Locking Issues and Problems
Locking Issues and Problems There are times when too much locking can be a problem, resulting in suspensions , timeouts, or even deadlocks. We will take a look at how these situations can occur. Timeouts and DeadlocksWhile waiting for a lock, a process can exceed an allowable amount of wait time that has been established. A systemwide option determines the maximum time a process can wait before it gets a resource unavailable error. This value is called the RESOURCE TIMEOUT value and is calculated by the following formula:
Table 16-7 shows the resource timeout factors. Table 16-7. Timeout Factors
The result is the timeout value that is always greater than or equal to the RESOURCE TIMEOUT. When the timeout value has been reached, the requesting task is informed of the unavailable resource. There are several conditions that can cause a timeout value to be exceeded by a process, and each returns a different message to a different location. The deadlock time is determined by another system parameter, DEADLOCK TIME (default 5 seconds). This is the time interval between two successive scans for a deadlock. For every deadlock interval, the IRLM will verify whether there are deadlock situations. In those cases, DB2 will inform the task (usually the one that made the smallest number of changes) that a deadlock has occurred. The other tasks will continue without any problems. The main causes of a timeout are the following:
The main causes for deadlocks are the following:
When a timeout or deadlock has occurred, error codes and messages are sent to the following:
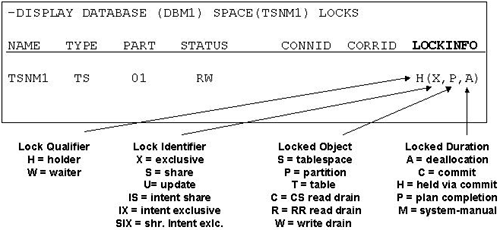
Coding Retry Logic for Locking ErrorsA 911 SQL return code means that a deadlock or a timeout occurred and DB2 has issued a successful ROLLBACK to the last commit point. If the ROLLBACK was not successful, the application will receive a 913 SQL return code signifying that a ROLLBACK was not performed. There is also a 912 SQL return code, which occurs when the maximum number of lock requests has been reached for the database (because insufficient memory was allocated to the lock list). With a 912 or a 913 return code, the application needs to issue a COMMIT or ROLLBACK before proceeding with any other SQL. When a 911 occurs, the choice of whether or not to use retry logic depends on the individual application. If a large amount of work has been rolled back, and if there are other non-DB2 files present, it may be difficult to reposition everything and retry the unit of work. With most 911 situations, a restart process (vendor-supplied or user -written) is generally easier than a programmatic reposition and retry. If a small amount of work was lost, then a simple retry could be performed up to some fixed number of times. It is important not to retry with a breakpoint, since the source of the problem that caused the negative codes might still exist. With the 913 SQL return code, the single statement could be retried, and if successful, the program could simply continue on. However, if repeated attempts at retry logic fail, then the application probably needs to be rolled back. Displaying LocksYou can display the locks that are being held to solve application concurrency problems. By using the -DISPLAY DATABASE (dbname) LOCKS command you can see many properties about a given lock, as shown in Figure 16-1. Figure 16-1. DISPLAY DATABASE LOCKS. Lock Promotion and EscalationIn order to best protect data based on the process, DB2 may choose to increase either the mode of the lock or the size of the lock. This is done through lock escalation and promotion. Lock EscalationLock escalation can occur when the value for LOCKMAX is reached. At this time DB2 will release all of the locks held in favor of taking a more comprehensive lock (i.e., release several page or row locks to escalate to a table lock). DB2 tries to balance the number of locks on objects based upon the amount of concurrent access. The LOCKMAX option will then further determine when/if escalation occurs. NOTE
The value of LOCKMAX is set on the CREATE TABLESPACE statement to define how many locks can be held simultaneously on an object. Locks will be escalated when this number is reached. You can specifically set this value to a number, or if you leave it at the default of SYSTEM (if you use LOCKSIZE ANY; otherwise , the default is 0 for specific object locks such as page, row, table, and tablespace), it will use the number set by the NUMLKTS DSNZPARM. You can turn off lock escalation by using the LOCKMAX = 0 parameter on the CREATE TABLESPACE statement. If you choose to turn off lock escalation, be sure that applications accessing those objects are committing frequently and you have adjusted the DSNZPARM NUMLKTS to allow for more locks to be taken; otherwise, you run the risk of hitting negative SQL codes when you reach the maximum number of locks (without escalation, you could hold more, smaller locks). Lock escalation is there to protect you from taking excessive system resources, so if you turn it off, you will need to control it. If you are CPU-bound, it may not be a good idea to turn off lock escalation because it will take DB2 longer to traverse long chains of locks and it will take more CPU for IRLM latch activity. Lock PromotionThere is a lock mode that will be used for any table, tablespace, or tablespace partition for an SQL statement, and it is reflected in the PLAN_TABLE populated by EXPLAIN in the column TSLOCKMODE if the isolation can be determined at bind time. This is the lock mode that the SQL statement would use for the table or tablespace lock if and only if it had not been raised by a preceding SQL statement. For example, an SQL SELECT statement might have a TSLOCKMODE of IS, yet during execution, it could have been promoted to IX, and that is what the SELECT statement would use. This is called lock promotion, but it generally is not a concernjust a fact. |

| | |
| Team-Fly |
| Top |
EAN: 2147483647
Pages: 163