Triggers
Triggers A trigger is a set of actions that will be executed when a defined event occurs. These are known as active triggers. The triggering events can be the following SQL statements:
Triggers are defined for a specific table and once defined, a trigger is automatically active. A table can have multiple triggers defined for it, and if multiple triggers are defined for a given table, the order of trigger activation is based on the trigger creation timestamp (the order in which the triggers were created). Trigger definitions are stored in the DB2 catalog tables.
Trigger UsageSome of the uses of a trigger include the following:
The triggered action could involve updating data records in related tables. This is similar to referential integrity, but it is a more flexible alternative. We can also use triggers to enforce business rules, create new column values or edit column values, validate all input data, or maintain summary tables or cross-reference tables. They provide for enhanced enterprise and business functionality and faster application development and global enforcement of business rules. Limited only by our imagination , the trigger is our way of getting control to perform an action whenever a table's data is modified. A single trigger invoked by an update on a financial table could invoke a UDF and/or call a stored procedure to invoke another external action, which triggers an email to a pager to notify the DBA of a serious condition. Farfetched? No, it is already being done. Triggers can cause other triggers to be invoked and, through the SQL, can call stored procedures. These stored procedures could issue SQL updates that invoke other triggers. This allows great flexibilitywe can use triggers to enforce business rules, create new column values or edit column values, validate all input data, or maintain summary tables or cross reference tables. The trigger is just a way of getting control whenever a table's data is modified. There is currently a safe limit to the cascading of triggers, stored procedures, and UDFs, which is an execution time nesting depth of 16. This prevents the endless cascading that would be possible. There is a big performance concern here, because if the 17th level is reached, an SQLCODE of 724 is set but all 16 levels are backed out. That could be a significant problem and not something you want to see. The real issue here is processes that are executed outside the control of DB2, since they would not be backed out and it might be very difficult to determine what was changed. There are limitations in the calling sequences; for example, stored procedures that are Workload Manager (WLM)-managed cannot call stored procedures that are DB2-managed. Trigger ActivationA trigger can be defined to fire (be activated) in one of two ways:
Another important feature about triggers is that they can fire other triggers (or the same trigger) or other constraints. These are known as cascading trigger s. During the execution of a trigger, the new and old data values can be accessible to the trigger, depending on the nature of the trigger (before or after). By using triggers you can:
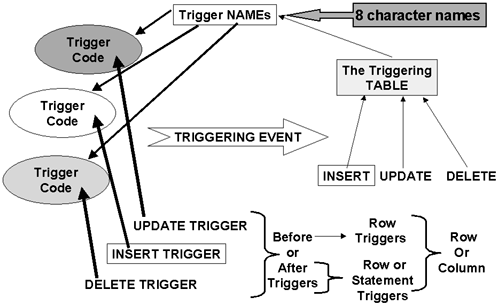
Creating TriggersTriggers are defined using the CREATE TRIGGER statement, which contains many options. The primary options are whether it is a before trigger or an after trigger, whether it is a row trigger or a statement trigger, and the language of the trigger. The language is currently only SQL, but that will probably change in the future. There is even rumor that the SQL procedure language is a candidate for triggers. The phrase MODE DB2SQL is the execution mode of the trigger. This phrase is required for each trigger to ensure that an existing application will not be negatively impacted if alternative execution modes for triggers are added to DB2 in the future. You can have up to 12 types of triggers on a single table. See Figure 15-1. Figure 15-1. Trigger Types NOTE
When adding triggers, the rows that are in violation of a newly added trigger will not be rejected. When a trigger is added to a table that already has existing rows, it will not cause any triggered actions to be activated. If the trigger is designed to enforce some type of integrity constraint on the data rows in the table, those constraints may not be enforced by rules defined in the trigger (or held true) for the rows that existed in the table before the trigger was added. If an update trigger without an explicit column list is created, packages with an update usage on the target table are invalidated. If an update trigger with a column list is created, packages with update usage on the target table are only invalidated if the package also has an update usage on at least one column in the column- name list of the CREATE TRIGGER statement. If an insert trigger is created, packages that have an insert usage on the target table are invalidated. If a delete trigger is created, packages that have a delete usage on the target table are invalidated. There is a lot of functionality that can be used within a trigger. For example, a CASE expression can be used in a trigger, but it needs to be nested inside a VALUES statement, as shown here: BEGIN ATOMIC VALUES CASE WHEN condition THEN something WHEN other condition THEN something else END END; The best method of understanding the usage of triggers is to see some in action. The DB2CERT database contains many relationships that can be maintained using triggers. After TriggerIn the following example, a trigger is defined to set the value of the PASS_FAIL column for each of the tests taken by a candidate. (Note that we add this column for this scenario.) The trigger has been given the name PassFail (no relationship with the column called PASS_FAIL). Once the trigger has been created, it is active. The PassFail trigger is an AFTER, INSERT, and FOR EACH ROW trigger. Every time there is a row inserted into the test_taken table, this trigger will fire. The trigger body section will perform an UPDATE statement to set the value of the PASS_FAIL column for the newly inserted row. The column is populated with either the value P (representing a passing grade) or the value F (representing a failing grade). NOTE
CREATE TRIGGER PassFail AFTER INSERT ON db2cert.test_taken REFERENCING NEW AS n FOR EACH ROW MODE DB2SQL UPDATE db2cert.test_taken SET PASS_FAIL = CASE WHEN n.score >= (SELECT cut_score FROM db2cert.test WHERE number = n.number) THEN'P' WHEN n.score < (SELECT cut_score FROM db2cert.test WHERE number = n.number) THEN'F' END WHERE n.cid = cid AND n.tcid = tcid AND n.number = number AND n.date_taken = date_taken Before TriggerA before trigger will be activated before the trigger operation has completed. The triggering operation can be on an INSERT, UPDATE, or DELETE statement. This type of trigger is very useful for three purposes:
There are three before trigger examples shown below that are used in the DB2 Certification application. All three of these triggers have been implemented to avoid seat conflicts for test candidates. The triggers will fire during an insert of each new candidate for a test. ** Example 1 ** CREATE TRIGGER pre9 NO CASCADE BEFORE INSERT ON db2cert.test_taken REFERENCING NEW AS n FOR EACH ROW MODE DB2SQL WHEN (n.start_time <'09:00:00') SIGNAL SQLSTATE 70003' ('Cannot assign seat before 09:00:00!') ** Example 2 ** CREATE TRIGGER aft5 NO CASCADE BEFORE INSERT ON db2cert.test_taken REFERENCING NEW AS n FOR EACH ROW MODE DB2SQL WHEN (n.start_time + (SELECT SMALLINT(length) FROM db2cert.test WHERE number = n.number) MINUTES >'17:00:00') SIGNAL SQLSTATE'70004' ('Cannot assign seat after 17:00:00!') ** Example 3 ** CREATE TRIGGER start NO CASCADE BEFORE INSERT ON db2cert.test_taken REFERENCING NEW AS n FOR EACH ROW MODE DB2SQL WHEN (EXISTS (SELECT cid FROM db2cert.test_taken WHERE seat_no = n.seat_no AND tcid = n.tcid AND date_taken = n.date_taken AND n.start_time BETWEEN start_time AND finish_time)) SIGNAL SQLSTATE '70001' ('Start Time Conflict!') If the conditions are encountered, an SQL error will be flagged using the SQL function called SIGNAL. A different SQLSTATE value will be provided when the triggered conditions are encountered . The pre9 trigger, shown above, is used to ensure that a test candidate is not scheduled to take a test before 9:00 a.m. The aft5 trigger is used to ensure that a test candidate is not scheduled to take a test after 5:00 p.m. The start trigger is used to avoid conflicts during a testing day. Row and Statement TriggersIn order to understand the concept of trigger granularity, it is necessary to understand the rows affected by the triggering operations. The set of affected rows contains all rows that are deleted, inserted, or updated by the triggering operations. Row TriggersThe keyword FOR EACH ROW is used to activate the trigger as many times as the number of rows in the set of affected rows. The previous example shows a row trigger. Statement TriggersThey keyword FOR EACH STATEMENT is used to activate the trigger once for the triggering operation. Transition Variables and TablesWe can use transition variables and tables to see before and after images of data effected by trigger executiion. Transition VariablesTransition variables allow row triggers to access columns of affected row data in order to see the row data as it existed before the triggering operation and see the row data as it existed after the triggering operation. These variables are implemented by a REFERENCING clause in the definition. REFERENCING OLD AS OLD_ACCOUNTS NEW AS NEW_ACCOUNTS The following example uses transition variables to prevent an update from occurring: CREATE TRIGGER TR1 NO CASCADE BEFORE UPDATE ON EMP REFERENCING NEW AS T1 FOR EACH ROW MODE DB2SQL WHEN (EXISTS (SELECT 1 FROM DEPT B, EMP C WHERE B.DEPTNO=T1.WORKDEPT AND B.MGRNO=C.EMPNO AND C.SALARY <= T1.SALARY) SIGNAL SQLSTATE '70001' ('Salary too big!') Here, whenever an update is made to the EMP table, the new value of the salary of the employee, referenced in the before trigger transition variable T1.SALARY is checked against the salary of that employee's manager. This is done by joining the employee table to the department table, using the transition variable T1.WORKDEPT to get the department information for the employee being updated. Then the EMP table is joined using the manager's employee number in order to get the salary of the manager. Transition TablesTransition tables allow after triggers to access a set of affected rows and see how they were before the triggering operation and then see all rows after the triggering operation. Transition tables are also implemented using the REFERENCING clause in the trigger definition. REFERENCING OLD_TABLE AS OLD_ACCT_TABL NEW_TABLE AS NEW_ACCT_TABLE NOTE
Transition tables allow an SQL statement embedded in the trigger body to access the entire set of affected data in the state it was in before or after the change. In the following example, a fullselect reads the entire set of changed rows to pass qualifying data to a user defined function: CREATE TRIGGER EMPMRGR AFTER UPDATE ON EMP REFERENCING NEW TABLE AS NTABLE FOR EACH STATEMENT MODE DB2SQL BEGIN ATOMIC SELECT SALARYALERT(EMPNO, SALARY) FROM NTABLE WHERE SALARY > 150000; END; Transition tables can also be passed to stored procedures and UDFs that are invoked within the body of the trigger. The actual table is not passed as a parameter, but instead a table locator is passed, which can then be used to establish a cursor within the stored procedure or UDF. The following example demonstrates the passing of a transition table to a UDF: CREATE TRIGGER EMPMRGR AFTER UPDATE ON EMP REFERENCING NEW TABLE AS NTABLE FOR EACH STATEMENT MODE DB2SQL BEGIN ATOMIC VALUES (SALARYALERT(TABLE NTABLE)); END; The corresponding function definition would look something like this: CREATE FUNCTION SALARYALERT (TABLE LIKE EMP AS LOCATOR) RETURNS INTEGER EXTERNAL NAME SALERT PARAMETER STYLE DB2SQL LANGUAGE C; The C language program would declare a cursor against the transition table by referencing the locator variable that was passed as a parameter in place of a table reference: DECLARE C1 CURSOR FOR SELECT EMPNO, SALARY FROM TABLE(:LOC1 LIKE EMP) WHERE SALARY > 150000; Once the input locator parameter is accepted into the :LOC1 variable, the cursor can be opened and processed. Allowable CombinationsWhile there are many different combinations of triggers options available, not all are compatible. Table 15-1 shows the valid combinations for trigger options. Table 15-1. Trigger Option Combinations
Trigger PackagesWhen a trigger is created, DB2 creates a trigger package. This package is different from packages that you created for an application program (for more information on packages, refer to Chapter 6, "Binding an Application Program"). Trigger packages can be rebound locally, but you cannot bind them (this is done automatically during creation). The package can be rebound only with the REBIND TRIGGER PACKAGE command, and this will allow you to change subsets of default bind options (CURRENTDATA, EXPLAIN, FLAG, ISOLATION, RELEASE). For more information on the bind options, refer to Chapter 6. Trigger packages cannot be copied , freed, or dropped. In order to delete a trigger package, the DROP TRIGGER SQL statement must be issued. NOTE
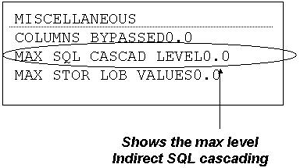
The qualifier of trigger name determines package collection. For static SQL, the authorization ID of the QUALIFIER bind option will be the qualifier, and for dynamic SQL, whatever the CURRENT SQLID is will be the qualifier. Trigger InvalidationsInvalid updates can be detected and stopped by triggers in a couple of ways. You can use the SIGNAL SQLSTATE or the RAISE_ERROR. SIGNAL SQLSTATESIGNAL SQLSTATE is a new SQL statement that is used to cause an error to be returned to the application with a specified SQLSTATE code and a specific message to stop processing. This statement can be used only as a triggered SQL statement within a trigger and can be controlled with a WHEN clause. The example below shows the use of the SIGNAL statement. WHEN NEW_ACCT.AMOUNT < (OLD_ACCT.AMOUNT) SIGNAL SQLSTATE '99001' ('Bad amount field') RAISE_ERRORRAISE_ERROR is not a statement but a built-in function that causes the statement that includes it to return an error with a specific SQLSTATE, SQLCODE 438, and a message. It does basically the same thing as the SIGNAL statement and can be used wherever an expression can be used. The RAISE_ERROR function always returns null with an undefined data type. RAISE_ERROR is most useful in CASE expressions, especially when the CASE expression is used in a stored procedure. The following example shows a CASE expression with the RAISE_ERROR function. VALUES (CASE WHEN NEW_ACCT.AMOUNT < OLD_ACCT.AMOUNT THEN RAISE_ERROR('99001', 'Bad amount field')) Forcing a RollbackIf you use the SIGNAL statement to raise an error condition, a rollback will also be performed to back out the changes made by an SQL statement as well as any changes caused by the trigger, such as cascading effects resulting from a referential relationship. SIGNAL can be used in either before or after triggers. Other statements in the program can either be committed or rolled back. Performing Actions Outside of a DatabaseTriggers can contain only SQL, but through SQL, stored procedures and UDFs can be invoked. Since stored procedures and UDFs are user-written code, almost any activity can be performed from a triggered event. The action causing the trigger may need a message sent to a special place via email. The trigger might be a before trigger written to handle complex referential integrity checks, which could involve checking if data exists in another non-DB2 storage container. Through the use of stored procedures and UDFs, the power of a trigger is almost unlimited. Performance IssuesRecursive triggers are updates applied by a trigger causing the same trigger to fire off. These can easily lead to loops and can be very complex statements. However, this may be required by some applications for related rows. You will need code to stop the trigger. Ordering of multiple triggers can be an issue because triggers on same table are activated in order created (identified in the creation timestamp). The interaction among triggers and referential constraints can also be an issue, because the order of processing can be significant on results produced. When invoking stored procedures and UDFs from triggers, there are performance and manageability concerns. Triggers can include only SQL but can call stored procedures and UDFs, which are user-written and therefore have many implications on integrity and performance. Transition tables can be passed to stored procedures and UDFs also. Trigger cascading is when a trigger could modify the triggering table or another table. Triggers can be activated at the same level or different levels, and when activated at different levels, cascading occurs. This can occur only for after triggers. Cascading can occur for UDFs, stored procedures, and triggers. Figure 15-2 shows how to find out how many levels of cascading have occurred. This information can be found in a DB2PM accounting report. Figure 15-2. Trigger Information in DB2PM Accounting Report Monitoring TriggersThere are various ways to monitor the various actions of triggers. The DB2PM statistics and accounting reports show statistics such as
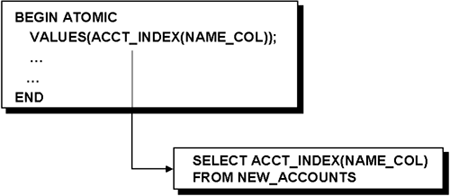
Other details can be found in the traces. For example, in IFCID 16 you can find information about the materialization of a work file in support of a transition table where TR is the transition table for triggers. Other information in IFCID 16 includes the depth level of the trigger (016), where 0 indicates that there are no triggers. You can also find the type of SQL that invoked the trigger: I = INSERT, U = INSERT into a transition table because of an update, D = INSERT into a transition table because of a delete. The type of referential integrity (RI) that caused an insert into a transition table for a trigger is also indicated with an S for SET NULL (can occur when the above is a U) or C for CASCADE DELETE (can occur when the above value is D). If a transition table needs to be scanned for a trigger, you can find this occurrence in IFCID 17: TR for transition table scan for a trigger. Catalog InformationThe SYSIBM.SYSTRIGGERS catalog table contains information about the triggers defined in your databases. To find all the triggers defined on a particular table, the characteristics of each trigger, and to determine the order in which they are executed, you can issue the following query: SELECT DISTINCT SCHEMA, NAME, TRIGTIME, TRIGEVENT, GRANULARITY, CREATEDTS FROM SYSIBM.SYSTRIGGERS WHERE TBNAME = table-name AND TBOWNER = table-owner ORDER BY CREATEDTS You can get the actual text of the trigger with the following statement: SELECT TEXT, SEQNO FROM SYSIBM.SYSTRIGGERS WHERE SCHEMA = schema_name AND NAME = trigger_name ORDER BY SEQNO Triggers Versus Table-Check ConstraintsIf a trigger and a table-check constraint can enforce the same rule, it is better to use a table-check constraint to enforce business rules. You would want to explore the use of triggers only when a constraint is not enough to enforce a business rule. Constraints and declarative RI are more useful when you have only one state to enforce in a business rule. While triggers are more powerful than table-check constraints and can be more extensive in terms of rule enforcement, constraints can be better optimized by DB2. Table-check constraints are enforced for all existing data at the time of creation, and are enforced for all statements affecting the data. A table-check constraint is defined on a populated table using the ALTER TABLE statement, and the value of the CURRENT RULES special register is DB2. Constraints offer a few other advantages over triggers, such as that they are written in a less procedural way than triggers and are better optimized. They protect data against being placed into an invalid state by any kind of statement, whereas a trigger applies only to a specific kind of statement, such as an update or delete. Triggers are more powerful than check constraints because they can enforce several rules that constraints cannot. You can use triggers to capture rules that involve different states of data, maybe where you need to know the state of the data before and after a calculation. Triggers and Declarative RITrigger operations may result from changes made to enforce DB2 enforced referential constraints. For example, if you are deleting a row from the EMPLOYEE table that causes propagated deletes to the PAYROLL table through referential constraints, the delete triggers that are defined on the PAYROLL table are subsequently executed. The delete triggers are activated as a result of the referential constraint defined on the EMPLOYEE table. This may or may not be the desired result, so we need to be aware of cascading effects when using triggers. Triggers and UDFsYou can use a UDF in a trigger, and these types of functions can help to centralize rules to ensure that they are enforced in the same manner in current and future applications. To invoke a UDF in a trigger, the VALUES clause has to be used. Figure 15-3 shows an example of how to invoke a UDF in a trigger. Figure 15-3. Invoking a UDF from a Trigger In the example below, PAGE_DBA is a user-written program, perhaps in C or Java, that formulates a message and triggers a process that sends a message to a pager. By using these kinds of UDFs in triggers, it is possible for a trigger to perform any kind of task and not just be limited to SQL. BEGIN ATOMIC VALUES(PAGE_DBA('Table spaces:' CONCAT TS.NAME, 'needs to be reorged NOW!')); END UDFs are discussed in more detail later in this chapter. |

| | |
| Team-Fly |
| Top |
EAN: 2147483647
Pages: 163