18.1 Create a Response Chain of Command
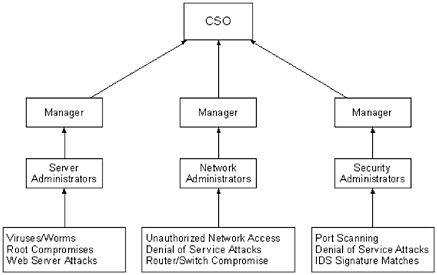
| The first step in responding to an attack is to develop a clear chain of command, and ensure that it is distributed to everyone. A well-thought-out chain of command will serve two purposes: It will help get security incidents resolved faster, because the right people will be notified, and it prevents the security department from being overrun with unrelated requests . There are usually three groups involved in creating and supporting the response chain of command: network administrators, server administrators, and security administrators. Each of these groups should have different responsibilities, and be responsible for different security incidents. The idea is to have the group most closely associated with a problem act as the first level of response. That group should be able to make the quickest and most accurate assessment as to whether or not a network anomaly is harmless or a possible security incident. Some organizations collapse the duties of network, system, and security administration into one group. In cases like this, different people within that group should have a primary responsibility for security escalations. At least two people within an organization should be ultimately responsible for handling all security incidents. Ideally, the primary responsibility for managing security incidents should rest with the chief security officer (CSO), with secondary responsibility resting with the manager of the security administration group. If there is no CSO or security administration group, the responsibilities can be assigned to the manager of the network and system administrators groups. Redundancy in personnel is just as important as redundancy in systems. If the primary contact is unavailable, a secondary contact ”who is aware of the procedures for dealing with an attack ”should always be available and listed as part of the chain of command. A central point of contact, at the senior management level, is very important because decisions that affect the company network and connectivity will often have to be made on the spot, and it is important to have someone who can speak for the company. The chain of command for security incidents should vary depending on the type of attack. Each group is responsible for managing its own areas of responsibility, but the same procedures should be followed organization-wide. For the rest of this section, assume an organization that has a separate group to manage workstations/servers, network devices, and security devices. The security administration group manages the firewalls and IDS; the network administrators manage other network devices. The primary point of contact is the CSO. Each group is responsible for maintaining and monitoring its own systems. The groups are not staffed 24x7, but there is extensive monitoring in place on the network, and personnel are notified if a suspicious incident occurs after hours. Figure 18.1 shows one way in which this organization could manage its security escalation. Each group is responsible for certain devices on the network. If a device within the realm of its responsibility is attacked , the group is responsible for proper escalation of the incident. Notice there is a crossover between the network administrators and the security administrators with regard to DoS attacks. DoS attacks may be noticed at the router level first, or they may be noticed at the firewall, or even by the IDS. Whichever group notices it first, it should be reported to the other group, and escalated appropriately. Figure 18.1. A sample escalation chart for security incidents The second thing that should be added to this escalation chart is a response time for each incident. Some attacks, like a root compromise, are more serious than other types. The more serious the threat, the swifter the response needs to be. This is where the escalation becomes important, because a response needs to be formulated in minutes, not hours, in order to stop an attack and be able to gather evidence against an attacker. For each incident, a response time needs to be assigned. If the appropriate party does not respond within the allotted time, the incident should be escalated to the next level, and so on through the list of contacts. Response times do not have to be assigned individually. They can be grouped depending on the severity of the incident and what needs to be done in response to the incident. One idea is to create three priority levels:
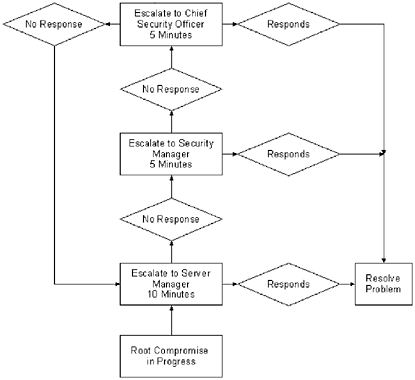
Figure 18.2 outlines a sample escalation process. In this case a root compromise is in progress when a server administrator notices it. The server administrator has to escalate to the server manager. If the attack happens during the day, this is no problem, but if it happens at night the escalation point may not be on premises. Figure 18.2. A sample escalation process. A root compromise occurs, the security administrators notice it in progress and escalate to the server administration manager. If response occurs within the allotted time, the problem is resolved; otherwise , it continues to escalate. In cases where the contact is not on premises he or she should be paged or called. As soon as the first attempt to contact the escalation point is made, the timer should start. While waiting for the escalation contact to call in, it is a good idea to begin taking notes and documenting what is happening. If the initial escalation point does not call in within the allotted time, then the server administrator should attempt to reach the backup. The backup will have less time to call in, because this is such an important issue. Again, if the backup does not respond within the allotted time the next escalation point should be tried (in this case the CSO). If an incident is escalated through the entire chain of command with no response, the process should start all over again. Obviously, for this escalation process to be effective (see Figure 18.2), current contact information should be made available for all employees in the escalation chain. Ideally, all employees who are part of the escalation should have pagers or cell phones issued by the company. This information should not only be current, but also listed on paper, with regular updates also handed out in paper form. If an attacker does manage to compromise the database server, it is possible that he or she will find these escalation procedures, and delete them, or delete pertinent information such as phone numbers . The escalation point does not have to be on site. The person simply has to be able to authorize the administrator to take a server offline, and may have to be responsible for contacting other parties involved in the incident, as well as contacting authorities. In some cases, the infected boxes should be taken offline immediately. For example, if a new worm is found on a workstation, but it has not had a chance to spread, the workstation can be disconnected from the network. NOTE Notice the phrasing above ”"disconnected from the network," not " powered down." A virus or worm may contain commands to erase a hard drive, or destroy the boot sector of a disk, so an infected machine should never be turned off until the virus/worm has been removed or a server administrator inspects it. Each type of incident should be broken down with a separate escalation process. The escalation process should include the steps to be taken before a call is made, what should be done while waiting for a response, and the escalation path , in case there is no immediate response. Again, it is important to remember that only the escalation contacts should make the call as to whether a server, or other network device, should be taken off the network. Only the top escalation point, in this example the CSO, should make the decision to take the entire network offline. |
EAN: 2147483647
Pages: 131