3.4 Multiprocessing
Shared-memory multiprocessor systems were considered rather exotic in the mid-1980s, and they were expensive. Since then, we have seen hardware costs drop, much more robust multiprocessor support in operating systems, and an increased demand for affordable high-throughput systems at a workgroup and even desktop level. These multiprocessor systems are described as uniform memory access (UMA) architecture, which means that all physical memory is accessible to all processors at the same rate. Some large-scale systems use a nonuniform memory access (NUMA) architecture, in which a specific processor can access some bits of physical memory faster than others. Figure 3-5 illustrates the UMA and NUMA architectures.
Figure 3-5. UMA and NUMA architectures
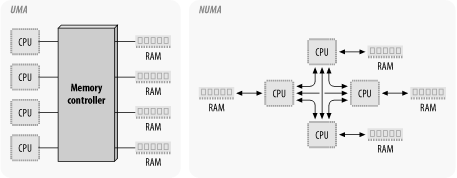
We'll restrict our discussion here to UMA architectures.
3.4.1 Processor Communication
In order for the human body to function nominally, it is vital that information can be conveyed to and from the brain. Communication is also essential for successful operation of a multiprocessor system. If we draw an analogy between computers and the human body, and we think of the processor as the brain, the "spinal cord" facilitates the exchange of information to and from the processor to main memory and peripheral devices. This is facilitated in computer architecture by buses or crossbars, which also allow the arbitration of communication so that the components can figure out who can talk at any given point in time. It is important to note that we speak here only of interconnections between processors and main memory; for details on how interconnections between peripherals are handled, see Section 3.5 later in this chapter.
3.4.1.1 Buses
A bus consists of three parts : a protocol for communication, a set of parallel wires that link all the system components, and some supporting hardware. Buses are cheap and easy to build, but as it becomes more heavily populated and the load increases , the bus begins to be a performance bottleneck. As a result, cache size and performance is very important in bus-based multiprocessor configurations. Typically, this sort of architecture supports at most four processors, but larger ones will support a few tens of processors. It is possible that the bus or memory subsystem will become saturated before the maximum number of supported processors have been installed!
Buses implement either circuit-switched or packet-switched protocols. In a circuit-switched protocol, two devices establish a communications circuit over the bus and maintain that circuit until their transaction has completed. This is simple to implement, but the processor must wait if it is communicating with a slow device (such as main memory). These wait states reduce the bus throughput and waste clock cycles: the faster the processor clock rate, the more cycles wasted .
Older Sun systems used the MBus bus architecture, which is circuit-based. [11] You could actually configure four 50 MHz SuperSPARC modules with SuperCache in a SPARCserver 20, which was a remarkably fast desktop system for the time. Unfortunately , when 50 MHz processors were installed in a SPARCstation 20, it automatically reduced the MBus clock rate from 50 MHz to 40 MHz in order to support data synchronization between processors; it's too bad that the system that needed the fastest possible MBus didn't get it. Because of cooling limits in the SPARCstation 20 chassis, you could not configure processors faster than 50 MHz.
[11] The SPARCstation 10, 20, and the SPARCserver 6x0MP. Other systems, such as the SPARCstation LX, Classic, 4, and 5, are MBus-based, but do not have multiprocessor support. If uname -a returns sun4m , your machine uses the MBus architecture.
To get around the wasted cycles inherent in fast-slow device interactions on a circuit switched protocol like MBus, Sun implemented a packet-switched protocol for XBus, which was used on a per-board basis in the SPARCserver 1000 and 2000 lines as well as in the Cray SuperServer CS6400. [12] The boards were tied together via XDBus, which consisted of multiple interleaved XBuses. A packet-switched protocol relies upon breaking every bus transaction into a request packet and a response packet. This is hard to implement because every packet must contain an identifier of the issuing device, as well as the need for a particular component on the bus (such as the memory subsystem) to queue up requests if they come in too quickly.
[12] When Cray was purchased by Silicon Graphics in 1996, the division responsible for the SuperServer CS6400 was sold to Sun. This group later produced the Ultra Enterprise 10000 ("Starfire") system.
With the advent of the fast UltraSPARC processors, Sun designed a new interconnect architecture, called the UltraSPARC Port Architecture switched interconnect (UPA). It is a packet-switched architecture characterized by its implementation of a "switch" architecture in which all buses route through a centralized switch that redirects them appropriately, as well as sizing the bus to the device; for example, memory devices require a very wide bus, but I/O channels need not be so wide. This bus sizing keeps costs low. All ports on the switch run at the same clock rate, but some are master ports (processors, I/O controllers) that can both initiate and respond to requests, and some are slave ports (framebuffers, memory) that can only respond to requests. UPA is resistant to bus contention bottlenecks under heavy load, because each device has its own dedicated connection to the bus switch.
For the multiboard Ultra Enterprise server line, modifications were made to the UPA bus in order to support the multiboard system requirements. [13] This gave rise to the Gigaplane passive backplane, which is a distributed extension of the UPA bus techniques. It has support for optimizations that increase the efficiency of spinlocks and memory sharing.
[13] The Ultra Enterprise 250 and Ultra Enterprise 450 systems are single-board , and implement UPA.
The performance of these buses is detailed in Table 3-4.
Table 3-4. Sun multiprocessor bus/switch characteristics
| Bus | Clock rate | Peak bandwidth (in MB/sec) | Peak read throughput (in MB/sec) | Peak write throughput (in MB/sec) |
|---|---|---|---|---|
| MBus | 40 MHz | 320 | 90 | 200 |
| XBus (per board) | 40 MHz | 320 | 250 | 250 |
| Single XDBus (SPARCserver 1000) | 40 MHz | 320 | 250 | 250 |
| Dual XDBus (SPARCcenter 2000) | 40 MHz | 640 | 500 | 500 |
| Quad XDBus (SuperServer CS6400) | 55 MHz | 1,760 | 1,375 | 1,375 |
| UPA (UltraSPARC systems) | 82 MHz | 1,600 | 1,300 | 1,300 |
| Gigaplane (Ultra Enterprise systems) | 82 MHz | 2,624 | 1,600 | 1,600 |
| Gigaplane XB (Ultra Enterprise 10000) | 100 MHz | Up to 10,622 | Up to 12,800 | Up to 12,800 |
3.4.1.2 Crossbars
Crossbars were developed to work around the performance problems in the single bus architecture. A crossbar is essentially a collection of several parallel buses, in which any component can access any other component through any path through the crossbar. In addition to connecting parties that wish to communicate, much like a switchboard operator, the crossbar must also arbitrate conflicts, such as those that arise when two processors try to access the same bit of memory. Because there is no single shared bus, performance is generally good, but because of the extra support hardware required, crossbars are typically more expensive, and only found in high-end multiprocessor systems.
One example of such an implementation is the Gigaplane XB crossbar used in the Sun Ultra Enterprise 10000 system. It is an extension of the Gigaplane passive backplane used in the other Ultra Enterprise systems; it increases the throughput of the architecture, but at a cost in price and memory latency. This increase in memory latency is caused by an additional layer of circuitry . Gigaplane XB does not feature the spinlock optimizations included in Gigaplane, because Gigaplane XB was developed by the Cray SuperServer team before their acquisition. Gigaplane is actually faster than Gigaplane XB when running within its bandwidth limitations; the full bandwidth of the XB crossbar is only available with a fully configured system, as illustrated in Table 3-5.
Table 3-5. Bandwidth variation as a function of configured processors
| Architecture | Number of processors | Peak bandwidth (in MB/sec) | Latency (in ns) |
|---|---|---|---|
| UPA | 1-4 | 1,600 | 170 |
| Gigaplane | 1-30 | 2,624 | 240 |
| Gigaplane XB | 1-12 13-20 21-28 29-36 37-44 45-52 53-60 61-64 | 1,333 2,666 4,000 5,331 6,664 7,997 9,330 10,622 | 400 |
In less than twenty processor configurations, the Gigaplane architecture has the edge in performance. In larger installations, the Gigaplane XB crossbar starts to shine , and we see much improved bandwidth: four times the bandwidth for twice the number of configured processors. In small installations (four processors or less), however, the latency of Gigaplane-based systems becomes a liability; because of the increased complexity of the switching times, it is approximately twice that of UPA-based systems. This means a four-processor single-board Ultra Enterprise server often outperforms a four-processor multiboard Ultra Enterprise server, and costs considerably less!
3.4.1.3 UltraSPARC-III systems: Fireplane
With the move to the UltraSPARC-III architecture, Sun developed a new interconnection technology, called Fireplane . Fireplane improves on the previous-generation UPA interconnect in both performance and feature set. Unlike the other interconnects we've discussed, Fireplane does not specify the device topology; instead, it describes the protocols that devices attached to the interconnect use to communicate. This gives it a good degree of flexibility for future uses. The other interesting new feature of Fireplane is that it supports having multiple outstanding transactions on the interconnect at once (up to fifteen 64-byte data transfer requests, for example, can be pending at once on the Sun Blade 1000).
The Sun Blade 1000 implements a packet-switched bus topology for both address and data paths. The data path is a 288-bit (256 bits of data, plus 32 bits of error correction information) bus, implemented via a group of six chips that are collectively known as the combined processor memory switch (CPMS). There are point-to-point connections between data path and devices connected to it, simplifying arbitration logic.
The memory controller is integrated onto the UltraSPARC-III processor, which reduces latency and improves bandwidth. The memory is addresed through a 144-bit-wide data path to a data switch chip, which has a 576-bit (512 bits of data, plus 64 bits of error correction information) path to memory. Interestingly, in a two-processor system, only one of the processors' memory controllers is active. This processor can directly access memory, whereas the other must access memory over the Fireplane interconnect. [14]
[14] All memory address requests go across the interconnect to facilitate cache coherency management.
The interconnect itself is capable of a peak bandwidth of 67.2 GB/second, with a sustained bandwidth of up to 9.6 GB/second (2.4 GB/second per CPU, up to a limit of 9.6 GB/second).
3.4.1.4 "Interconnectionless" architectures
Some UltraSPARC processors, which are typically used in lower-end systems, do not require a formal interconnect. These include the so-called "I-series" and "E-series" designs, such as the UltraSPARC-IIi and the UltraSPARC-IIe; I-series processors are highly integrated and optimized for price/performance, whereas the E-series processors are designed for embedded applications.
3.4.2 Operating System Multiprocessing
The majority of modern operating systems support multitasking . In fact, multitasking does not require more than one processor; it simply refers to the ability to run more than one process at a time. The system splits its time between them on the basis of context switching at fixed time intervals, I/O activity, or interrupts. On a multiprocessor system, individual processes will be split between both processors for an aggregate speedup (but without increasing the observed single-application performance). Most processes are self-contained, [15] but processes can play nicely with others and share information by means of the interprocess communication (IPC) mechanisms such as pipes and sockets or by intimately shared memory (ISM). We'll discuss ISM in greater detail in Section 4.4. It is generally a bad idea to implement IPC in an attempt to increase single-application performance on a UMA multiprocessor system; on very large scale parallel computing installations it may be appropriate, however.
[15] In terms of not sharing data with other processes. We won't worry about shared libraries and such for the purposes of this discussion.
3.4.3 Threads
A thread is not a process! A process begins its life as a single thread, but it can then add or remove threads as its execution progresses. These threads all share the same process memory space, but each thread also possesses a thread private area for its own local variables . Threads can improve single-application performance in two ways:
-
Each thread in a multithreaded process can be dispatched to a different processor in a multiprocessor system. This collaboration across multiple processors improves single-application performance.
-
Threads can be used to increase application throughput. A single-threaded web server would be stuck in a wait state every time it needed to fetch a document from disk. By multithreading the server, one thread can be waiting to handle a new request while another waits for the disk to provide data.
Because of this last point, it is quite practical to have a multithreaded process on a single processor; in fact, multithreading existed long before multiprocessing systems did. This technique is very useful for increasing throughput, but it's a bad idea to have more identical active threads than processors in a compute- intensive program.
3.4.4 Locking
It is critical to the smooth operation of a multiprocessor system that some mechanism of synchronization should exist. For example, say that we have two threads that each increment the same variable by executing the following assembler code:
LOAD r1,Counter ADD r1,1 STORE r1,Counter
Let's say that the initial value of Counter is 021400 . What happens if, at the exact instant that the first thread completed the LOAD but before it executed the ADD and STORE , the operating system switched to executing the second thread? The second thread could execute all three instructions, resulting in Counter being 021401 . When the operating system restarts the first thread, it will pick up where it left off and execute the ADD and STORE instructions, storing 021401 into Counter and giving it a terminal value of 021401 when it should be 021402 . If the system has two processors, the situation is just as bad if not worse ! Rather than relying on operating system intervention, if the two threads are executing the same instructions concurrently, they will perform the load-add-store sequence in perfect lockstep, and we will again have 021401 when we should have 021402 in Counter .
We need some way to make simple operations such as this atomic (indivisible), so that only one thread can execute these instructions at a time. We call areas like this critical sections .
On uniprocessor systems, this problem was solved by disabling interrupt servicing for the duration of the critical section, which prevents the thread from being interrupted . This won't work on multiprocessor systems, since each processor has its own interrupt mask, so we must be more devious in our approach.
All SPARC processors support an instruction called LDSTUB (load-store-unsigned-byte), which atomically reads a byte from memory into a register and writes 0xFF into memory. This instruction allows the establishment of mutual exclusion locks , or mutexes , which make sure that only one processor at a time can hold the lock. To tear down the lock, the thread simply writes 0x00 back to memory. If a processor can't get a lock, it may decide to spin until the lock becomes available. Spin locking is accomplished entirely within the processor's cache, so that it does not cause excess bus traffic. Spin locks are useful when the wait for the lock is expected to be short; if a longer wait is expected, the thread should sleep so that another job can be scheduled onto the processor. The SPARC V9 instruction set used on UltraSPARC processors includes an atomic compare-and-swap operation as well as the atomic load-store operation.
When the multiprocessing-enabled version of SunOS 4 was released for the SPARCserver 6x0-class systems, the uniprocessor interrupt-mask approach was replaced with a mutex-based approach: the call to disable interrupts was replaced by a mutex acquisition, and the call to re-enable interrupts was replaced with a mutex release. On a system with many processors that is under load, the mutex locking itself can actually become a bottleneck. [16] If this is the case, adding additional processors will hinder, rather than help, performance.
[16] I've never seen this behavior on a system with less than four CPUs, assuming a well-behaved application.
Interestingly, this phenomenon of performance decreasing as you add processors is not restricted to this particular case. It's possible for poor application programming to cause severe mutex contention. A large security company a friend of mine was affiliated with had a product written in C that ran on Solaris systems. On a uniprocessor system, this product performed adequately. When a second CPU was added, the performance of the application dropped by almost 30%. This is not at all unusual: poor application design and implementation is a possible, indeed a likely, root cause of poor performance on multiprocessor systems.
Sometimes all the threads in a process need to wait at a certain point until all of the threads are "caught up." For example, let's say that we have a time-based simulation of a car's frontend crumpling during an impact with a concrete wall. [17] It would not make sense for the threads to compute the state of the car at different points in time, since the threads working later would need to know what happened earlier. We can enforce this sort of synchronization with a construct known as a barrier . All threads must reach the barrier (say, finish processing one time interval's worth of data) before any are allowed to continue.
[17] I have, unfortunately, had occasion to attempt this experiment in real life. My personal experience indicates that simulations are a far less expensive way of determining that a car will protect its occupants from bodily harm.
3.4.5 Cache Influences on Multiprocessor Performance
Another major problem needs to be dealt with in multiprocessor system architecture. Let's say that we have two processors, CPU 0 and CPU 1. CPU 0 fetches a specific cache line from main memory into its cache. CPU 1 then fetches the same line into its cache. When CPU 0 writes to that cache line, it will update its local cache as well as main memory; however, there needs to be some way of notifying CPU 1 that its copy of the cache line is invalid and needs to be thrown away. This is accomplished via communications on the multiprocessor bus. Since communication must occur for most cache activity, it creates a good deal of traffic.
As a result, larger processor caches often cause a great performance increase on multiprocessor systems. References to main memory must go across the bus, which on a multiprocessor system is typically very busy.