Investigation Required in Selecting a Service Provider
| With private-line, ATM, or Frame Relay services, the selection of a service provider typically is based on "speeds and feeds," or an evaluation of service providers based on the network's bandwidth, coverage, and cost. In Layer 3 IP/MPLS VPNs, selecting a service provider is far more complicated than a simple "speeds and feeds" evaluation. This is because these VPN services require a stronger integration of the enterprise network and the service provider's network. In addition, many enterprises want to ensure that their WAN can handle more than just enterprise data. Voice and video integration with data, whether performed by the enterprise or offered as a service by the service provider, place more stringent requirements for data delivery on the network. Coverage, Access, and IPThe typical discussion of network coverage between the enterprise and service provider changes with the adoption of real-time services, such as voice and video. When network latency is less of a concern, many enterprises do not ask about density of transfer points or IP access nodes in the network. Consider the simplest of examples, as shown in Figure 2-1. This service provider offers an IP/MPLS VPN service in the U.S. Although it offers access via private line to almost any location in the U.S., its only IP access node is in Chicago. At a minimum, traffic from one site to another must travel through the Chicago IP access node to reach the other site. Although this does not add significant latency for traffic from Los Angeles to New York, it does add a fairly significant amount of latency to the path between Los Angeles and San Francisco. Figure 2-1. Layer 2 Network Access to a Single IP Node in Chicago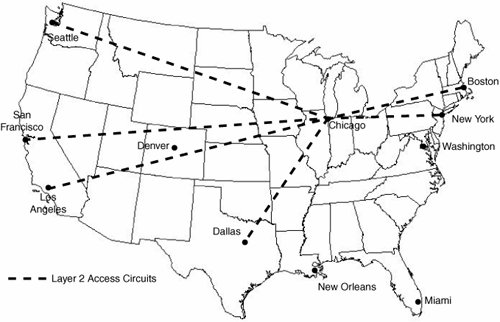 Enterprises must now be concerned not only with where they can get access to the network, but also with where these "transfer points" exist. Therefore, they must evaluate how traffic will likely flow between any sites on the network given a service provider's access coverage and IP access node coverage. When planning Layer 2 WANs, the enterprise network manager needs to take care of the placement of hubs in the topology to minimize latency and to optimize traffic paths. This job is removed in IP/MPLS Layer 3 VPNs, but it is wise to perform a once-off check of the provider network to assure yourself that enough transfer points exist within the provider network to offer optimized routing. These transfer points are where the IP intelligence resides. Some service providers still maintain extensive Layer 2 access networks before traffic hits an intelligent IP node. Figure 2-1 shows the worst-case scenario, in which only one location has IP intelligence and all traffic is backhauled over Layer 2 to reach that IP intelligence. Financial Strength of the Service ProviderAn enterprise's move to use IP/MPLS VPN services also changes some of the considerations that must be made about the service provider's financial strength. In traditional private-line, ATM, or Frame Relay networks, these services are a commodity for the most part. Because they are generally simple point-to-point dedicated or virtual circuits, it is simple to mix and match multiple network service providers to protect against the case where a service provider might fail, whether for technical or business reasons. Because Layer 3 IP/MPLS VPN services are more integrated with enterprise networks, it is no longer possible to mix and match the network's components at will; instead, a holistic network service is chosen. It is for this reason that selecting a service provider is more of a strategic choice than selecting an inexpensive commodity service. Additionally, because there is a higher level of integration, and there are many more factors to consider in selecting a service provider, enterprises are no longer at a point where they can call another service provider on very short notice and have a replacement service put into place. Following the Internet bubble burst, many service providers suffered hardship, declared bankruptcy, or in some cases shut down, leaving customers scrambling to find other service providers. For these reasons, the enterprise must know the service provider's financial strengths and weaknesses. Enterprise procurement departments already investigate many of the basic fundamentals of financial strength (cash flow, profit, and sustainability), but an enterprise network administrator must also ask about service-specific items. First, an enterprise must ask about the service provider's commitment to the IP/VPN services that are being offered. Many Layer 2 IP/MPLS VPN services offered by service providers are still in their infancy. Consequently, the enterprise should ask questions about the "health" of the service offering. Here are some questions that an enterprise might ask:
It is quite simple for a service provider representative to concoct misleading answers to these questions. This can lead the enterprise network manager to conclude that there is strong commitment to the service, when in fact it is an experiment as far as the service provider is concerned. However, verification of road map items and willingness to deploy them when available with a reference customer should be good validation if it is available. ConvergenceMany enterprises today are looking to consolidate communications providers to reduce the costs of managing vendors and to take advantage of the aggregation of services into a single delivery mechanism. It may be desirable for the enterprise to use a single service provider for many communications service needs, including data transport, voice over IP (VoIP) access to the public switched telephone network (PSTN), and "IP Centrex" services. Service provider IP/MPLS VPN offerings usually include the ability to connect a site to the Internet, with or without managed security, including firewalls and intrusion detection. This may be valuable to an enterprise that wants to offload traffic to and from the Internet using its intranet WAN. Many of the converged voice offerings from service providers are undergoing development. It may not make sense for an enterprise to undertake a significant replacement of its voice infrastructure and data infrastructure at the same time. This is especially true if the enterprise already has significant investment in older voice PBX technologies. However, enterprises such as Acme, Inc., should look at the current and planned service offerings from potential service providers and keep these capabilities in mind when selecting its service provider. In Acme's case, it has a fairly extensive PBX infrastructure that can connect to the PSTN via traditional ISDN PRI-based connectivity. However, Acme believes that in the future it will move toward IP-based voice on its network. Therefore, it wants to ensure that the service provider it selects will offer services compatible with that converged offering. More specifically, Acme believes that its transition toward IP-based voice in its network will require a service provider that offers a Session Initiation Protocol- (SIP-) based service. This service would allow Acme to configure its IP-based voice network to send VoIP directly to the network cloud for access to the PSTN. In addition, on the horizon are a variety of other service offerings that service providers are looking at for development. Content distribution services would allow the enterprise network to distribute data securely throughout the service provider's network. They also would allow remote offices to pull data from the closest node, reducing latency and enhancing application performance. Disaster recovery services can use that same framework to offer secure short-term and long-term storage and hosting of critical business data in case of a disaster in a primary data center. TransparencyTransparency of the IP/MPLS VPN service is the single most critical technical issue to consider when planning a migration from time-division multiplexing (TDM) or ATM/Frame Relay. The benefits of simplified WAN capacity planning, design, and so on from the enterprise perspective have been defined, but they are not free. On more than one occasion, problems have arisen when an enterprise believed that the IP/MPLS VPN service could be deployed as a direct replacement for legacy WAN technologies and the result was not as expected. The three main issues related to transparency that will be examined in depth from a technical perspective are as follows:
Each issue has its own chapter to address the technical considerations pertinent to the role of that technology in delivering overall service in the IP/MPLS VPN. Here, examples taken from real-world deployments will give you an overview of why each of these issues is important. Taking QoS first, it is a simple matter to understand that most enterprises establish their own marking schemes for traffic and that it is highly likely that many enterprises will come up with schemes that are different from each other. Many well-known applications have standard markings, such as Differentiated Services Code Point (DSCP) value 46 for voice. However, there are no such standards for how an application requiring a given amount of loss, latency, and jitter to work properly should be marked. There are moves within the Internet Engineering Task Force (IETF) to standardize which application types should be marked with what DSCP value. The moves would help, but for now, you can safely assume that many enterprises will select different markings for perfectly legitimate reasons. Given that a service provider is faced with many different marking schemes from its multiple customers, it is not possible to define a single matching QoS scheme within the provider that matches all possible enterprise marking schemes. So clearly, there has to be some translation or matching when the enterprise seeks to use a QoS-enabled VPN service from a service provider. Where this translation or matching takes place is a matter for negotiation within the definition of the service. For scalability concerns, providers may want to distribute the marking of traffic from the provider edge (PE) to customer edge (CE) device, because it reduces the processing load on their PE device. Typically, the PE is configured with a specific number of classes that require a specific marking for traffic to gain entrance into each class. To accommodate this, each CE device can be configured to map traffic to each of the service provider-defined markings to gain access to the required CoS in the service provider's network. This is fairly straightforward in concept but requires some care in real-world deployment. The first hurdle to overcome is that enterprises tend to define more classes within their networks than service providers. The reason for this is that enterprises define multiple classes for application separation, whereas service providers define classes based on service type. Application separation in enterprises is implemented so that traffic from one application does not consume bandwidth provisioned for another application, typically by the use of bandwidth allocation within a class in the QoS configuration. For service provider scale networks, it is not feasible (or even technically possible) to define a separate class and queue for each possible application that any enterprise would want to provision bandwidth for. Instead, providers configure classes based on the type of service (ToS) they delivertypically a low-latency service operated with priority queuing, an assured bandwidth class to offer bandwidth guarantee, and a best-effort class. The thinking is that if the priority and bandwidth assurance classes are sized to meet the aggregate demand of the edge classes requesting that service, the more granular commitments made on a per-application basis are met. For example, if an enterprise needs 256 kbps for Oracle, 128 kbps for FTP, and 128 kbps for Telnet traffic, the enterprise network can be configured with three classes that assure bandwidth for each application. Each of these classes requires the same service (assured bandwidth) and can be placed in the same service provider class if that class reserves the sum of bandwidth allocations (512 kbps). Clearly, some planning needs to go on to ensure that these types of mappings provide the desired result. This is not the end of the story, however. Service providers typically police these classes to ensure that enterprises get only what is paid for. In the case of the voice class, if an enterprise transmits more traffic than is subscribed to, traffic is normally dropped, so it is not much of an issue. However, in the data class case, it is common practice to have excess traffic re-marked in some way, which can be a source of problems. There are two prime sources of problems related to this re-marking practice. The first problem relates to how TCP operates; the second problem relates to the capabilities of the service provider's PE equipment and its impact on enterprise marking schemes. Taking the TCP issue first, if the enterprise transmits more traffic for a class than is subscribed to, the provider may mark this down in priority to a DSCP value that will admit this excess traffic to a lower-priority class. For example, there may be a high-priority data class and a best-effort class. If the provider marks down exceeding traffic from the high-priority marking to the best-effort marking, and those packets become a service from the best-effort queues in the network, out-of-sequence packet reordering is likely to occur. Out-of-sequence packet reordering has dramatic effects on TCP throughput. If a host has to reorder packets in a TCP stream before passing them to an application, the number of packets that are sent is reduced substantially while the host waits for the out-of-sequence packets. The reason out-of-sequence reordering occurs in this case is that a class is associated with a queue. Thus, different queues drain at different rates, so if packets from the one flow are in different queues, reordering is highly likely to occur. This does not mean that a service provider should not be able to mark down exceeding traffic. A common practice is to change the DSCP marking of exceeding traffic to a value that keeps it in the same class and therefore avoids the packet reorder issue. However, the new marking identifies the packet as the first to be dropped should congestion occur via the use of Weighted Random Early Detection (WRED) configuration. Clearly, you need to understand this point when you are selecting VPN services, because the provider configuration can have a significant impact on the throughput you can obtain over the WAN links. Note If you are unfamiliar with this concept, http://www.faqs.org/rfcs/rfc2597.html is a good place to start. It discusses the reasons for keeping traffic from a specific flow within the same class. The second issue related to re-marking is driven by the capabilities of the PE router used by the provider. For a VPN to be private, the enterprise needs to have the flexibility to mark packets any way it sees fit and for the service provider not to change those markings. TDM and Frame Relay/ATM networks do not change IP QoS markings, so neither should an IP/MPLS VPN. This should be achievable. As in IP/MPLS VPNs, the provider appends a header to the packets coming from the enterprise. That way, the service provider can mark the packets any way it wants to for treatment within its network, leaving the enterprise marking untouched. The issue arises when there are limitations in how PE devices can police and mark traffic in combination. In some PE devices, the only way to set the EXP field in the MPLS header (which is the field used for QoS policies in an MPLS VPN network) is to copy that value from the IP precedence field in the original IP packet sent from the enterprise CE. This is fine until a packet needs to be re-marked if it is exceeding the contracted rate. With the restriction just described, the PE device has to mark down the IP precedence field in the IP packet and then copy that value to the MPLS EXP field. As soon as the packet has traversed the provider network and the MPLS header is stripped off, the packet no longer has the IP precedence field marking it was sent into the VPN with. It also is not treated appropriately after it is back in the enterprise QoS domain. Clearly, a good understanding of how the service provider treats exceeding packets is necessary when designing the end-to-end QoS scheme. A full discussion of this concept is given at http://www.faqs.org/rfcs/rfc3270.html. RFC 3270 discusses the options for how DSCP values can be mapped to the MPLS experimental bits to preserve DiffServ behavior over the MPLS portion of the WAN. Figures 2-2 and 2-3 show the two main modes of this RFC: Uniform mode and Pipe mode. Figure 2-2. Uniform Mode MPLS Tunneling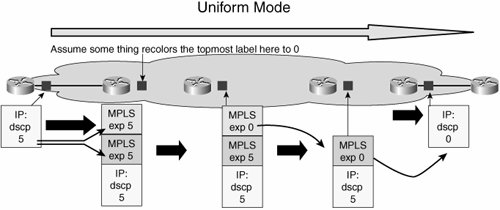 Figure 2-3. Pipe Mode MPLS Tunneling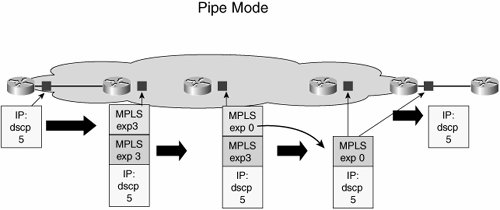 From the enterprise perspective, the primary issue to coincide is how the QoS marking is affected in the original packet by service provider operations. The Uniform mode of Figure 2-2 shows that a mark-down action within the provider cloud affects the DSCP value of the IP packet transmitted from the egress PE back toward the enterprise. This often is not what an enterprise wants to see, because what was a differentiated packet on entry to the MPLS VPN is now unmarked. Figure 2-3 shows Pipe mode, which allows the provider to mark down the MPLS EXP field for exceeding traffic, queue within the egress based on this marked-down value, and transmit the packet with its original DSCP intact. IP Version 6Although predominantly U.S.-based, Acme does have operations in other regions of the world. Therefore, IP version 6 (IPv6) is a technology being planned for in the current WAN migration. The reasons for this geographic diversity regarding IPv6 importance are several; however, one of the main reasons is the distribution of existing IP version 4 (IPv4) address space. For example, at one point, the Massachusetts Institute of Technology (MIT) had more IPv4 address space assigned to it than all of China. Additionally, applications that are popular in Asia do not lend themselves so well to the use of Network Address Translation (NAT), and they require dedicated IP addresses. An example of this is the use of the buddy-finder mechanism in Japan. A mobile phone can be programmed with the user's interests and can alert him to the presence of like-minded people in a public setting, effectively making introductions. This type of direct peer-to-peer communication is difficult to support in a scalable way if handsets are being dynamically assigned IP addresses. Beyond these types of applications, IP-enabled appliances are becoming a reality, putting further pressure on the number of IPv4 addresses available. Currently, the main driver for IPv6 deployment is mobile data access, but it is expected that over time, IPv6 importance for other applications will grow. Migrating to an IP/MPLS VPN gives Acme the opportunity to have IPv6 supported over the same network connection delivered by the service provider. Just as transparency issues were a concern for IPv4-based communications over a VPN, similar issues arise when you look at how any provider will support IPv6 services. The rest of this section reviews how service provider networks are being built to support IPv6 in a VPN environment so that the enterprise can better understand the capabilities of providers offering IPv6 support. Chapter 4, "IP Routing," contains a case study of how Acme implemented a tunneling scheme to support IPv6 traffic in the absence of native IPv6 support within the service provider network. When looking at the requirements to support IPv6 services from a service provider perspective, stability and return on investment (ROI) are of prime concern. IPv4 backbones with MPLS support are now very stable in the major providers, but this did not come without significant investment. The thought of adding dual-stack IPv4 and IPv6 routers to this stable backbone is not attractive. Equally, the drive to support more services over the same infrastructure to improve ROI is very strong for service providers. Service providers that have deployed MPLS in their core networks are well positioned to offer IPv6 services using that same infrastructure. From the enterprise perspective, the service offerings to look for are 6PE and 6VPE. 6PE (which refers to a version 6-capable PE router) can be thought of as using MPLS tunnels to transport native IPv6 packets. As such, 6PE is useful to both service providers and enterprises, but it does not offer the separation of a VPN service. To offer a similar level of separation between different enterprises using the same provider backbone, 6VPE (which refers to a version 6 VPN-capable PE router) is required. It supports the concept of IPv6 addresses within a service provider-operated virtual routing/forwarding instance (VRF) in the PE router. It is expected that 6VPE will become the more dominant model in terms of deployment. To help you understand these service provider offerings, a brief overview is given here. Also, Figure 2-4 shows the main components of a 6PE service within a provider network. Figure 2-4. Overview of 6PE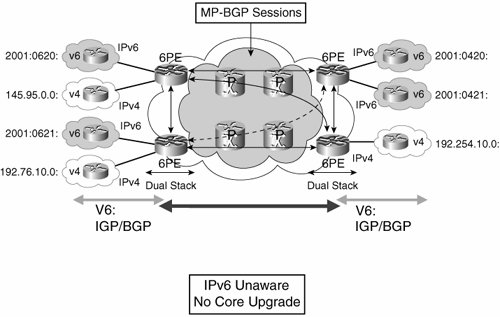 In the network shown in Figure 2-4, the MPLS core infrastructure is unaware of IPv6. The only upgrades necessary are on the edge PE routers. Enterprise CE routers exchange IPv6 routes directly with the provider PE routers, just as is done with IPv4 in regular VPN. The difference here, though, is that IPv6-enabled interfaces on the PEs are separate from the IPv4 VPN-enabled interfaces. The reason for this is that for regular IPv4 VPN, the customer-facing interface on the PE is made a member of a VPN by putting the interface into a VRF. With plain 6PE, the VRF is not IPv6-aware, so any IPv6 traffic must come into the PE on a different interface. From the perspective of forwarding traffic over the core, though, the same concepts that are used in MPLS forwarding of IPv4 still hold. With reference to Figure 2-4, this means that the regular Interior Gateway Protocol (IGP) used by the service provider identifies labels that transport packets to their destination over the core. Multiprotocol Border Gateway Protocol (BGP) is used to exchange labels that associate IPv6 destinations with IPv6 next-hop values derived from IPv4 destinations. The exact mappings of label values to next-hop destinations are not important to understand from an enterprise perspective. The main point is that with 6PE, IPv6 reachability can be provided for the enterprise over the stable IPv4 provider network, but only via a separate interface. Taking IPv6 service from a service provider that supports only 6PE is better than not having the service at all. However, it requires more work from the enterprise perspective when compared to 6VPE, which is examined next. 6VPE is different from 6PE in that a 6VPE router maintains separate routing tables on a per-enterprise basis to maintain separation as in regular IPv4 MPLS VPN deployments. In regular MPLS VsPN, route distinguishers were added to enterprise routes to ensure that overlapping addresses could be supported. It is the same for IPv6 in a 6VPE environment. IPv6 routes are made into VPNv6 routes within the PE node itself. The route target extended community is used to advertise those unique VPNv6 routes via multiprotocol BGP to other 6VPE nodes. As soon as VPNv6 information is distributed between the 6VPE-capable routers within the provider network, the 6VPE router adds labels to forward these packets based on label values rather than IPv6 addresses across the core. When running 6VPE, the provider delivers more functionality to the enterprise than a 6PE provider, because each interface on a 6VPE router has both IPv4 and IPv6 stacks and has a VRF membership for each on it. So the 6VPE service may be charged at a higher rate to reflect the greater functionality and cost of operation from the provider's perspective. The transparency issues raised for IPv4 VPN service concerning routing protocol, QoS, and multicast still need to be considered for IPv6; however, there are a few additional considerations:
Provider Cooperation/Tiered ArrangementsFor Acme, a key issue is how the new WAN can deliver service across diverse geographic regions when no one service provider offers a network covering all of them. Can service providers cooperate to provide seamless service? Can services be maintained if they traverse the public Internet? Additionally, as has been stated, due to the more intimate nature of the relationship between enterprise and service provider required by IP/MPLS VPNs, it is preferable from the enterprise perspective to have to invest in only one of those relationships. So should Acme arrange a "prime contractor" relationship and have its preferred service provider negotiate service in regions where it does not have a presence and be responsible for organizing the delivery of service there? At a technical level, there are no impediments to service providers being able to interconnect their networks to provide seamless connectivity for enterprises. The reality, though, is that differences in operational practice, design philosophies, and political issues currently typically keep that level of cooperation between service providers from being pervasive across the globe. For Acme, the choice is clear. It establishes a preferred vendor of choice for each major region in the globe. It also provides separate handoffs from the internal network in each geography to these preferred regional vendors. This typically breaks down into a VPN provider for America, one for Europe, and one for Asia Pacific, with Acme providing the interconnect between these service providers. This provides Acme with the flexibility to control addressing, QoS marking, and multicast traffic between service providers in a way that suits their needs, rather than expecting service providers to cooperate to achieve the desired result. Enhanced Service-Level AgreementAs soon as the jump has been made to integrate Layer 3 IP operations with a service provider, the SLAs that exist for the service can be enhanced and made more specific. With Frame Relay or ATM, SLAs typically refer to some sort of availability, the committed rate, and perhaps some bursting above the committed rate. This is for any traffic traversing the link. It is not specific to any application that may need better or worse treatment than other applications during congestion time. With Layer 2 services over the WAN, the practice has been to shape traffic outbound from the CE router to the committed rate and have that CE perform all queuing and drop functions. This does not take advantage of burst within the service provider's network. With the VPN being a Layer 3 service, it is now possible for the service provider's devices to understand which packets are voice, high-priority, or best-effort and which SLA parameters can be written for each of these across the WAN. The major benefit of this change is that bandwidth can be more efficiently allocated for access links. In the case where the service provider's network is unaware of which packets are voice, high-priority, or best-effort, all packets need to be treated as if they are high-priority, meaning low loss, latency, and jitter. For many data or best-effort applications, the low latency delivered is not required. It is not bad to give an application better service than it needs to operate, just wasteful and expensive as far as resources. The enhanced SLAs available from providers delivering Layer 3 VPN service provide the granularity needed for enterprises to consider purchasing different types of bandwidth. This means a given amount of low-latency bandwidth, a given amount of assured bandwidth, and a given amount of best-effort bandwidth to more accurately reflect the needs of the enterprise traffic. The benefit here is that only the minimum amount of expensive low-latency bandwidth needs to be purchased, resulting in a lower overall bill for bandwidth from the service provider. Chapter 5, "Implementing Quality of Service," discusses how to determine the different amounts of bandwidth required. Chapter 3, "Analyzing Service Requirements," addresses some of the specific performance requirements for traffic of different types. Customer Edge Router ManagementOne of the first issues to resolve when considering a Layer 3 VPN service is who will own and operate the CE router. This is not a straightforward question, because both alternatives have pros and cons. Consider the case in which the enterprise decides to own and operate the CE router, which is the more common model in the U.S. The enterprise has the freedom to upgrade to different Cisco IOS versions when required and make use of new features as they become available. It does, however, make the service more complex to support from the enterprise perspective, because it now has to resolve access circuit issues in cooperation with the service provider. Additionally, it is impossible for the service provider to offer service guarantees covering the access circuit when the provider does not manage the CE. This issue is worthy of more examination. The most common place for congestion to occur on a network is over the access link between the campus LANs and the service provider backbone, which is the most constrained bandwidth link. The performance of that link in terms of the loss latency and jitter it provides to the applications that use it is almost totally dependent on the amount of traffic sent to the link by the enterprise. Of course, this is not under the control of the service provider in the unmanaged CE case, so it is not a simple matter to offer performance guarantees from a provider perspective. As a simple example, suppose the enterprise subscribes to a 256-kbps access link service and sends 2 Mbps to the egress interface toward the provider. Queues fill, packets are dropped, and latency grows, even though the provider has done nothing to generate that poor network performance. Generally, unmanaged CEs have not had performance guarantees attached to them for the access link, but managed CEs have. We will look at this issue again in the section "Customer Reports and SLA Validation." For the case in which the service provider manages the CE, more specific guarantees for access link performance can be given, because the provider owns, operates, and controls the CE. Therefore, it can be configured to not attempt to send too much traffic over the access link. It also can report back to the provider if queues fill up because too much traffic was sent to that egress port. In some cases where the provider offers BGP only as a CE-to-PE routing protocol, this can also offload the BGP configuration from enterprise to provider. The downside is that the CE is now upgraded only according to the provider's schedule and for releases it approves of, which may or may not match the enterprise service needs. Having ownership of the CE also lets the provider set up probes and report on performance from a CE-to-CE perspective, a much more relevant measurement than the more usual PE-to-PE measurements provided in the unmanaged case. In the case of Acme, a one-off agreement was reached with the service provider such that Acme would own and manage the CEs, but the provider would be given one-off access to the device to set up probes and provider reports on network performance from a CE-to-CE perspective. This is not a usual service offering from providers, but it might be open to negotiation, depending on the contract's size. |
EAN: 2147483647
Pages: 136
- Chapter II Information Search on the Internet: A Causal Model
- Chapter VI Web Site Quality and Usability in E-Commerce
- Chapter VII Objective and Perceived Complexity and Their Impacts on Internet Communication
- Chapter X Converting Browsers to Buyers: Key Considerations in Designing Business-to-Consumer Web Sites
- Chapter XVIII Web Systems Design, Litigation, and Online Consumer Behavior