Chapter 9
-
Prepend 0 to all events of problem 3 of Chapter 8, except the last event, where 1 should be appended, and no need for EOB, e.g. first event (0, 4, 0) and the last event (1, 2, -1)
-
For x, the median of (3, 4, -1) is 3 and for y, the median of (-3, 3, 1) is 1. Hence the prediction vector is (3, 1) and MVD = (2 - 3 = -1; 1 - 1 = 0) = (-1, 0)
-
-
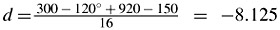
thus B1 = 150 - 8=142 and C1 = 115 + 8 = 123
-
d = -31.25, and d1 = 0, hence B and C do not change.
-
-
-
(3, 4),
-
(0, -3),
-
(1, 0.5),
-
(3, 2.6)
-
(-1, -1).
-
-
In order for a matrix to be orthonormal, multiplying each row by itself should be 1. Hence in row 1 and 3 (basis vectors 0 and 2), their values are 4, hence they should be divided by
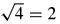 . In rows 2 and 4 their products give: 4 + 1 + 1 + 4 = 10, hence their values should be divided by
. In rows 2 and 4 their products give: 4 + 1 + 1 + 4 = 10, hence their values should be divided by 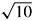 .
.Thus the forward 4 × 4 integer transform becomes
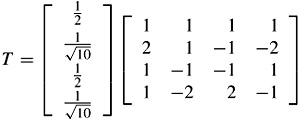
And the inverse transform is its transpose
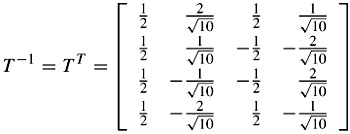
As can be tested, this inverse transform is orthornormal, e.g.:
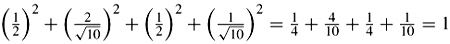
-
With the integer transform of problem 5, the two-dimensional transform coefficients will be
431
-156
91
-15
43
52
30
1
-6
-46
-26
-7
-13
28
-19
14
The reconstructed pixels with the retained coefficients are; for N = 10:
105
121
69
21
69
85
62
44
102
100
98
119
196
175
164
195
which gives an MSE error of 128.75, or PSNR of 27.03 dB. The reconstructed pixels with the retained 6 and 3 coefficients give PSNR of 22.90 and 18 dB, respectively.
With 4 × 4 DCT, these values are 26.7, 23.05 and 17.24 dB, respectively.
As we see the integer transform has the same performance as the DCT. If we see it is even better for some, this is due to the approximation of cosine elements.
-
index-0 = QP
-
index-8 = 2QP
-
index-16 = 4QP
-
index-24 = 8QP....index-40 = 32QP
-
index-48 = 64QP
-
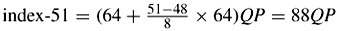
-
-
Compared with H.263, at lower indices H.263 is coarser, e.g. at index-8 the quantiser parameter for H.263 is 8QP, but for H.26L is 2QP etc.
At higher indices, the largest quantiser parameter for H.263 is 31QP, but that of H.26L is 88 QP, hence at larger indices H.26L has a coarser quantiser.
EAN: 2147483647
Pages: 148