OLAP and Star Joins
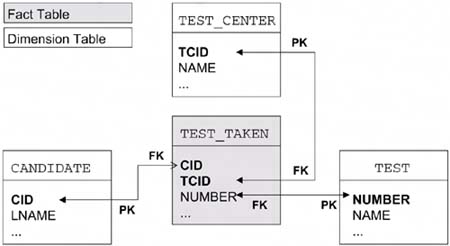
| Databases normally hold large amounts of data that can be updated, deleted, queried, and inserted on a daily basis. Databases in which data is continually updated, deleted, and inserted are known as online transaction processing (OLTP) systems. Databases that hold large amounts of data and do not have a heavy transaction workload but do have a large number of concurrent queries executing all the time are known as decision-support systems (DSS). Certain decision-support systems have fewer queries, but each query can be very complex. These systems allow users to examine the data from various perspectives by performing online analytical processing (OLAP). The functionality of the database is required to provide multidimensional views of relational data without a significant performance effect. DB2 provides a star join access path to assist in the processing of the star schema and snowflake (star schema with further normalized dimensions) data models. Star SchemasThe concept of a star schema is illustrated in Figure 6-3. A business view of a highly normalized database often requires a number of attributes associated with one primary object. Each of these attributes is contained in separate tables. Figure 6-3. Star schema in the DB2CERT database
The following points are characteristic of a star schema design.
This approach allows as few attributes as possible to be stored in the fact table. The benefit of this is that, because the fact table is usually very large, any data duplication in this table would be very costly in terms of storage and access times. If the DB2CERT database were used to store information on a university's entrance examinations, for example, the TEST_TAKEN table could grow enormously. OLAP schemas, such as the star schema, are frequently used for large databases in data warehousing and decision-support systems. These schemas make it very important to access the data in these databases in the optimal manner. Otherwise, the joins involved in the schemas may result in poor performance, owing to the potentially large size and number of the rows and tables being joined. OLAP IndexesA typical star schema may include a large number of indexes because of the ad hoc nature of queries in an OLAP environment. Such an environment is typically not subjected to continual insert or update activity and therefore does not have to suffer from significant performance degradation as a result of index maintenance. The prime considerations of indexes in an OLAP environment are to facilitate the filtering of the large result set as quickly as possible and the joining of the tables. This is particularly important for the fact table, where multiple indexes are defined, especially on combinations of foreign-key columns relating to the dimension tables. The benefit of multiple indexes in this environment is improved query performance against the fact table, as the query can focus on any combination of dimensions. Given that the fact table is the largest table, the application of restrictive join predicates and an efficient access path for the join to this table are significant. The indexes defined on the tables could be either single-column or multicolumn indexes. However, the exploitation of DB2's star join access path uses the most cost-effective multicolumn index on the fact table for access. Some maintenance issues need to be considered when using multiple indexes in the OLAP environment. The first is that multiple indexes will require a certain amount of space, depending on the number of columns in each index and the size of the tables. The second is that there will be a significant one-time cost when building indexes, perhaps during a bulk load. Star JoinsA typical query against databases designed with the star schema consists of multiple local predicates referencing values in the dimension tables and containing join predicates connecting the dimension tables to the fact table. These types of queries are called star joins, as shown in the following example: SELECT NAME, YEAR_TAKEN, AVG(SCORE) AS AVGSC FROM (SELECT T.NAME, YEAR(TT.DATE_TAKEN), TT.SCORE FROM TEST T, TEST_TAKEN TT, TEST_CENTER TC, CANDIDATE C WHERE C.CID = TT.CID AND TC.TCID = TT.TCID AND T.NUMBER = TT.NUMBER AND T.NAME LIKE 'DB2%' AND C.COUNTRY='USA' AND TC.NOSEATS < 10) AS STAR_TABLE GROUP BY NAME, YEAR(TT.DATE_TAKEN); NOTE Prior to version 8, a nested table expression would have been required in this example purely to overcome the limitation that the GROUP BY clause could contain only columns and not expressions. Now, since we have the ability to group by an expression, the YEAR(TT.DATE_TAKEN) expression can be explicitly used in the GROUP BY. In this example, we wish to find the average score of DB2 tests taken by Canadian citizens in the small test centers year by year. A star join query can be difficult to execute efficiently. Even though the intersection of all dimensions with the fact table can produce a small result set, the predicates applied to a single dimension table are typically insufficient to reduce the enormous number of fact table rows. If a join based on related tablesdimension to fact tabledoes not provide adequate performance, an alternative is to join unrelated tables. Joining unrelated tables results in a Cartesian product, whereby every row of the first table is joined with every row of the second table. Performing a Cartesian join of all dimension tables before accessing the fact table may not be efficient. DB2 must decide how many dimension tables should be accessed first to provide the greatest level of filtering of fact table rows using available indexes. This can be a delicate balance, as further Cartesian products will produce a massive increase in the size of the intermediate-result sets. Alternatively, minimal prejoining of unrelated dimension tables may not provide adequate filtering for the join to the fact table. |
EAN: 2147483647
Pages: 175