Cache Architecture
It is very important that the cache architecture clearly defines the objectives of a cache up front. There are several important issues to consider:
-
Distributed caching Is a distributed cache needed? Is a hierarchical/tiered cache required?
-
Capacity planning What is the size of the cache?
-
Caching algorithm Which algorithm to use in order to purge a cached object: algorithm based on LRU (least recently used), frequency of usage, or LRU and frequency combined?
-
Cache population Define process for loading the cache. Is there a cache priming process like populating the cache in a servlet's init() method?
-
Cached data invalidation Define process for invalidating a cache when data changes in a data store and define process for propagating this change to other JVMs in a distributed caching scheme.
-
When an object is in memory, its corresponding image can be changed on disk, or it can be changed by another thread in memory. In this scenario, the object needs to be purged from the cache. The object can either be read back immediately into the memory or read into memory the next time it is requested. In a distributed cache, invalidation is more complicated. An object may be in several distributed JVMs, in which case, if an object in the cache is made dirty then all the caches in a distributed caching topology need to be notified. Similarly, if the object is changed on the disk then all the caches need to be notified. JMS can be used to provide this notification and synchronization between distributed caches. J2EE offers a mature network communications infrastructure and is designed from the ground up to support distributed computing, therefore it is well suited for a distributed cache. Vendors such as spiritsoft offer caching frameworks based on JCache, which allows users to implement multi-tiered caching solutions using JMS for intercache communication. SpiritCache from spiritsoft offers such services as clustering, fault-tolerance, and XA transactions.
Desirable features for a cache will include the following:
-
Distributed cache across JVMs
-
JMS-based invalidation and refresh
-
A CacheFactory to handle cache creation via specialized data-aware cache-creator classes, such as Named cache
-
Cache priming or bulk loading at a predefined time
-
Built-in statistics via ValueObject (see Figure 3-8) objects to help in invalidation and cache sizing based on the following:
-
Frequency of use (accessed how many times?)
-
Last accessed (when was it last accessed?)
-
Time bound expiration (how long in the memory?)
-
Figure 3-8 depicts important elements of a cache.
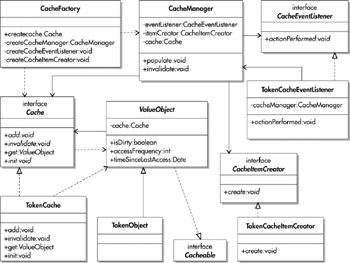
Figure 3-8: Elements of a cache
The possible interactions between different cache objects are as follows:
-
The CacheFactory is used to create a named cache such as an instance of TokenCache. The factory object creates a CacheManager object and associates it with the TokenCache.
-
The TokenCache implementation may use a HashMap object in which case we can use a key/value pair (that is, a concrete implementation of ValueObjectKey/ValueObject) for storing and retrieving objects. TokenCache is implemented as a Singleton object. Appropriate synchronization semantics should be associated with the cache.
-
The ValueObject implementation maintains a reference to the cache that contains it. This reference can be used to inform the cache when a ValueObject is invalidated or updated. The ValueObject is an abstract class providing the base implementation for certain methods. The TokenCache is populated with the ValueObject subclass (TokenObject), as shown in Figure 3-8.
-
The factory associates a CacheEventListener object (a concrete implementation of this interface could be a JMS-based listener subscribing to a JMS topic associated with the cache) with the CacheManager. This event listener responds to events such as INVALIDATE and RELOAD.
-
The factory associates a CacheItemCreator object (implemented by a concrete class TokenCacheItemCreator) with the CacheManager.
-
When the get method of TokenCache is called, and if there is a miss, the CacheManager calls the create method of TokenCacheItemCreator object. This will load the data from the data store.
-
When a TokenCache object is updated by a client, or when an object is invalidated, the CacheManager sends an invalidate notification to all the caches in a distributed caching topology. This is done by posting an INVALIDATE event for that object to the JMS topic.
-
An INVALIDATE event will invoke the event listener's actionPerformed method, which will instruct the CacheManager of the invalidation. The CacheManager will in turn call the invalidate method of the TokenCache. An invalidation results in the removal of the corresponding item from all the caches.
Cache Optimization
When designing an application-level cache, one needs to optimize cache hits. A cache hit means that the data was found in the cache and hence the request can be serviced from the cache. If there is cache miss, the client needs to be serviced from the data store. The bigger the cache size, the better the chance of a cache hit. An architect needs to optimize the application cache size such that the cache hit is at a ratio above the acceptable threshold. Since applications have only finite resources available, the cache size is limited by the amount of memory available to the application. It is advisable to build a prototype cache and simulate the cache hits. With Java, it is best to fix a cache size and not let it grow above a certain threshold. This works well with the Java memory model and garbage collection since memory is not given back to the operating system even after the garbage collector frees it. Fixing the cache size, instead of constant readjustment, will therefore prevent the operating system process from growing out of bounds.
To put a limit on the cache size implies creating a purging algorithm for keeping the cache optimally configured. The most common purging algorithms are LRU (least recently used) and access-frequency-based (popularity-based). In the LRU case, an object is purged because it was accessed the longest time ago. In the access-frequency case, an object is purged based on the number of times the object was accessed. For example an object with three accesses is purged before an object with five accesses. A more generalized algorithm is to use a combination of LRU and access-frequency. The combination can give each parameter a different weight. The weight is determined by the data access pattern of the particular application:
Weight = accessFrequency * exponent ((-decayConstant) * timeSinceLastAccess);
-
accessFrequency Number of times the object was accessed since it has been in the cache.
-
timeSinceLastAccess Time elapsed since the object has was last accessed.
-
decayConstant This is normalized to be between 0 and 1. If accessFrequency is to be given more weight, set decayConstant close to 0. If timeSinceLastAccess is to be given more weight, set decayConstant close to 1. Adjust decayConstant for getting the right value based on cache optimization needs.
EAN: 2147483647
Pages: 111