[Page 552]13.4. Process Management In this section, I describe the way that the kernel shares the CPU and RAM among competing processes. The area of the kernel that shares the CPU is called the scheduler, and the area of the kernel that shares RAM is called the memory manager. This section also contains information about process-oriented system calls, including exec (), fork (), and exit (). 13.4.1. Executable Files When the source code of a program is compiled, it is stored in a special format on disk. The first few bytes of the file are known as the magic number, and are used by the kernel to identify the type of the executable file. For example, if the first two bytes of the file are the characters "#!", the kernel knows that the executable file contains shell text, and invokes a shell to execute the text. In addition to recognizing a specific magic number, Linux recognizes the following executable file formats: a.out old-style format for backward compatibility ELF Executable and Linking Format, the typical executable format EM86 allows Intel binaries to run on Alpha platforms Java executes Java class files without specifying a Java bytecode interpreter
13.4.2. The First Processes Linux runs a program by creating a process and then associating it with a named executable file. Surprisingly enough, there's no system call that allows you to say "create a new process to run program X"; instead, you must duplicate an existing process and then associate the newly created child process with the executable file "X." The first process, sched, has process ID (PID) 0, and is created by Linux during boot time. This process immediately forks (creating PID 1), and that process execs the init program. This is known as a "fork and exec." The purpose of these processes is described later in this chapter. All other processes in the system are descendants of the init process. For more information concerning the boot sequence, see Chapter 14, "System Administration." 13.4.3. Kernel Processes and User Processes Most processes execute in user mode except when they make a system call, at which point they flip temporarily into kernel mode. However, the sched daemon (PID 0) executes permanently in kernel mode due to its importance and is called a kernel process. In contrast to user processes, kernel process code is linked directly into the kernel and does not reside in a separate executable file. In addition, kernel processes are never preempted. 13.4.4. The Process Hierarchy When a process duplicates by using fork (), the original process is known as the parent of the new process, or child process. The init process, PID 1, is the process from which all user processes are descended. Parent and child processes are therefore related in a hierarchy, with the init process as the root of the hierarchy. Figure 13-22 illustrates a process hierarchy involving four processes.
[Page 553] Figure 13-22. Process hierarchy. 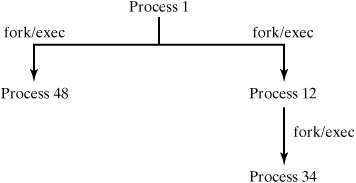
13.4.5. Process States Every process in the system can be in one of six possible states, as follows: Running, which means that the process is currently using the CPU. Running/runable, which means that the process is in the run queue and can make use of the CPU as soon as it becomes available. Waiting/sleeping, which means that the process is waiting for an event to occur and it may be interrupted. For example, if a process executes a read () system call, it sleeps until the I/O request completes. Waiting/uninterruptible, which means that the process is waiting for a event to occur, but it has disabled signals, so it cannot be interrupted. Suspended/stopped, which means that the process has been "frozen" by a signal such as SIGSTOP. It will resume only when sent a SIGCONT signal. For example, a Control-Z from the keyboard suspends all of the processes in the foreground job. Zombified, which means that the process has terminated but its parent has not accepted its exit code. A process remains in existence as a zombie process until its parent accepts its return code using the wait () system call.
13.4.6. Process Kernel Data In addition to the code and data of a running process, every process in the system has some additional associated "housekeeping" information that is maintained by the kernel for process management. This data is stored in the kernel's data region and is accessible only by the kernel; user processes may not access their process's housekeeping data. Data within a process's user area includes: a record of how the process should react to each kind of signal a record of the process's open file descriptors a record of the process's virtual memory pages
[Page 554]Most of this data is maintained in individual structures, which themselves are parts of a doubly linked list that the kernel uses to track all of a type of resource in the system. For example, a single process (or task, as it is called in the Linux kernel code) is represented by a task_struct structure, shown in Figure 13-23. Figure 13-23. A user process's task_struct. 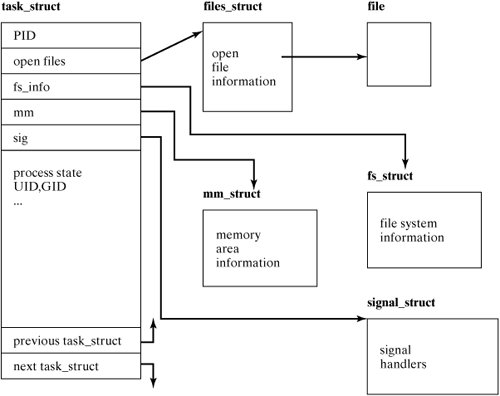
Each process or task has a kernel structure that contains information about all the files the process is currently using, or open files, as shown in Figure 13-24. Figure 13-24. Open file information for a task. (This item is displayed on page 555 in the print version) 
Whenever the open () system call succeeds and a new file is opened, a new file structure is created, a pointer is added to the files_struct of the process that opened the file, and the file structure is linked into the doubly linked list of open files on the system. Rather than constantly allocating and deallocating these structures in kernel memory, when a file structure is no longer needed, it is added to a free list and reused in the future. f_op points to a file_operations structure which contains pointers to all I/O operations that are defined for the device driver of the device containing the file. This is used when a user program executes a system call like read (), write (), or lseek ().
[Page 555]13.4.7. The Task List The kernel keeps track of all processes in the system by virtue of their being linked together into what is called the task list (this is analogous to the UNIX process table). The kernel keeps a pointer to the head of the list, the task_struct for the init process, and from there it can find all other processes in the system (Figure 13-25). Figure 13-25. The Linux task list. 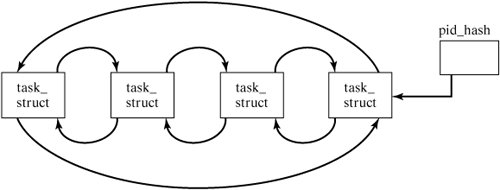
13.4.8. The Scheduler The kernel is responsible for sharing CPU time between competing processes. A section of the kernel code called the scheduler performs this duty, and maintains a special data structure called a run queue that allows it to schedule processes efficiently. The run queue is a linked list of the runable processes that are ready to use the CPU.
[Page 556] Processes are allocated CPU time in a round-robin fashion in proportion to their importance or what the Linux kernel calls "goodness." Scheduling policy differs for traditional processes and real-time processes, which Linux supports. All real-time processes have a higher priority than any regular process. The scheduler periodically walks the task list looking for processes that are ready to run to add to the run queue. Then it goes through the run queue to see which process should get CPU access next. Some of the factors the scheduler uses to determine goodness are: process type (real-time or normal) priority (can be affected by the nice utility or nice () system call) amount of time process has already used (it's "less good" if it's been running)
If the scheduler selects the currently running process, then nothing changes. If it selects a different process, then important information about the running process is saved and the new process is given access to the CPU. This is known as a context switch. The old process is put at the end of the run queue (if it is still ready to run) and will get CPU time again after other runable processes have had their turn. A process can voluntarily give up the CPU in a situation where it will wait for system resources. In this case, it sleeps and the scheduler immediately finds a new process to which to allocate the CPU. An interactive process will tend to have good response time, because while it waits for user action, it uses no CPU time, so its priority increases. |