Approaching Information Integration
| So, now that we know what information-based application integration is, the larger question is, How do we approach our problem domain? Although there are many different ways to address information integration within an application integration solution set, I've found the best way is to follow these steps:
In short, implementing an application integration solution demands more than the movement of data between databases and/or applications. A successful solution requires that the enterprise also define both how that information flows through it and how it does business. Identify the DataUnfortunately, there are no shortcuts to identifying data within an enterprise. All too often, information about the data, both business and technical, is scattered throughout the enterprise and of a quality that ranges from "somewhat useful" to "you've got to be kidding me!" The first step in identifying and locating information about the data is to create a list of candidate systems. This list will make it possible to determine which databases exist in support of those candidate systems. The next step requires the determination of who owns the databases, where they are physically located, relevant design information, and such basic information as brand, model, and revisions of the database technology. Any technology that can reverse-engineer existing physical and logical database schemas will prove helpful in identifying data within the problem domains. However, while the schema and database model may give insight into the structure of the database or databases, they cannot determine how that information is used within the context of the application. The Data DictionaryDetailed information can be culled by examining the data dictionaries (if they exist) linked to the data stores being analyzed. Such an examination may illuminate such important information as
While the concept of the data dictionary is fairly constant from database to database, the dictionaries themselves may vary widely in form and content. Some contain more information than others. Some are open. Most are proprietary. Some don't even exist which is often the case with less sophisticated software. Integrity IssuesWhen analyzing databases for IOAI, integrity issues constantly crop up. In order to address these, it is important to understand the rules and regulations that were applied to the construction of the database. For example, will the application allow the update of customer information in a customer table without first updating demographics information in the demographics table? Most middleware fails to take into account the structure or rules built into the databases being connected. As a result, there exists the very real threat of damage to the integrity of target databases. While some databases do come with built-in integrity controls, such as stored procedures or triggers, most rely on the application logic to handle integrity issues on behalf of the database. Unfortunately, the faith implicit in this reliance is not always well placed. Indeed, all too often it is painfully naive. The lack of integrity controls at the data level (or, in the case of existing integrity controls, bypassing the application logic to access the database directly) could result in profound problems. Application integration architects and developers need to approach this danger cautiously, making sure not to compromise the database's integrity in their zeal to achieve integration. Perhaps this is where a decision to use another application integration level as a primary point of integration might be considered. Data LatencyData latency the characteristic of the data that defines how current the information needs to be is another property of the data that needs to be determined for the purposes of application integration. Such information will allow application integration architects to determine when the information should be copied, or moved, to another enterprise system, and how fast. While an argument can be made to support a number of different categories of data latency, for the purpose of application integration within the enterprise, there are really only three:
Real-time data is precisely what it sounds like information that is placed in the database as it occurs, with little or no latency. Monitoring stock price information through a real-time feed from Wall Street is an example of real-time data. Real-time data is updated as it enters the database, and that information is available immediately to anyone, or any application, that requires it for processing. While zero-latency real time is clearly the goal of application integration, achieving it represents a huge challenge. In order to achieve zero latency, application integration implementation requires constant returns to the database, application, or other resource to retrieve new and/or updated information. In the context of real-time updates, database performance must also be considered while one process updates the database as quickly as possible, another process must be simultaneously extracting the updated information. The successful implementation of zero latency presents architects and developers with the opportunity to create such innovative solutions as service-level application integration, where business processes are integrated within the application integration solution. In many cases, SOAI makes better sense than IOAI solutions, because it allows data and common business processes to be shared at the same time. The downside to SOAI is that it is also the most expensive to implement. We'll find out more about that in the next few chapters.
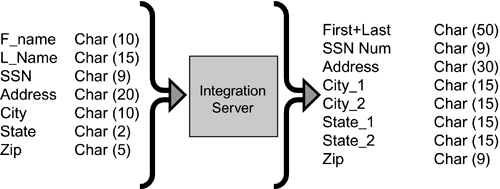
Near-time data refers to information that is updated at set intervals rather than instantaneously. Stock quotes posted on the Web are a good example of near-time data. They are typically delayed 20 minutes or more, because the Web sites distributing the quotes are generally unable to process real-time data. Near-time data can be thought of as "good-enough" latency data. In other words, data only as timely as needed. Although near-time data is not updated constantly, it still faces many of the same challenges as real-time data, including overcoming performance and management issues. One-time data is typically updated only once. Customer addresses or account numbers are examples of one-time information. Within the context of application integration, the intervals of data copy, or data movement, do not require the kind of aggressiveness needed to accomplish real-time or near-time data exchange. The notion of data typing goes well beyond the classification of the data as real-time, near-time, or one-time. It is really a complex process of determining the properties of the data, including updates and edit increments, as well as the behavior of the data over time. What do the applications use the particular data for? How often do they use it? What happens with the data over time? These are questions that must be addressed in order to create the most effective application integration solution. Data StructureAnother identifying component of data is data structure. How information is structured, including the properties of the data elements existing within that structure, can be gleaned from a knowledge of the data format. Likewise, length, data type (character or numeric), name of the data element, and type of information stored (binary, text, spatial, etc.) are additional characteristics of the data that may be determined by its format. Resolution of data structure conflicts must be accomplished within such application integration technologies as integration brokers and/or application servers. Different structures and schemas existing within the enterprise must be transformed as information is moved from one system to another. The need to resolve these conflicts in structure and schema makes knowing the structure of the data at both the source and target systems vital. Our discussion of integration broker technology in Chapter 9 will deal with how such brokers are able to adapt to differences in data formats found in different databases that exist within the enterprise. For now, it is enough to note that message brokers are able to transform a message or database schema from one format to another so that it makes sense, both contextually and semantically, to the application receiving the information (see Figure 2.7). Often, this needs to be accomplished without changing the source or target applications, or the database schemas. Integration broker technology allows two or more systems with different data formats to communicate successfully. Figure 2.7. Integration servers are able to transform schemas and content, accounting for the differences in application semantics and database structure between applications and databases.
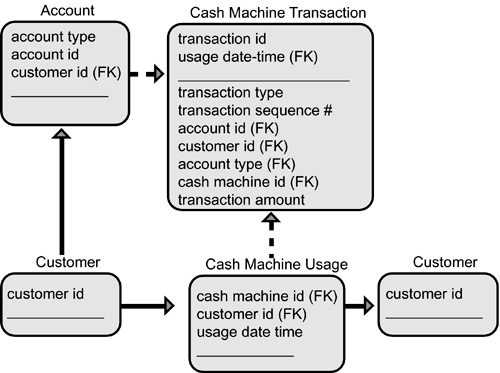
Catalog the DataOnce the logical and physical characteristics of the databases to be integrated are understood, it is time to do the "grunge" work data cataloging. In the world of application integration, data cataloging is the process of gathering metadata and other data throughout the problem domain. Once accomplished, it is possible to create an enterprise-wide catalog of all data elements that may exist within the enterprise. The resulting catalog then becomes the basis of understanding needed to create the enterprise metadata model the foundation of IOAI. For most medium to large enterprises, the creation of this data catalog is a massive undertaking. In essence, it demands the creation of the "mother of all data dictionaries," a data dictionary that includes not only the traditional data dictionary information, but also all the information that is of interest to application integration system information, security information, ownership, connected processes, communication mechanisms, and integrity issues along with traditional metadata such as format, name of attribute, and description. While there is no standard for cataloging data within application integration projects, the guiding principle stands clear: the more information, the better. The catalog will become both the repository for the application integration engine to be built and the foundation to discover new business flows. It will also become a way to automate existing business flows within the enterprise. It is an understatement to suggest that this catalog will be huge. Most enterprises and trading communities will find tens of thousands of data elements to identify and catalog, even after reducing redundancies among some of the data elements. In addition to being huge, the data catalog will be a dynamic structure. In a very real sense, it will never be complete. A person, or persons, will have to be assigned to maintain the data catalog over time, ensuring that the information in the catalog remains correct and timely, and that the architects and developers have access to the catalog in order to create the application integration solution. Logical ModelJust as with traditional database design methods, the enterprise metadata model used for IOAI can be broken into two components: the logical and the physical. And, just as with the former, the same techniques apply to the latter. Creating the logical model is the process of creating an architecture for all data stores that are independent of a physical database model, development tool, or particular DBMS (e.g., Oracle, Sybase, or Informix). A logical model is a sound approach to an application integration project in that it will allow architects and developers to make objective IOAI decisions, moving from high-level requirements to implementation details. The logical data model is an integrated view of business data throughout the application domain, or data pertinent to the application integration solution under construction. The primary difference between using a logical data model for application integration versus traditional database development is the information source. While traditional development, generally speaking, defines new databases based on business requirements, a logical data model arising from an application integration project is based on existing databases. At the heart of the logical model is the Entity Relationship Diagram (ERD). An ERD is a graphical representation of data entities, attributes, and relationships between entities (see Figure 2.8) for all databases existing in the enterprise. Figure 2.8. Entity Relationship Diagram depicting the logical enterprise information model.
Computer-Aided Software Engineering (CASE) technology is but one of the many tools to automate the logical database modeling process. Not only do these tools provide an easy way to create logical database models, they can also build logical database models into physical database models. In addition, they create the physical schema on the target database(s) through standard middleware. Building the Enterprise Metadata ModelOnce all the information about all the data in the enterprise is contained in the data catalog, it is time to focus on the enterprise metadata model. The difference between the two is sometimes subtle. It is best to think of the data catalog as the list of potential solutions to your application integration problem and to think of the metadata model as the IOAI solution. The metadata model defines not only all the data structures existing in the enterprise, but also how those data structures will interact within the application integration solution domain. Once constructed, the enterprise metadata model is the enterprise's database repository of sorts: the master directory for the application integration solution. In many cases, the repository will be hooked on to the integration broker and used as a reference point for locating not only the data, but also the rules and logic that apply to that data. However, the repository is more than simply the storage of metadata information. It is the heart of the ultimate application integration solution, containing both data and business model information. A metadata repository built with the processes outlined in this chapter will not only solve the IOAI problem, it will also provide the basis for other types of application integration, as well. We'll discuss more about this in the next several chapters. As in the world of client/server and data warehousing, the process builds up from the data to the application (and from the application to the interface, if necessary). This "hierarchical" flow identifies IOAI as the foundation for the larger application integration solution. Physical ModelThe myriad of database types in any given enterprise minimizes the importance of the physical enterprise model because, with so many database types, the physical model will rarely be used. The reason is clear there is simply no clear way to create a physical model that maps down to object-oriented, multidimensional, hierarchy, flat-file, and relational databases, all at the same time. However, if those databases are to be integrated, some common physical representation must be selected. Only then can the model be transformed as required. Our discussion of the physical model is only for those times when it is possible to map the logical to the physical. That is, those times when an enterprise uses a homogeneous database approach, usually all relational. The input for the physical model is both the logical model and the data catalog. When accessing this information, consider the data dictionary, business rules, and other user processing requirements. |
EAN: 2147483647
Pages: 220