9.5 Examination and Analysis
9.5 Examination and Analysis
Recall that an examination involves preparing digital evidence to facilitate the analysis stage. The nature and extent of a digital evidence examination depends on the known circumstances of the crime and the constraints placed on the digital investigator. If a computer is the fruit or instrumentality of a crime, the digital investigators will focus on the hardware. If the crime involves contraband information, the digital investigators will look for anything that relates to that information, including the hardware containing it and used to produce it. If information on a computer is evidence and the digital investigators know what they are looking for, it might be possible to extract the evidence needed quite quickly.
In some instances, digital investigators are required to perform an onsite examination under time constraints. For instance, if the investigation is covert or the storage medium is too large to collect in its entirety, an examination may have to be performed on premises. Swift examinations are also necessary in exigent circumstances, for example, when there is a fear that another crime is about to be committed or a perpetrator is getting away. In other situations a lengthy, in-depth examination is required in a controlled environment.
In any case, the forensic examination and subsequent analysis should preserve the integrity of the digital evidence and should be repeatable and free from distortion or bias.
9.5.1 Filtering/Reduction
Before delving into the details of digital evidence analysis, a brief discussion of data reduction is warranted. With the decreasing cost of data storage and increasing volume of commercial files in operating system and application software, digital investigators can be overwhelmed easily by the sheer number of files contained on even one hard drive or backup tape. Accordingly, examiners need procedures (such as the one based on the guidelines in Chapter 24) to focus in on potentially useful data. The process of filtering out irrelevant, confidential or privileged data includes:
-
Eliminating valid system files and other known entities that have no relevance to the investigation.
-
Focusing an investigation on the most probable user-created data.
-
Managing redundant files, which is particularly useful when dealing with backup tapes.
-
Identifying discrepancies between digital evidence examination tools, such as missed files and MD5 calculation errors.
Less methodical data reduction techniques, such as searching for specific keywords or extracting only certain file types, may not only miss important clues but can still leave the examiners floundering in a sea of superfluous data. In short, careful data reduction generally enables a more efficient and thorough digital evidence examination.
9.5.2 Class/Individual Characteristics and Evaluation of Source
Two fundamental questions that need to be addressed when examining a piece of digital evidence are what is it (classification/identification) and where did it come from (evaluation of source). The process of identification involves classifying digital objects based on similar characteristics, called class characteristics.
An item is classified when it can be placed into a class of items with similar characteristics. For example, firearms are classified according to caliber and rifling characteristics and shoes are classified according to their size and pattern. (Inman and Rudin 1997)
For instance, Europol and other cooperating law enforcement agencies can compare characteristics of child pornography found in one case with a database of images seized in past investigations. Using this system, similar segments of fabric and other patterns in photographs can be found, potentially providing digital investigators with additional evidence that can help determine where the photograph was taken or help identify the offender or victim.
As another example of the usefulness of class characteristics, to determine if a file with a ".doc" extension is a Microsoft Word or WordPerfect document, it is necessary to examine the header, footer, and other class characteristics of the file. Similarly, there are different types of graphics files (e.g. JPEG, GIF, TIFF) making it possible to be specific when classifying them as shown in Table 9.3.
|
|

Such class characteristics are useful for locating fragments of digital objects on a disk. For instance, searching an entire hard drive for all occurrences of class characteristics like "JFIF" is a more thorough way to search for JPEG images than simply looking at the file system level for files with a ".jpg" file extension. In addition to finding fragments of deleted images in unallocated space, searching for class characteristics will identify JPEG files that have been renamed with a ".doc" extension to hide them from the unwary digital investigator.
There are hundreds of thousands of unique file formats, making it impossible to be familiar with every variation of every kind of digital evidence.[8] File classification tools such as the UNIX file command store class characteristics for various file types (referred to as magic numbers in UNIX) in magic files. However, when the file type is unknown, it becomes necessary to research file formats and compare unknown items with known samples. Searching the Internet for class characteristics of an unknown file is one approach to finding similar items.
If the meaning or significance of a class characteristic is not clear, it may be necessary to experiment. For instance, some applications embed data in image files such as the "Photoshop 3.0.8B" in Table 9.3. Asserting that a defendant manufactured this image because the defendant's computer has this version of Photoshop installed may not be correct. Does this class characteristic indicate that Photoshop 3.0.8B was used to create the image or simply used to modify an existing image? To answer this question, it is necessary to perform empirical experiments - creating and modifying images using Photoshop and comparing them with the image in question.
When digital evidence is found on a disk, it is not safe to assume that the data originated there. It is possible that the file was copied from another system or downloaded from the Internet. For instance, class characteristics of a JPEG file found on a hard drive are shown in Figure 9.4 using ACDSee,[9] indicating that the JPG file was created using a Kodak DX3900 digital camera. This information should prompt digital investigators to look for the associated camera as an additional source of evidence.
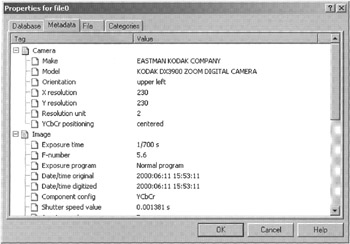
Figure 9.4: Additional class characteristics of EXIF file displayed using ACDSee. The date and time embedded in this file (15—53 on 06/11/2000) is inaccurate because the camera's clock was not set to the correct time, emphasizing the importance of documenting system time when collecting any kind of computerized device.
Using class characteristics such as those in Figure 9.4, one can assert that the evidence is consistent with a given camera. With enough class characteristics associating a piece of evidence with a specific computer, it can be argued that a preponderance of evidence indicates that this computer was involved.
To understand how similar files from different computer systems can contain different class characteristics, compare the ASCII characters in a file created on a Windows system with one created on UNIX.
On a computer running Windows 2000: C:\>echo The suspect's name is John > windowsfile C:\>od -c windowsfile 0000000 T h e s u s p e c t ' s n a 0000020 m e i s J o h n \r \n 0000035 C:\>md5sum windowsfile c52f34e4a6ef3dce4a7a4c573122a039 windowsfile On a computer running UNIX: $ echo The suspect\'s name is John > unixfile $ od -c unixfile 0000000 T h e s u s p e c t ' s n a 0000020 m e i s J o h n \n 0000033 $ md5sum unixfile 0dc789ca62a3799abca7f1199f7c6d8c unixfile
The difference between these two files is caused by the different ways that Windows and UNIX represent an End Of Line (EOL). Windows represents an end of line using a carriage return and line feed (x0D0A = \r \n), whereas UNIX just uses a line feed character (x0A = \n = ASCII 10). Macintosh computers just use a carriage return (x0D = \r = ASCII 13).
Netscape history databases provide another example of how class characteristics can vary between systems. Web browser history files maintain a list of recently visited Web sites and are useful for determining when or how often certain sites were visited, and may even contain private information such as passwords to certain sites. The first line of Netscape history files from four systems are shown in hexadecimal form in Table 9.4.
| SYSTEM (FILE NAME) | HEADER |
|---|---|
| Windows (netscape.hst) | 00 06 15 61 00 00 00 02 00 00 04 D2 00 00 10 00 |
| Linux (history.dat) | 00 06 15 61 00 00 00 02 00 00 04 02 00 00 10 00 |
| Solaris (history.dat) | 00 06 15 61 00 00 00 02 00 00 10 E1 00 00 10 00 |
| Macintosh (Netscape History) | 00 06 15 61 00 00 00 02 00 00 10 E1 00 00 10 00 |
To understand the differences between the headers in Table 9.4, we need to research the file format. Netscape history databases are in Berkeley Database (DB) version 1.85 format. Searching the Sleepycat Web site leads to details about the database format in the magic file that is used to interface with the UNIX file command.[10] The relevant segment of the Berkeley DB magic file is shown here:
0 long 0x00061561 Berkeley DB >4 long >2 1.86 >4 long <3 1.85 >0 long 0x00061561 (Hash, >4 long 2 version 2, >4 long 3 version 3, >8 long 0x000004D2 little-endian) >8 long 0x000010E1 native byte-order)
The last two lines explain the difference between the Netscape history files. Intel systems such as the one running Windows and Linux in this example are little endian whereas Macintosh and most UNIX systems are big endian. Therefore, if a Netscape history database found on a Windows system contains the 10E1 character, this is inconsistent and it is likely that the file originated from a Macintosh or UNIX computer. Interestingly, older versions of Netscape used an undocumented variation of Berkeley DB on the Windows platform that has the distinctive first line "00 06 15 61 00 00 00 02 00 00 04 B3 00 00 10 00".
When evaluating the source of a piece of digital evidence, a forensic examiner is essentially being asked to compare items to determine if they are the same as each other or if they came from the same source. The aim in this process is to compare the items, characteristic by characteristic, until the examiner is satisfied that they are sufficiently alike to conclude that they are related to one another. Ultimately, this comes down to probabilities. What is the probability of two similar items occurring independently? Archaeologists have been dealing with this question for centuries.
In studying relationships, it is necessary to base conclusions on more than a single artifact or trait. Similarities between assemblages are more significant than isolated trait similarities. For example, two dry caves a hundred miles apart may yield arrowheads of the same kind, sandals and basketry woven by the same technique, and similar simple wooden objects like drills used for making fire. Such similarity in pattern may be convincing evidence of relationship, even though the individual objects are simple in manufacture and so widely used that they would be of little significance taken individually. (Meighan 1966)
Constellations of similar characteristics are relevant in evaluating the relationship between digital evidence and its source. The more characteristics an item and potential source have in common, the more likely it is that they are related. The type of object must also be taken into account, since simple objects have a higher probability of occurring in more than one place independently whereas complex items have a lower possibility. Also, the method of manufacture of a piece of digital evidence can indicate skill level of creator (e.g. a computer program written in C++ versus in Visual Basic).
For example, in computer intrusion investigations, it is ultimately necessary to determine if items on the suspect's computer originated from the compromised system and if items on the compromised system originated from the suspect's computer. In one case, the intruder's Windows computer contained a list of the compromised UNIX machines with associated usernames and passwords (some associated sniffer logs were also found on the suspect's disk), and hacking tools that had been found on the compromised systems. Most of the individual hacking tools did not originate from any of the machines involved - they were common programs that could be downloaded from the Internet. However, the suspect had inserted his nickname into some of the programs and had used one of the compromised systems to compress the tools into a TAR file. In addition to preserving the particular directory and subdirectory structure on the compromised system, the TAR file preserved the associated username - one of the accounts that the intruder had stolen (see Table 9.5).
|
|

Additionally, the TAR file on both systems had the same MD5 value, indicating that they were identical. In isolation, each characteristic might not establish a solid relationship between the evidence and its source, but in combination the link could be seen clearly. Similarly, a Postscript file generated on a UNIX system when a document was printed may contain the full path name of the file, the username that printed the file, along with the date and time the document was printed.
It is useful to formalize the different ways that a piece of evidence can be related to a source. The relationships described in Table 9.6 are not mutually exclusive. Of course, differences will often exist between apparently similar items, whether it is a different date-time stamp of a file, slightly different data in a document, or a difference between cookie file entries from the same Web site.
| RELATIONSHIP | DESCRIPTION | EXAMPLES |
|---|---|---|
| Production | Source produced the evidence | Compressed TAR files created on a given UNIX computer. Images created on a given digital camera |
| Segment | Source is split into parts and parts of the whole are scattered | Fragments of a Word document found in unallocated space that are related to an intact version on the disk |
| Alteration | Source is an agent or process that alters or modifies the evidence | Photoshop used to change images. Programs used to delete log entries or change date-time stamps of files |
| Location | Source is a point in space | Digital photograph shows a portion of a bedroom or neighborhood. Evidence contains an IP address |
... total agreement between evidence and exemplar is not to be expected; some differences will be seen even if the objects are from the same source or the product of the same process. It is experience that guides the forensic scientist in distinguishing between a truly significant difference and a difference that is likely to have occurred as an expression of natural variation. But forensic scientists universally hold that in a comparison process, differences between evidence and exemplar should be explicable. There should be some rational basis to explain away the differences that are observed, or else this value of the match is significantly diminished. (Thornton 1997)
The concept of a significant difference is important because it can be just such a difference that distinguishes an object from all other similar objects, that is, it may be an individual characteristic. Although such characteristics are rarer than class characteristics, it is important to keep in mind that digital evidence may contain a unique characteristic that individualizes it, that is, links it to a particular source with a high degree of probability. Some individual characteristics are created at random - a digitized photograph may contain a line that is consistent with a scratch on the glass of a given flatbed scanner. Similarly, a floppy drive may create a unique pattern in the magnetic media when it writes data to the disk, enabling digital investigators to determine if digital evidence was saved using a given drive. Other individual characteristics are created purposefully for later identification (e.g. an identification number associated with a computer). These unique characteristics of a piece of digital evidence can be used to link cases, generate suspects and associate a crime with a specific computer.
For instance, files created using Office 97 for Windows and Office 98 for Macintosh contain a Global Unique Identifier (GUID) that may be associated with a specific computer. As an example, one Word 97 document created on a computer with the Ethernet address 00-10-4B-DE-FC-E9 contained the following:
_PID_GUID‰AN{2083B360-E6EF-11D2-9DC8-00104BDEFCE9}
and another document created on the same computer contained the following:
_PID_GUID‰AN{CC79EA90-E6EE-11D2-9DC8-00104BDEFCE9}
Notice the unique Ethernet address at the end of each line. To see this line the document must be viewed using a program that does not interpret the word processor commands (e.g. a simple text viewer). However, the GUID will not contain an address if the computer does not have a network interface card. Instead, a number is randomly generated when Microsoft Office is installed. Also, it is not safe to assume that a file was created on a given machine simply based on an address in the GUID. For instance, the GUID value in an Excel spreadsheet may change when the document is modified using a different computer, indicating where the file was last modified as opposed to where it was originally created.
So, additional examination is required to determine the precise relationship between a Microsoft Office file and its source (production, alteration, or inconclusive). Notably, Office documents contain other details that can be useful for evaluation of source such as printer names, directory locations, creator, and creation/modification date-time stamps.
CASE EXAMPLE
In 1999, a virus/worm called Melissa hit the Internet. Melissa traveled in a Microsoft Word document that was attached to an e-mail message. This virus/worm propagated so quickly that it overloaded many e-mail servers, and forced several large organizations to shut down their e-mail servers to prevent further damage. It was widely reported that David Smith, the individual who created the virus/worm, was tracked down with the help of a feature of Microsoft Office.
Although some individuals claimed that they tracked down the author of the Melissa virus using the network interface card in the GUID of infected documents, the New Jersey State Police actually apprehended David Smith using information obtained from AOL. The security department at AOL noticed that a stolen account was used to post the virus/worm an Internet newsgroup and that David Smith had connected to AOL through his local Internet service provider, i.e. using the "Bring your own provider" feature. However, before investigators could use this connection to locate Smith, he had realized the severity of his crime and thrown his computer in a dumpster. Although Smith confessed to the crime, his computer was never retrieved so the network interface card could not be compared with GUID information (Geraghty, M. e-mail communication).
9.5.3 Data Recovery/Salvage
In general, when a file is deleted, the data it contained actually remain on a disk for a time and can be recovered. The details of recovering and reconstructing digital evidence depends on the kind of data, its condition, the operating system being run, the type of the hardware and software, and their configurations. These details are described in later chapters but some aspects that are common to all situations are presented here.
When a deleted file is partially overwritten, part of it may be found in slack space and/or in unallocated space. It may be possible to extract and reconstitute such fragments to view them in their near original state. Such recovery is easier for file types that have more human readable components, such as Microsoft Word documents, because an individual can often infer the order and importance of each component. Finding and reconstituting file fragments can be more difficult when the header information has been overwritten but it may still be possible to repair the damage. For instance, if the header of a Word document is overwritten, the remaining fragment can be compared with other documents to determine how much of the header was lost. A suitable piece of another document's header can then be grafted onto the fragment to enable Microsoft Word to recognize and display the file. This can be more difficult with image and audio/visual files since the header contains important information such as image height and width, color information, and other information needed to display the image. Therefore, grafting a header from another file may result in odd hybrids but can give a sense of the original file as shown in Figure 9.5.

Figure 9.5: Fragments of an overwritten JPEG file partially reconstituted by grafting a new header onto the file.
There are also binary files on a computer that contain a large amount of information. For example, many operating systems and computer programs use swap files to store information temporarily while it is not being used. For instance, Windows NT uses a file named "pagefile.sys," and UNIX uses dedicated swap partitions (areas on a disk or entire disks) to store information temporarily. Hibernation files are another fruitful source of data because they contain all of the information necessary to restore the previous session. It is conceivably possible to reconstruct the full session using this data but this is difficult in practice.
Additionally, data is stored in binary form by many programs including e-mail programs, compression applications, and word processing programs. For instance, Netscape history databases mentioned earlier contain deleted entries that can be recovered. Similarly, Microsoft Outlook stores e-mail in a file that requires special processing to read and deleted e-mails may still be present in the Outlook binary file. Microsoft Office documents can contain images and other media that may be of interest in an investigation. Furthermore, binary files can contain hidden data placed there by offenders or for legitimate purposes. Some museums place digital watermarks in images of their artwork to help them determine if someone has taken or used a picture without permission.
Encryption presents a significant challenge in the recovery stage of a digital evidence examination. Encryption software like PGP is becoming more commonplace, allowing criminals to scramble incriminating evidence using very secure encoding schemes, making it unreadable. The three main approaches to getting around encryption programs like PGP are to find the encrypted data in unencrypted form, obtain the passphrase protecting the private key, or guess the passphrase. Digital evidence examiners might be able to find passphrases or unencrypted versions of data in unallocated space or swap files. Alternatively, digital investigators might be able to obtain a decryption passphrase by searching the area surrounding a system for slips of paper containing the passphrase, interviewing the suspect, or surreptitiously monitoring the suspect's computer use. The Password Recovery Toolkit and Forensic Toolkit can be combined systematically to test keywords found on a disk to determine if they are the passphrase. The Password Recovery Toolkit can also be configured to use various dictionaries and customized suspect profiles in an effort to guess the passphrase. Other techniques and tools for performing these operations are discussed in later chapters.
In addition to being technically involved, recovering encrypted data can be challenging from a legal viewpoint.
Stored data must be retrieved in such a way as to ensure that its provenance can be proved in court, and handled in such a way as to maintain the 'chain of evidence'. Decryption of stored data must therefore take place in accordance with best practice on computer forensic evidence. In general, this may require access to the decryption key rather than the plain text (otherwise doubt might be cast in court on the authenticity of the plain text) (Encryption and Law Enforcement, UK Cabinet)
In light of this issue, England enacted the Regulation Investigatory Power Act (RIPA), requiring individuals to disclose their encryption keys on demand or face a 2-year sentence. However, such penalties are insignificant to some offenders, particularly when disclosing their encryption key would result in public disgrace and a longer sentence. In one case involving child pornography and exploitation, the suspect was uncooperative and digital investigators resorted to guessing his PGP passphrase, a time-consuming process that has a low chance of success. The investigators were unable to guess the suspect's passphrase before he committed suicide (citation). In the United States, it is difficult to compel defendants to disclose encryption keys because this is viewed as self-incrimination and is protected under the Fifth Amendment. However, such refusals reflect badly on defendants and a clever attorney can sometimes use this to their advantage, either in arranging a plea bargain or convincing a jury to assume the worst.
Although it may be feasible to obtain an encryption passphrase by monitoring the suspect's computer use, this approach is invasive and can raise privacy issues. For instance, in United States v. Scarfo, the defense argued that the FBI violated wiretap statutes when they installed a key logger system on Scarfo's computer. Although full details of the monitoring system were protected under the Classified Information Procedures Act, court records indicate that the system only captured keystrokes while the computer was not connected to the Internet via the modem. This explanation satisfied the court during an in camera, ex parte hearing but most key loggers do not function in this manner and this technique is of limited effect when a computer is continuously connected to the Internet or when the suspect writes e-mail offline and only connects to the Internet to send the messages. The court addressed this concern by comparing key logging to searching a closet or file cabinet.
That the KLS (Key Logging System) certainly recorded keystrokes typed into Scarfo's keyboard other than the searched-for passphrase is of no consequence. This does not, as Scarfo argues, convert the limited search for the passphrase into a general exploratory search. During many lawful searches, police officers may not know the exact nature of the incriminating evidence sought until they stumble upon it. Just like searches for incriminating documents in a closet or file cabinet, it is true that during a search for a passphrase "some innocuous [items] will be at least cursorily perused in order to determine whether they are among those [items] to be seized." (United States v. Scarfo)
Even when data on a disk is deleted and overwritten, a "shadow" of the data might remain as shown in Figure 8.3. These shadow data are a result of the minor imprecision that naturally occurs when data are being written on a disk. The arm that writes data onto a disk has to swing to the correct place, and it is never perfectly accurate. Skiing provides a good analogy. When you ski down a snowy slope, your skis make a unique set of curving tracks. When people ski down behind you, they destroy part of your tracks when they ski over them but they leave small segments.
A similar thing happens when data is overwritten on a disk — only some parts of the data are overwritten leaving other portions untouched. A disk can be examined for shadow data in a lab with advanced equipment (e.g. scanning probe microscopes, magnetic force microscopes) and the recovered fragments can be pieced together to reconstruct parts of the original digital data.
[8]Specifications for many file formats are available at http://www.wotsit.org/
[9]http://www.acdsystems.com
[10]http://www.sleepycat.com/docs/ref/install/magic.s5.be.txt
EAN: 2147483647
Pages: 279