15.3. The document instance The actual content of an XML document goes in the document instance. It is called this because if it has a document type definition or schema definition, it is an instance of the class of documents defined by that DTD or schema. Just as a particular person is an instance of the class of "people", a particular memo is an instance of the class of "memo documents". The formal definition of "memo document" is in the memo DTD or schema definition. 15.3.1 What the tags reveal Example 15-1 is an example of a small XML document. Example 15-1. Small XML document <?xml version="1.0"?> <!DOCTYPE memo SYSTEM "memo.dtd"> <memo> <from> <name>Paul Prescod</name> <email>papresco@prescod.com</email> </from> <to> <name>Charles Goldfarb</name> <email>charles@sgmlsource.com</email> </to> <subject>Another Memo Example</subject> <body> <paragraph>Charles, I wanted to suggest that we <emphasis>not</emphasis> use the typical memo example in our book. Memos tend to be used anywhere a small, simple document type is needed, but they are just <emphasis>so</emphasis> boring! </paragraph> </body> </memo>
15.3.1.1 Tree structure Because a computer cannot understand the data of the document, it looks primarily at the tags, the markup beginning with the less-than and ending with the greater-than symbol. The tags delimit the beginning and end of various elements. The computer thinks of the elements as a sort of tree. It is the XML parser's job to separate the markup from the character data and hand both to the application. Figure 15-1 shows a graphical view of the logical structure of the document. The memo element is called either the document element or the root element. Figure 15-1. The memo XML document viewed as a tree 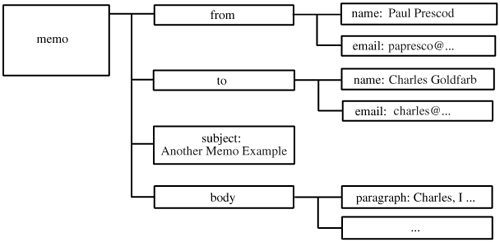
The document element (memo) represents the document as a whole. Every other element represents a component of the document. The from and to elements are meant to indicate the sender and recipient of the memo. The name elements represent people's names. Continuing in this way, the logical structure of the document is apparent. 15.3.1.2 Semantics Experts refer to an element's real-world meaning as its semantics. In a particular vocabulary, the semantics of a P element might be "paragraph" and in another it might mean "pence". If you find yourself reading or writing markup and asking: "But what does that mean?" then you are asking about semantics. Computers do not yet know anything about semantics. They do not know an HTTP protocol from a supermodel. Vocabulary designers must describe semantics to authors some other way. For instance, they could send email, write a book or make a major motion picture (well, maybe some day). What the computer does care about is how an element is supposed to look when it is formatted, or how it is to behave if it is interactive, or what to do with the data once it is extracted. These are specified in stylesheets and computer programs. 15.3.2 Elements XML elements break down into two categories. Most have content, which is to say they contain characters, elements or both, and some do not. Those that do not are called empty elements. Elements within other elements are called subelements. 15.3.2.1 Elements with content Example 15-2 is an example of an element with content. Example 15-2. Simple element <title>This is the title</title>
Elements with content begin with a start-tag and finish with an end-tag. The "stuff" between the two is the element's content. In Example 15-2, "This is the title" is the content. XML start-tags consist of the less-than (<) symbol ("left angle bracket"), the name of the element's type (sometimes termed a generic identifier or GI), and a greater-than (>) symbol ("right angle bracket"). Start-tags can also include attributes. We will look at those later in the chapter. The start-tag in Example 15-2 is <title> and its element-type name is "title". XML end-tags consist of the string "</", the same generic identifier (or GI) as in the start-tag, and a greater-than (>) symbol. The end-tag in Example 15-2 is </title>. You must always repeat the generic identifier in the end-tag. This helps you to keep track of which end-tags line up with which start-tags. If you ever forget one or the other, the parser will know immediately, and will alert you that the document is not well-formed. Note that less-than symbols in content are always interpreted as beginning a tag. If the characters following them would not constitute a tag, then the document is not well-formed. Caution  | The word "tag" is often used imprecisely, sometimes to mean "element-type name", sometimes "element type", and sometimes even "element". XML tags always start with less-than symbols and end with greater-than symbols. Nothing else is a tag. DTDs and schemas do not define tags, they define element types. (See 20.2, "Tag vs. element", on page 431 for an illustrated explanation.) |
15.3.2.2 Empty elements It is possible for an element to have no content at all. Such an element is called an empty element. One way to denote an empty element is to merely leave out the content. But as a shortcut, empty elements may also have a different syntax. Because there is no content to delimit, they may consist of a single empty-element tag. That looks like this: <MyEmptyElementTag/>. The slash at the end indicates that this is an empty-element tag, so there is no content or end-tag coming up. The slash is meant to be reminiscent of the slash in the end-tag of an element with both tags. This is just a shortcut syntax. XML parsers do not treat empty-element tags differently from elements that merely have no content between the start- and end-tag. Usually empty elements have attributes. Occasionally an empty element without attributes will be used to flag a particular location in a document. Example 15-3 is an example of an empty element with an attribute. Example 15-3. Empty element with attribute <EMPTY-ELEMENT ATTR="ATTVAL"/>
Remember what the slash at the end means! You will see it often and it is easy to miss when there are attributes like this. The slash indicates that this is an empty element so that the parser need not look for a matching end-tag. 15.3.2.3 Summary In summary, elements are either empty or have content. Elements with content are represented by a start-tag, the content, and an end-tag. Empty elements can either have a start-tag and end-tag with nothing in between, or a single empty-element tag. An element's type is always identified by the generic identifiers in its tags. The reason we distinguish element types from generic identifiers is because the term "generic identifier" refers to the syntax of the XML document – the characters that represent the actual document. The term "element type" refers to a property of a component of the actual document. 15.3.3 Attributes In addition to content, elements may have attributes. Attributes are a way of attaching characteristics or properties to elements of a document. Attributes have names, just as real-world properties do. They also have values. For instance, two possible attributes of people are their "shoe size" and "IQ" (the attribute's names), and two possible values are "12" and "112" (respectively). In a DTD or schema definition, each attribute is defined for a specific element type and is allowed to exhibit a certain type of value. Multiple element types could provide attributes with the same name and it is sometimes convenient to think of them as the "same attribute" even though they technically are not.[3] [3] Unless they are in the same namespace, a situation we discuss in Chapter 16, "Namespaces", on page 376. Attributes have semantics also. They always mean something. For example, an attribute named height might be provided for person elements (allowed occurrence), exhibit values that are numbers (allowed values), and represent the person's height in centimeters (semantics). Here is how attributes of person elements might look: Example 15-4. Elements with attributes <person height="165cm">Dale Wick</person> <person height="165cm" weight="165lb">Bill Bunn</person>
As you can see, the attribute name does not go in quotes, but the attribute value does because it is a literal string. 15.3.3.1 Literal strings The data (text other than markup) can contain almost any characters. Obviously, in the content of your document you need to use punctuation and white space characters! But sometimes you also need data characters within markup. For instance, an element might represent a hyperlink and need to have a URL attribute. Literal strings allow users to use (non-name) data characters within markup. For instance, to specify the URL in the hyperlink, we would need the slash character. Example 15-5 is an example of such an element. Example 15-5. Literal string in attribute value <REFERENCE URL="http://www.documents.com/document.xml">... </REFERENCE>
The string that defines the URL is the literal string. This one starts and ends with double quote characters. Literal strings are always surrounded by either single or double quotes. The quotes are not part of the string. For example, see Example 15-6. Example 15-6. Quotes within quotes "This is a double quoted literal." 'This is a single quoted literal.' "'tis another double quoted literal." '"And this is single quoted" said the self-referential example.'
15.3.3.2 ID and IDREF attributes Sometimes it is important to be able to give a name to a particular occurrence of an element type; that is, to a single element. For instance, to make a simple hypertext link or cross-reference from one element to another, you can name a particular section or figure. Later, you can refer to it by its name. The target element is labeled with an ID attribute. The other element refers to it with an IDREF attribute. This is shown in Example 15-7. Example 15-7. Using ID and IDREF attributes <BOOK> ... <SECTION ><TITLE>Features of XML</TITLE> ... </SECTION> ... If you want to recall why XML is so great, please see the section entitled <CROSS-REFERENCE IDREF="Why.XML.Rocks"/>. ... </BOOK>
Caution | You may see an element-type name, such as SECTION in the above example, referred to as an element name. The real element name – the name of this individual SECTION element – is the value of the element's ID attribute; in this case, Why.XML.Rocks (See 20.2, "Tag vs. element", on page 431.) |
|