -r value ) and the maximum write latency ( -w value ). By default, these values are 8,192 and 16,384. For example, /sbin/elvtune -r 4096 -w 8192 /dev/sdc will change the elevator settings for the /dev/sdc device. In general, the write latency should be about twice the read latency. You will need to experiment with good values for these tunables; experience has shown that reducing these numbers by about half tends to be a good starting point for ext3 filesystems. When you've found values that work well for you, the calls to elvtune should be added at the end of the rc.local script; elevator algorithm tuning settings are not preserved across reboots.
In some cases, attempting to tune for maximum throughput at the expense of latency (that is, setting large read and write latencies via elvtune ) can adversely affect actual throughput, while still increasing latency. One contributing reason is that the ext3 filesystem has writes scheduled every 5 seconds, as opposed to the 30-second delay associated with ext3. This factor keeps journal transactions from having a more measurable effect.
5.4.5.2 Choosing a journaling mode
The ext3 filesystem supports three different types of journaling. These are set via the data option to the mount call.
- The data=journal option
-
Causes all data (both file data and metadata) to be journaled. This option provides the most assurances of data consistency, but also has the highest performance overhead.
- The data=ordered option
-
Causes only metadata to be logged. File data is written before metadata, which means that all metadata must point at valid data. If the system crashes while appending data to a file located on a data=ordered ext3 filesystem, data blocks may have been written, but the metadata corresponding to the extension of the file will not have been, so the data blocks won't be part of any file. If a write is occurring in the middle of a file (which is much less common than writing at the end of a file; even overwriting a file is done by truncating the file and then overwriting it), however, it is possible for data corruption to occur.
- The data=writeback option
-
Causes only metadata to be logged, with no special handling of file data; most other journaling filesystems work in this mode. The filesystem will be kept consistent, but old data may appear in files after an unclean shutdown. This journaling mode produces speed improvements in certain workloads because of its weakened data consistency assurances. The workloads tend to be dominated by heavy synchronous writes or creating and deleting many small files. If you switch from ext2 to ext3 and see a significant performance drop, the data=writeback option may provide a significant performance boost.
5.4.5.3 Transitioning from ext2 to ext3
Thankfully, it's easy to move from ext2 to ext3: no reformatting is required. Just run tune2fs -j /dev/hda2 (or whatever device should be moved) and change the appropriate 'ext2' line to 'ext3' in /etc/fstab . Transitioning the root filesystem is more difficult; consult the documentation accompanying your Linux distribution for the most current details.
5.4.6 The Reiser Filesystem (ReiserFS)
ReiserFS 3.6.x (which is included as a part of Linux 2.4.x kernels ) is a journaling filesystem designed and developed by Hans Reiser and Namesys. The guiding principle behind ReiserFS development was to help create a single, shared environment (a "namespace") where applications could interact. That would allow users to interact with the filesystem directly, rather than build special-purpose layers to run on top of the filesystem (such as databases internal to applications).
Initially, ReiserFS focused on small file performance (less than a few thousand bytes), the area typically lacking in filesystems like ext2 and UFS. ReiserFS is about ten times as fast as ext2 when handling files under 1K in size. This speed is accomplished by the means of a balanced tree system for organizing filesystem metadata. This scheme relieves artificial restrictions on filesystem layout, as well having the pleasant side effect of only allocating inodes when they are needed, rather than creating a fixed set of inodes at the time of filesystem creation.
5.4.6.1 Tail packing
ReiserFS has a special feature called tail packing . ReiserFS calls a file that is smaller than a filesystem block (4 KB) a tail . One of the reasons ReiserFS has very good small file performance is because it is able to incorporate these tails directly into its organizational data structures, so they are close to their metadata. However, tails don't take up much disk space; because they don't fill up their entire filesystem block, they can waste disk space. For example, a 100 byte file will consume an entire 4 KB filesystem data block, for a storage efficiency of about 2.4%. To resolve this problem, ReiserFS does something called tail packing, which allows tails to be stored together in a filesystem block to improve storage efficiency. Unfortunately, tail packing incurs a significant performance hit. If you are willing to sacrifice storage capacity for performance, mounting your filesystem with the notail option will eliminate tail packing and provide a speedup .
ReiserFS filesystems start to slow down when they get more than about 90% full.
ReiserFS, like any new technology, has had some deployment and maturity issues; it historically has not cooperated well with NFS, for example. While ReiserFS is still gaining support, it looks to be a strong and robust filesystem, and is still under development. You can learn more about ReiserFS at http://www.namesys.com.
5.4.7 The Journaled Filesystem (JFS)
The Journaled Filesystem (JFS) is an extent-based design that was originally developed by IBM for use in their AIX operating system; it shares the increased reliability and fast recovery time characteristics with other logging filesystems.
JFS refers to a filesystem as an aggregate , which consists of an array of disk blocks containing a specific format. Each aggregate includes a superblock and an allocation map. The superblock identifies the partition as a JFS aggregate, and the allocation map describes the allocation state of each data block. An aggregate, along with the control structures necessary to define it, is called a fileset , which is mountable. Each aggregate maintains a log that records metadata change information.
IBM has ported JFS to Linux, with patches available for various kernels. The web site for JFS for Linux is http://www.ibm.com/developerworks/oss/jfs/.
5.4.8 The Temporary Filesystem (tmpfs)
Solaris supports a special filesystem type, called tmpfs , that preferentially uses memory rather than disk for storage, as long as physical memory is available. If memory becomes constrained, the files are written to swap space: as a result files on a tmpfs volume will not consume all the physical memory on the system. Unfortunately, this also means that files stored on a tmpfs volume will be lost during a reboot. The performance acceleration observed on such filesystems is not the result of caching -- equivalent caching is accomplished by the normal Solaris mechanism -- but rather from the fact that tmpfs files are never written to disk unless little free memory remains. Therefore, using tmpfs to try and accelerate an application that exhibits read-mostly behavior isn't wise, as the data is already being buffered in memory by the filesystem.
% df -k /tmp Filesystem kbytes used avail capacity Mounted on swap 1707512 107472 1600040 7% /tmp
By default, Solaris systems use tmpfs for /tmp , avoiding significant levels of I/O because /tmp is used for compiler temporary files, editor storage, etc. As a result, the traditional practice of creating a separate partition for /tmp tends to not be effective in Solaris. One nice side effect of this is that you can use df to see how much swap space is free.
5.4.9 Veritas VxFS
Veritas Software sells the extents-based VxFS filesystem, which has a number of features that make it well suited for handling large applications. One of the most significant is the ability to optionally use a direct path to I/O that bypasses the in-memory filesystem cache. This is more efficient than the UFS directio option. VxFS is also conducive to quite a few performance optimizations from the point of view of its internal organization. The filesystem also optionally uses a data-logging strategy, as opposed to the metadata-only logging strategy implemented in UFS+. However, in such an environment, the log device must have performance characteristics approaching that of the main storage subsystem, or the log disk will become a bottleneck. Unfortunately, VxFS is complicated and difficult to use correctly. VxFS reflects the complexity of modern storage.
You can access the VxFS documentation online via http://support.veritas.com.
5.4.10 Caching Filesystems (CacheFS)
Accessing a file from disk is less expensive in terms of performance and network traffic than accessing a file that resides on a network-resident volume (e.g., via NFS). CacheFS was introduced to Solaris with 2.3, and is available on many other platforms, including HP-UX and IRIX, for accelerating file accesses to NFS volumes . It requires no support on the NFS server: it is entirely client-based. CacheFS calls the cache directory the frontend , and the directory shared via NFS the backend . CacheFS uses this cache directory to maintain local copies of remotely stored files, in order to avoid incurring the overhead of consulting with the remote file server unless necessary.
The first step is to set up a cache directory with cfsadmin(1M) . By default, these files are cached in 64 KB blocks, and only files of up to 3 MB are cached; larger files are left uncached.
cfsadmin is a monolithic application: it creates, deletes, lists, consistency-checks, and updates configuration parameters. Table 5-8 summarizes the available commands.
Table 5-8. Switches to cfsadmin
| Switch | Use |
|---|---|
| -c cache-directory | Creates the specified cache directory |
| -d cache-id | Deletes the specified cache directory; the cache-id value for a given cache directory is shown in cfsadmin -l |
| -l cache-directory | Lists the filesystems cached in the specified cache directory |
| -s mount-point | Performs a consistency check on the cached filesystem if the filesystem was mounted with the demandconst flag |
| -u cache-directory | Increase parameters; if specified without -o options , resets the parameters to the default if possible |
Starting a consistency check examines files as they are accessed, so a cfsadmin -s will not create a flood of consistency checks. The -c and -u switches also take options, specified by -o options , and summarized in Table 5-9.
Table 5-9. Options to cfsadmin
| Option | Description | Default |
|---|---|---|
| maxblocks | The highest percentage of blocks in the cache directory that the specified cache may use. | 90 |
| minblocks | The percentage of blocks in the cache directory that the specified cache can use without limitation. |
|
| threshblocks | When block usage increases beyond this percentage, the cache cannot claim resources until the block usage has reached the level specified by minblocks . | 85 |
| maxfiles | The highest percentage of files in the cache directory that the specified cache may use. | 90 |
| minfiles | The percentage of inodes in the cache directory that the specified cache can use without limitation. |
|
| threshfiles | When inode usage increases beyond this percentage, the cache cannot claim resources until the inode usage has reached the level specified by minfiles . | 85 |
| maxfilesize | This option specifies the largest file that the cache is allowed to store, in megabytes. Files larger than this will not be cached. | 3 |
Here are a few examples of how to use cfsadmin . Let's start out by creating a cache with the default parameters and mounting a filesystem against the cache:
# cfsadmin -c /cache # mount -F cachefs -o ro,backfstype=nfs,cachedir=/cache \ docsun.cso.uiuc.edu:/services/patches /mnt # df -k /mnt Filesystem kbytes used avail capacity Mounted on /cache/.cfs_mnt_points/docsun.cso.uiuc.edu:_services_patches 8187339 2529123 5658216 31% /mnt
As you can see, there are some specialized options to mount for use with CacheFS. These options are summarized in Table 5-10.
Table 5-10. Options to mount for a CacheFS filesystem
| Option | Description | Default |
|---|---|---|
| acdirmax | The time, in seconds, for which cached directory attributes are held before being purged from the cache. | 30 |
| acdirmin | The time, in seconds, for which cached directory attributes are guaranteed a space in the cache. After this many seconds, CacheFS checks to see if the directory modification time on the backend filesystem has changed; if so, the information is purged and a new copy is fetched . | 30 |
| acregmax | The time, in seconds, for which cached file attributes are held after the file is modified before being purged. | 30 |
| acregmin | The time, in seconds, for which cached file attributes are guaranteed a space in the cache after the file is modified. After this many seconds, if the file modification time on the backend has changed, the information is purged and a new copy fetched. | 30 |
| actimeo | A utility variable. Setting this to a value sets acdirmax , acdirmin , acregmax , and acregmin to that value. | 30 |
| backfstype | Specifies the type of the backend filesystem. Generally nfs . | None |
| backpath | Specifies where the backend filesystem is mounted. If this argument is not given, CacheFS picks a suitable value. | Auto |
| cachedir | The name of the cache directory. | None |
| cacheid | A string specifying a particular cache instance. If you do not give one, CacheFS will pick one for you. | Auto |
| demandconst | When this flag is set, cache consistency is verified only upon request, rather than automatically. This is useful for filesystems that change very rarely. Incompatible with noconst . | Toggle (Off) |
| local-access | The front filesystem is used to interpret the permission bits, rather than having the backend verify this information. Setting this may be a security vulnerability. | Toggle (Off) |
| noconst | Disables automatic cache consistency checking. Specify only when you know that the backend filesystem will not change. Incompatible with demandconst . | Toggle (Off) |
| purge | Throw away any cached data. | No |
| ro | Mount as read-only. Incompatible with rw . | Toggle (Off) |
| rw | Mount as read/write. This is the default behavior. Incompatible with ro . | Toggle (On) |
| suid | Allow the execution of suid applications. This is the default behavior. Incompatible with nosuid . | Toggle (On) |
| nosuid | Disallow the execution of suid applications. Incompatible with suid . | Toggle (Off) |
| write-around | Causes writes to behave as they would under ordinary NFS: writes are made to the backend filesystem, and the cache entry is invalidated. This is the default behavior. Incompatible with non-shared . | Toggle (On) |
| non-shared | Causes writes to be made to both the backend filesystem and the cache filesystem. Use this only when you are sure that no one else will be writing to the filesystem. Incompatible with write-around . | Toggle (Off) |
Let's take a look at the cache:
# cfsadmin -l /cache cfsadmin: list cache FS information maxblocks 90% minblocks 0% threshblocks 85% maxfiles 90% minfiles 0% threshfiles 85% maxfilesize 3MB docsun.cso.uiuc.edu:_services_patches:_mnt
Looks good. In order to change some of our cache parameters without deleting and recreating the cache directory, we can use cfsadmin -u , once all cached filesystems have been unmounted:
# umount /mnt # cfsadmin -u -o maxblocks=95,minblocks=65,threshblocks=90,\ maxfiles=95,minfiles=80,threshfiles=85,maxfilesize=10 /cache # cfsadmin -l /cache cfsadmin: list cache FS information maxblocks 95% minblocks 65% threshblocks 90% maxfiles 95% minfiles 80% threshfiles 85% maxfilesize 10MB docsun.cso.uiuc.edu:_services_patches:_mnt
Now that we're done with our example, let's clean up after ourselves , and remove the mounted filesystem and its cache:
# umount /mnt # cfsadmin -d docsun.cso.uiuc.edu:_services_patches:_mnt /cache # cfsadmin -l /cache
To completely remove the filesystem cache, use cfsadmin -d all :
# cfsadmin -d all /cache
You can automatically mount a network filesystem while using CacheFS at boot by adding a line like this in /etc/vfstab :
# device device mount fs fsck mount mount # to-mount to fsck point type pass at boot options nfs-server:/apps /cache /apps cachefs 3 yes ro,backfstype=nfs,cachedir=/cache
When a new read is performed, the request is rounded up to a 64 KB chunk and passed to the NFS server. A copy of the returned data is written to the CacheFS store on local disk. A write to cached data causes an invalidation of the data in the cache; a subsequent read incurs the penalty of reloading the data from the server. This is not actually so bad, since in the short term reads are likely to be satisfied from the in-memory cache.
It is entirely possible that on a lightly loaded 100 Mbit network and a fast NFS server, a cache miss is faster than a cache hit to a heavily loaded local disk! If the local disk is also handling paging activity, it's possible that the activity from paging and from the cache is likely to be synchronized, especially on application startup.
The best filesystems to cache are read-only or read-mostly, and reside across busy, low-bandwidth networks. You can check the cache hit rate with the cachefsstat command, which is available in Solaris releases after 2.4: [25]
[25] If you are running Solaris 2.3 and 2.4, there is no way to obtain this information. An operating system upgrade may be in your future.
# cachefsstat /mnt cache hit rate: 90% (54 hits, 6 misses) consistency checks: 31 (31 pass, 0 fail) modifies: 0 garbage collection: 0
This should give you an idea of how effective the caching is in your environment. I have observed hit rates substantially in excess of 95% for read-only application distribution systems.
5.4.10.1 Minimizing seek times by filesystem layout
One recurring theme in this chapter is the necessity to minimize seek time, especially for random access applications. It stands to reason that the more data a cylinder can hold, the less seeking is required. This is accomplished in striping by making logical cylinders that are larger than the physical cylinder size (which is, of course, fixed), but a similar effect can be accomplished even on a single disk. One of the effects of ZBR (see Section 5.1.1 earlier in this chapter) is that the outside cylinders are faster and hold more data. Because all the cylinders are larger, seeks on the outer cylinders are shorter than seeks in the inner cylinders! As a result, using the outside cylinders whenever possible results in fewer seeks.
The fact that long seeks take much longer than short seeks brings us to another important rule: configure disks with a single purpose. Placing two "hot" areas of data access on a disk is a sure way to cause the disk to spend much of its time seeking between them, rather than directly servicing requests.
For historical reasons, many system administrators partition a root drive into four slices, in this order: root, swap, /usr , and /home . This organization is far from optimal. The swap slice is likely to be accessed the most frequently, and /home is likely to be accessed more frequently than /usr . If a seek outside of the current partition occurs, it stands to reason that many times the disk arm will need to seek all the way from swap to /home , completely bypassing /usr . By simply reordering the partitions as root, swap, /home , and /usr , we have reduced the average observed seek time for the disk!
This seems to violate the first principle of performance tuning: we are getting something for free! However, in this case, the cost is intellectual rather than financial -- the expense of achieving this benefit is the effort spent in understanding how disk access works at a fundamental level, and then applying it to the real world.