Section 13.3. The File System
13.3. The File SystemLinux uses files for long-term storage and RAM for short-term storage. Programs, data, and text are all stored in files. Files are usually stored on hard disks, but can also be stored on other media such as tape and floppy disks. Linux files are organized by a hierarchy of labels, commonly known as a directory structure. The files referenced by these labels may be of three kinds:
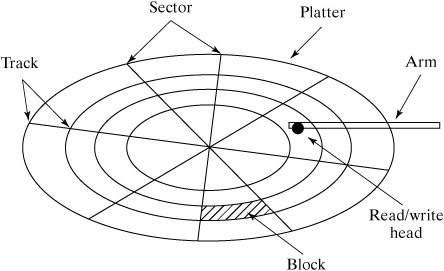
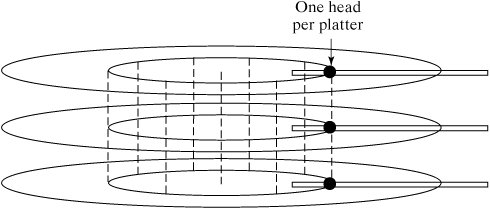
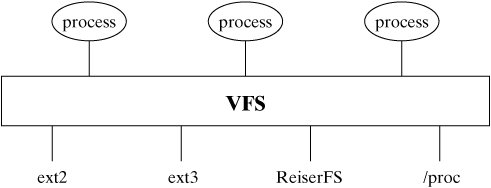
Conceptually, a Linux file is a linear sequence of bytes. The Linux kernel does not support any higher order of file structure, such as records and/or fields, as some older operating systems did. This is evident if you consider the lseek () system call, which allows you to position the file pointer only in terms of a byte offset. While most of the concepts in this section apply to any file system supported by Linux, we will specifically examine the Native Linux (ext2) file system. But first, let's examine the hardware architecture of the most common file system medium: the disk drive. 13.3.1. Disk ArchitectureFigure 13-9 is a diagram of a typical disk architecture. Figure 13-9. Disk architecture. A disk is split up in two ways: it's sliced like a pizza into areas called sectors, and further subdivided into concentric rings called tracks. The individual areas bounded by the intersection of sectors and tracks are called blocks, and form the basic unit of disk storage. A typical disk block can hold 4K bytes. A single read/write head accesses information as the disk rotates and its surface passes underneath. A special chip called a disk controller moves the read/write head in response to instructions from the disk device driver, which is a special piece of software located in the Linux kernel. There are several variations of this simple disk architecture. Many disk drives actually contain several platters, stacked one upon the other. In these systems, the collection of tracks with the same index number is called a cylinder. In most multiplatter systems, the disk arms are connected to each other so that the read/write heads all move synchronously, rather like a comb moving through hair (Figure 13-10). The read/write heads of such disk systems therefore move through cylinders of media. Figure 13-10. A multiplatter architecture. Notice that the blocks on the outside track are larger than the blocks on the inside track, due to the way that a disk is partitioned. If a disk always rotates at the same speed, the density of data on outer blocks is less than it could be, thus wasting potential storage (Figure 13-11). Figure 13-11. Disk storage techniques.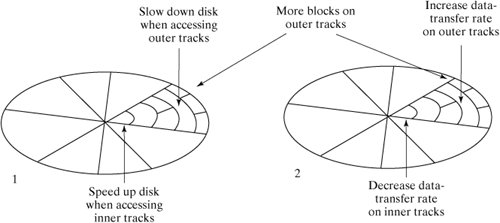 13.3.1.1. InterleavingWhen a sequence of contiguously numbered blocks is read, there's a latency delay between each block due to the overhead of the communication between the disk controller and the device driver. Logically contiguous blocks are therefore spaced apart on the surface of the disk so that, by the time the latency delay is over, the head is positioned over the correct area. The spacing between blocks due to this delay effect is called the interleave factor. Figure 13-12 illustrates two different interleave factors. Figure 13-12. Disk interleaving.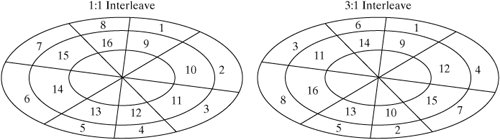 13.3.1.2. Block I/OInput and output to and from the disk is always performed in whole blocks. If you issue a read () system call to read the first byte of data from a file, the device driver issues an I/O request to the disk controller to read the first 4K block into a kernel buffer, and then copies the first byte from the buffer to your process. More information about I/O buffering is presented later in this chapter. Most disk controllers handle one block I/O request at a time. When a disk controller completes the current block I/O request, it issues a hardware interrupt back to the device driver to signal completion. At this point, the device driver usually makes the next block I/O request. Figure 13-13 illustrates the sequence of events that might occur during a 9K read (). Figure 13-13. Block I/O.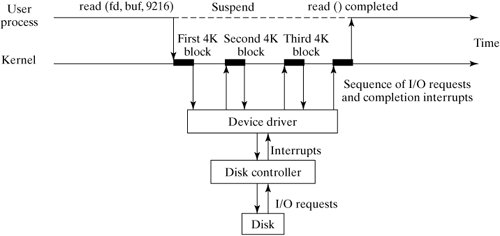 13.3.1.3. FragmentationBlock size can be specified at 1K, 2K, or 4K, when the file system is created with the mkfs utility (if not specified, mkfs will pick a size suitable to the size of the file system). Assuming a 4K block size, a single 9K file requires 3 blocks of storageone to hold the first 4K, one to hold the next 4K, and the last to hold the remaining 1K. As a file is modified, blocks are added to and removed from the file as data is added and deleted. Disk blocks are rarely contiguous on the disk device and, over time, the disk blocks making up the file tend to become scattered all over the disk (Figure 13-14). This situation is called fragmentation. Figure 13-14. A file's blocks are scattered.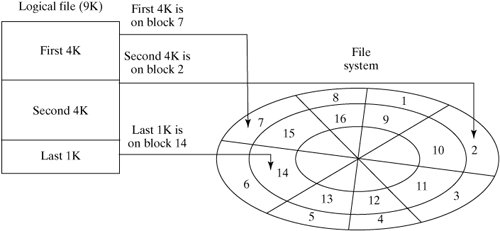 13.3.2. Virtual File SystemThe central connection between the Linux kernel and all file systems is the Virtual File System (VFS) abstraction layer. The Linux kernel knows nothing of the details of any particular file system, it simply talks to the VFS to deal with any file system. Every file system provides a standard interface that hooks into VFS. Figure 13-15 shows the relationship between a process and a file system. Figure 13-15. The VFS layer between process and file system. This abstraction not only allows many different types of real file system to be plugged in underneath and run smoothly, it also allows a file system interface to be created for data structures other than file systems. The /proc file system (discussed in Chapter 14, "System Administration") is an example of such a use and is a good example of the power of VFS. A file system interface to kernel data provides an easy-to-navigate interface into a running kernel. 13.3.3. InodesLinux uses a structure called an inode (Index Node) to store information about each file. The inode of a regular or directory file contains pointers to the locations of its disk blocks, and the inode of a special file contains information that allows the peripheral to be identified. Each inode also holds other information about the file. An inode is a fixed size structure containing pointers to disk blocks and additional indirect pointers (for large files). Every inode in a particular file system is allocated a unique inode number and every file has exactly one inode (Figure 13-16). Figure 13-16. Every file has an inode.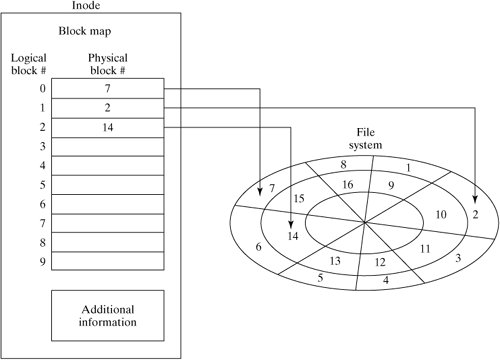 Each inode contains information about the file such as:
In other words, an inode contains most of the information that you see when you perform an "ls -l," except the filename. Only the locations of the first 12 blocks of a file are stored directly in the inode. Many Linux files are smaller than 48K in size, so in a 4K-block file system, this is sufficient for many files. An indirect accessing scheme is used for addressing larger files. In this scheme, a disk block is used to hold the locations of other data blocks. This block is called an indirect block. Its location is stored in the inode, and it is used to address the next group of blocks in the file. If this is still insufficient to hold references to all the required data blocks for a file, a double-indirect block is used. This block points to a group of indirect blocks, which in turn point to data blocks. A Linux inode contains a place to store references to one indirect, one double-indirect, and one triple-indirect block as shown in Figure 13-17. Figure 13-17. A file's blocks are scattered.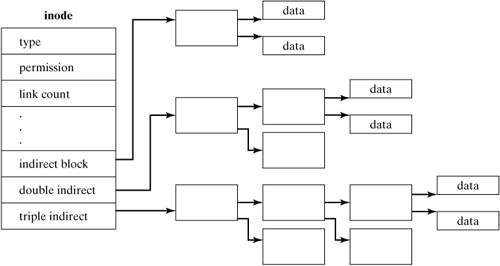 Note that, as the file gets larger, the amount of indirection required to access a particular block increases. This overhead is minimized by buffering the contents of the inode and commonly referenced indirect blocks in RAM. 13.3.4. File System LayoutThe first logical block of a disk is called the boot block, and contains some executable code that is used when Linux is first activated. See Chapter 2, "Installing Your Linux System," and Chapter 14, "System Administration," for more information. The remainder of the file system is a repeated series of block groups, each containing a group of inodes, disk blocks, and some housekeeping information about them. Each block group contains the following data:
Figure 13-18 is a simplified diagram of the layout of the ext2 file system. Figure 13-18. Simplified view of the ext2 file system layout.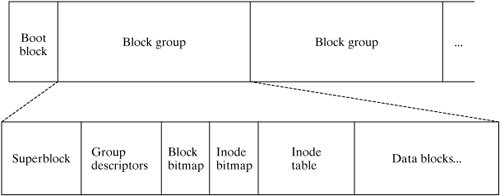 13.3.4.1. The SuperblockThe superblock contains information pertaining to the entire file system, such as:
Without the superblock, the file system could not be used. Therefore, multiple copies of the superblock are maintained throughout the file system area in case of a failure of the primary copy. A copy of the superblock is maintained at the started of each block group. 13.3.4.2. Group DescriptorsThe group descriptor is a sort of superblock for the individual block group. As in superblock, a copy of all group descriptors is stored in each block group, so this area contains a copy of all group descriptors in the file system. Information stored here includes:
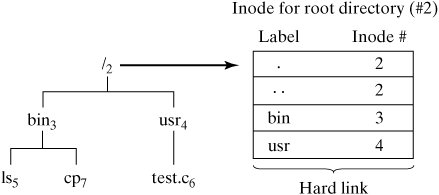
13.3.4.3. Block and Inode BitmapsThe block and inode bitmaps are each a string of bits corresponding to each block and inode, respectively, in the block group. If the bit is set to 1, then block or inode is allocated, otherwise it is available. These bitmaps are used during allocation and deallocation of block and inodes. 13.3.4.4. Inode TableThe inode table is simply an array of inode structures for each inode defined in the block group. 13.3.5. Bad BlocksA disk always contains several blocks that, for one reason or another, are not fit for use. Many disk drives map out bad blocks internally, but those that are not can be mapped out by the file system itself. The utilities that create a new file system also create a single "worst nightmare" file composed of all the bad blocks on the disk and record the locations of all these blocks in inode number 1. This prevents the blocks from being allocated to other files. When fsck runs to check the file system, bad blocks can be added to this file and thus mapped out of the file system. 13.3.6. DirectoriesInode number 2 contains the location of the block(s) containing the root directory of the file system. A directory contains a list of associations between filenames and inode numbers. When a directory is created, it is automatically allocated entries for "..", its parent directory, and ".", itself. Since a <filename, inode number> pair effectively links a name to a file, these associations are termed "hard links." Since filenames are stored in the directory blocks, they are not stored in a file's inode. In fact, it wouldn't make any sense to store the name in the inode, as a file may have more than one name. Because of this observation, it's more accurate to think of the directory hierarchy as being a hierarchy of file labels, rather than a hierarchy of files. Most file systems allow filenames up to 255 characters in length. Figure 13-19 is an illustration of the root inode corresponding to a simple root directory. The inode numbers associated with each filename are shown as subscripts. Figure 13-19. The root directory is associated with inode two. 13.3.7. Translating Pathnames into Inode NumbersSystem calls such as open () must obtain a file's inode from its pathname. They perform the translation as follows:
To illustrate this algorithm, I'll list the steps required to translate the pathname "/usr/test.c" into an inode number. Figure 13-20 contains the disk layout that I assume during the translation process. It indicates the translation path using bold lines, and the final destination using a circle. Figure 13-20. A sample directory layout.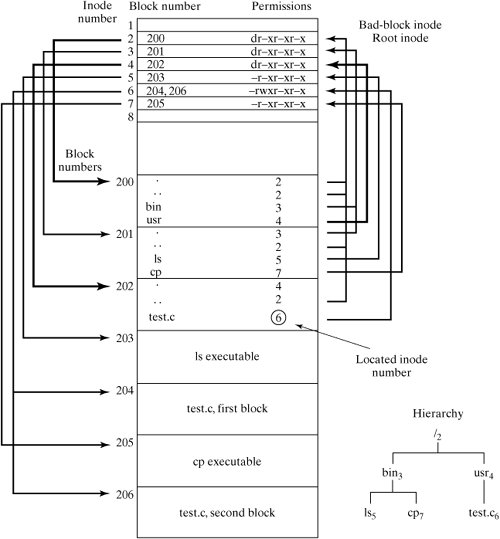 Here's the logic that the kernel uses to translate the pathname "/usr/test.c" into an inode number:
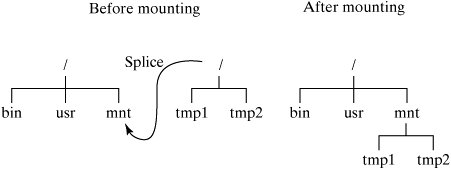
As you can see, the translation bounces between inodes and directory blocks until the pathname is fully processed. 13.3.8. Mounting File SystemsWhen Linux is booted, the directory hierarchy corresponds to the file system located on a single disk called the root device. Linux allows you to create file systems on other devices and attach them to the original directory hierarchy using a mechanism termed mounting. The mount utility allows a super-user to splice the root directory of a file system into the existing directory hierarchy. The hierarchy of a large Linux system may be spread across many devices, each containing a subtree of the total hierarchy. For example, the "/usr" subtree is commonly stored on a device other than the root device. Non-root file systems are usually mounted automatically at boot time. See Chapter 14, "System Administration," for more details. For example, assume that a file system is stored on a floppy disk in the "/dev/fd0" device. To attach it to the "/mnt" subdirectory of the main hierarchy, you'd execute the command: $ mount /dev/fd0 /mnt Figure 13-21 illustrates the effect of this command. Figure 13-21. Mounting directories. File systems may be detached from the main hierarchy by using the umount utility. The following command would detach the file system stored in "/dev/fd0": $ umount /dev/fd0 or $ umount /mnt |
EAN: 2147483647
Pages: 339