Chapter 14: Denial of Service Attacks
Denial of service (DoS) attacks are those that impede how an application performs , sometimes rendering it useless for legitimate users. Simply put, a DoS attempts to inconvenience the victim, but can also cause a lot of damage.
While sometimes only a minor inconvenience, in many cases the costs of DoS attacks are very real and can start adding up: lost revenue, lost productivity, damaged reputation, and so on. Ever heard the quote by Benjamin Franklin, Time is money ? Imagine that an attacker is able to prevent you from accessing your bank account, e-mail server, or even your personal computer connected to the Internet. Or imagine that you could use the machine, but its performance is severely degraded. Would you want to pay for a service that isn t reliable? Probably not.
In assessing the impact of DoS attacks, don t forget the cost associated with the DoS even when attackers don t take the entire service completely offline. For instance, if you have a service that runs on a server farm with a lot of customers and an attacker can consume a significant portion of the server farm s resources during peak usage, compensating for this could mean investing in additional hardware, overhead costs of product support calls when legitimate customers cannot use the service, or even losing customers.
This chapter discusses the various types of DoS attacks and how you can test for each of them.
Understanding Types of DoS Attacks
Several types of flaws lead to a denial of service. While both client and server applications are susceptible to DoS attacks, server applications often are a prime target because they can affect several people at a time and the flaw can be remotely exploited. However, quite a few security patches have been issued for client applications, too.
Another thing to consider when attempting to identify DoS attacks for server applications is to determine the privileges the user needs to have to exploit the vulnerability. As discussed in Chapter 2, Using Threat Models for Security Testing, the top priority is to look for server attacks that can be triggered by an anonymous user , but other cases are also important.
For instance, imagine that a user could bypass the quota management system and easily consume all of the disk space. Then, no one else is able to save data to the disk until either files are deleted or additional disk space is added to the server.
| Tip | Some applications have a huge exposure to DoS issues and other applications don t have much exposure at all. Attackers can create DoS issues in some surprising ways. It is worthwhile to learn about the different types of DoS issues so you can accurately assess your product. The process of threat modeling should help clarify how much risk of DoS attacks there is and whether it needs to be mitigated through security testing, performance analysis, applying proper configuration to the underlying platform (such as network stack and Web server filters and security settings), or other strategies. |
This chapter discusses two major types of DoS attacks:
-
Implementation flaws This class of DoS attack arises as a result of program logic problems, including crashes, resource leaks, inappropriate device usage, timeouts, and other related problems.
-
Resource consumption flaws Name a resource, and attackers will try to consume as much of it as they can to create a bottleneck in the application. Examples of common resources targeted by attackers include CPU, memory, disk space, and network bandwidth.
For you to find these bugs , you need to understand each type of DoS attack possible. The rest of this section discusses the two major types of DoS attacks and how you can find them while testing your application.
Finding Implementation Flaws
In applications, sometimes certain defects or bugs in a feature can lead to a DoS. But if any defect can prevent a user from performing an operation, shouldn t all bugs be considered a DoS? Not exactly. If an implementation flaw can be triggered by an attacker and can affect other users, it is considered a DoS. For example, an application that crashes if too many fonts are installed on the system would not be considered a DoS (unless an attacker could easily install fonts). However, if an application crashes when parsing the name of a font that was embedded in a specially crafted file the attacker created, the flaw is a DoS because the attacker could get a user to open that file and the file would crash the application.
| Cisco CallManager denial of service example | DoS attacks are real. Just imagine a flaw in one of your applications that could enable an attacker to crash your system remotely. One of the many security advisories revealed such a flaw. On January 18, 2006, Cisco released a patch for the Cisco CallManager to fix a DoS vulnerability that enabled an attacker to consume CPU time, interrupt the service,or even cause the server to reboot. This flaw was caused by the application not managing the TCP connections properly ”basically, an implementation flaw. To exploit this vulnerability successfully, an attacker needed to make repetitive connections to the CallManager s TCP ports. Because CallManager never closed the connections, system resources were consumed each time a connection was made, which eventually caused a DoS in the application. You can read more about this security bug at http://www.cisco.com/warp/public/707/cisco-sa-20060118-ccmdos.shtml . |
Application Crashes
When an application crashes or ends abruptly, it isn t a good thing for the user: unsaved data can be lost and data can be corrupted. Whereas application crashes frustrate most users, they can be damaging to users that depend on applications or systems that must remain running all the time. For example, if an online auction Web site becomes inaccessible because of a DoS, the site could lose a lot of revenue.
On the other hand, imagine how much fun causing these sorts of problems can be for an attacker. From an attacker s perspective, it is important to know whether an application crashes because of input provided to it. If an attacker can cause an application to crash by providing malicious input, it is considered a DoS and could result in other bugs such as buffer overflows (discussed in Chapter 8, Buffer Overflows and Stack and Heap Manipulation). Even though server applications often are more heavily targeted by attackers because crashing them affects more people, client applications can also be targeted. Although allowing DoS attacks might not be desirable, it could be acceptable for certain types of client applications if no real harm can be caused by the attack. Evaluate the potential damage an attacker can cause by perpetrating a DoS attack.
Most of the time, it is obvious when an application crashes because it might unexpectedly close or, on a system that runs the Microsoft Windows operating system, the application displays a dialog box similar to the one shown in Figure 14-1. This type of dialog box is known as the Microsoft Application Error Reporting system .
Figure 14-1: Dr. Watson dialog box for a buggy application that just crashed
Other times, an application crashes, but a dialog box does not appear. For instance, a Web server cannot display dialog boxes when a Web application crashes. Also, if an application crashes, some services, such as a Web server, might automatically restart to continue running with minimal disruption. Sometimes these crashes are written out to the Event logs, but you cannot always count on this method to detect whether the application crashes.
To ensure you catch all crashes, run the application in the debugger while testing it. Refer to Chapter 8 for information about how to debug a process. To get a clear understanding of any DoS issues do not test for flaws that can lead to DoS using a debug build of your application. The debug version has different code paths and conditions that your customers won t run into using the ship version, and debug builds are not optimized and contain extra code, making the application more sluggish .
Poorly Designed Features
DoS as a result of implementation flaws do not always crash the application. Sometimes features are designed insecurely, enabling an attacker to use them maliciously. For example, several e-mail systems allow users to set an away message for their account. If someone sends the user an e-mail while the away message is in effect, the server automatically replies by sending the away message. Can you think of any DoS problems this feature might have? What happens if the person that sent the e-mail to the user that enabled an away message also had an away message set? Depending on the e-mail system, both away messages might keep bouncing back and forth to each other, and this DoS could consume network bandwidth, CPU time, and disk space on the e-mail server.
By thinking maliciously about the way a feature works, often you can come up with scenarios on how an attacker might find a vulnerability. Suppose you are testing a rating system for a Web site that sells books. The rating systems allows users to provide a rating score to indicate how much they liked a particular book. It also allows users to provide comments about the book that can be formatted using certain HTML tags. To avoid cross-site scripting bugs, which are discussed in Chapter 10, HTML Scripting Attacks, the feature strips out all tags except <B>, <I>, <P>, and <BR>. Also, it does not allow any attributes for the tags. Can you think of ways that an attacker can abuse this feature? An attacker would probably attempt to exploit a cross-site scripting vulnerability first. But if that doesn t work, the attacker might try to find a flaw in the parser that would allow certain characters through without encoding them. The attacker might be able to force the rest of the page from rendering, which could be considered a denial of service because other users might not be able to use the ratings or, even worse , might not be able to purchase books from affected pages.
Resource Leaks
A type of implementation flaw that can also lead to a DoS attack is when an application leaks a system resource. Resource leaks occur when a developer forgets to free unneeded resources, such as memory, threads, handles, and so forth. A leak can be so small that ordinarily it might not be noticed. However, even a small leak over time can compound and consume all of the system resources, rendering the system unusable.
Error conditions are a good place to look for resource leaks because they disrupt the normal code path of the application. If testers look only for functionality issues in an application, they might not be hitting all of the error cases. Take the following C++ code example:
HRESULT DoWork(size_t nSize) { char* pszBuff = new char[nSize]; if (!pszBuff) return E_FAIL; if (DoMoreWork(pszBuff, nSize) != S_OK) { return E_FAIL; // Error, so bail out! } // Print value of pszBuff returned from DoMoreWork(). PrintOutput(pszBuff, nSize); // Free memory. if (pszBuff) { delete[] pszBuff; pszBuff = NULL; } return S_OK; } Can you see the problem? The method DoWork uses the value of nSize to determine how much memory should be allocated. It then calls DoMoreWork , and if successful, the memory is freed and the method returns S_OK . If the call to DoMoreWork fails, the method returns E_FAIL ; however, the method would return out of the function without freeing the memory, causing a memory leak.
Memory isn t the only resource that can be leaked. Handles to items such as files, registry keys, shared memory, threads, and SQL connections are other types of resources that can be leaked. On June 7, 2001, Microsoft released a security bulletin for vulnerabilities that affected the Microsoft Windows 2000 Telnet service ( http://www.microsoft.com/technet/security/bulletin/MS01-031.mspx ). One of the vulnerabilities was a DoS caused by a handle leak. When a session was terminated , the leak enabled an attacker to deplete the supply of handles on the server to the point when the service would stop performing.
To find these types of leaks, you need to watch the system resources your application uses and be sure to test your application with invalid as well as valid data to help exercise error conditions. You can use various applications to monitor resource leaks, such as Windows Task Manager or Process Explorer by Sysinternals to help detect resource leaks by looking at the memory and handles used by the process you are testing. Also, Performance Monitor is another tool that gives a nice graph of resources you want to monitor for leaks.
To start Performance Monitor, click the Start button, click Run, type perfmon in the Open text box, and then click OK to open a window similar to the following:
When you first start Performance Monitor, it automatically begins monitoring certain performance counters for the system. To find leaks in your application, add performance counters for your process to monitor the Handle Count and the Working Set. Click the plus sign (+) on the toolbar to open the following dialog box in which you can add the counters:
When monitoring the application, look for operations that cause a spike in the graph. If the spike returns to the previous level, there probably isn t a leak. However, if the counters remain at the new higher level, this is an indication that the application might have a leak. Keep repeating the same action numerous times to determine whether the counters continue to grow. If they do, there is a good chance you have a resource leak.
| Note | Sometimes performing certain functions for the first time in an application that has just started has a higher cost than performing the same actions after the application has been running for a while. It is a good idea to perform a function a few times prior to monitoring the application to ensure you aren t hitting the initial overhead. |
As shown in Figure 14-2, the handle count and memory usage continued to climb as the same operation was run numerous times. Then the counters remained elevated, even though the resources weren t needed any more. If an attacker could cause this type of spike in resource usage by sending a request to the server, just think of the damage that could be done when the server runs out of usable memory.
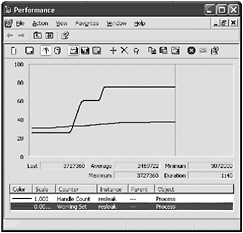
Figure 14-2: A graph in Performance Monitor that indicates a leak in a sample application
DOS Device Names Handling
Chapter 12, Canonicalization Issues, discusses how DOS device names can be used when specifying a file. Allowing a user to specify device names when handling files can lead to a denial of service attack. For example, imagine that your application creates a file based on a name that was provided by a user. If the user specifies a name that happens to correspond to a device name, such as COM1, the application would try talking with the communication port instead of the file.
Developers might attempt to prevent users from specifying device names by filtering on certain hard-coded strings. Chapter 12 explains potential ways attackers might be able to circumvent such checks; in addition, there are other problems that arise when using that mechanism. For instance, what happens when a new device name is introduced to the system? If the application is using a predefined list of strings, it won t be able to handle new devices. Instead, an application could use the QueryDosDevice API to determine what devices are on the system.
Connection Timeouts
In the past, you have probably tried connecting to a server that no longer existed or that was unavailable at the time. Depending on the application, it can take a couple of minutes before the connection to the server times out. In most client applications, if you notice the connection is taking an unusually long amount of time, the action could be canceled .
Now imagine that the server tries to connect to another machine, and the user is able to specify the name of the remote machine. Depending on how the server handles timeouts for a connection attempt, it might be possible for an attacker to send multiple requests to get the server to attempt to connect to a remote machine that does not exist. The requests use up the number of outbound connections the server can make, potentially resulting in a DoS.
An example of this type of flaw is when a server verifies digital signatures. If a client crafts a signature with a bunch of URLs for certificate revocation lists (CRLs), an application might try resolving the links prior to first verifying the certificate chain is valid (which is the proper way). If the URLs are bogus, a malicious user might be able to make the server unresponsive for a period of time while it tries to connect to the bogus CRL URLs.
Finding Resource Consumption Flaws
The preceding section discusses how an application can accidentally leak resources by forgetting to release the resources it consumes once they are not needed. Even if all the resource leaks are fixed, other potential problems with resource consumption could lead to DoS vulnerabilities.
Applications have a finite amount of resources available, such as CPU time, memory, storage space, and network bandwidth. One technique an attacker might use to cause a DoS is to get the application to use up all of the available resources, thus rendering the application useless. For instance, it is obvious that a machine has only a certain amount of free disk space. When an attacker makes a request to a server application, the data might get logged to disk ”which consumes free space. In this example, the attacker would have to send many requests to fill up the disk, so it isn t a feasible attack. But, if the attacker is able to trick the application into logging more data than it should, the attacker might be able to consume the free disk space even faster.
This section discusses DoS attacks that result from consumption of the following resources:
-
CPU time
-
Memory
-
Disk space
-
Bandwidth
CPU Consumption
If the CPU is used to process data, an attacker can cause a DoS. When the CPU is performing at 100 percent while executing an operation, the system can become unusable. Obviously, if the attacker can run arbitrary code on the machine, the attacker can consume the CPU by writing an application that executes an endless loop that performs expensive operations.
Imagine that an attacker could easily consume the CPU time of a remote machine by providing data to an application that causes it to perform certain operations. The objective in causing a CPU consumption DoS is to perform an action that is considered low cost for an attacker but that ties up the CPU on the victim s machine for a long or indefinite amount of time.
A full discussion of how to analyze CPU performance, including methodologies for data collection and application profiling, ensuring comparable CPU profiles, and statistically accounting for other factors, is beyond the scope of this book. However, you can use some straightforward techniques, discussed in the following subsections, to get started.
| Note | A full discussion of how to analyze CPU performance is beyond the scope of this book. However, you can use the techniques discussed in the following subsections to get started. |
Analyzing Algorithm Costs Many times, DoS attacks are caused by CPU consumption as a result of using inefficient algorithms with poor scalability. As a tester, often you can look through the code to analyze the costs of an algorithm, but sometimes doing so is not feasible. Instead, you can look for where your application is processing data from an end user and make an educated guess as to whether the algorithm is constant, linear, exponential, and so forth. To do this, you need to keep track of how long it takes to perform each iteration of the algorithm. Then, increase the data by a fixed factor and repeat the same operation. Keep steadily increasing the data until the cost of the algorithm is obvious or the data you are providing reaches the limit that your application can accept or that an attacker could provide.
Let s look at an example Web application that takes input from the user using data provided in an HTTP POST to specify the name of a file to create. The application removes trailing periods from the filename to prevent a certain canonicalization issue, as discussed in Chapter 12, and then will return the contents of the file to the user. To sanitize the filename, the application might have the following C# code that removes trailing periods from the name of the file the user provided as input:
string RemoveTrailingPeriod(string filename) { while (filename.EndsWith(".")) { filename = filename.Remove(filename.Length 1, 1); } return filename; } Even if you did not have access to the code, you would be able to detect the algorithm problem by using the following steps:
-
Perform the operation with a reasonable amount of data, such as a filename and just one trailing period, and then measure the amount of time it takes for the operation to complete.
-
Record the elapsed time.
-
Keep repeating the steps 1 and 2, but increase the number of trailing periods by a prefixed factor each time. Do this until you notice that the operation takes an extremely long amount of time to complete, or until the factors of 10 aren t making a noticeable difference anymore. Generally , you should notice either result fairly quickly with a bad algorithm.
-
Compare the elapsed time to see if the time is constant, linear, n -squared, exponential, and so forth.
Using the preceding steps with the sample code for RemoveTrailingPeriod on a machine that has a hyperthreaded 2.8-GHz Pentium 4 reveals results like those shown in Table 14-1.
| Number of trailing periods | Time to execute (in ms) |
|---|---|
| 1 |
|
| 10 |
|
| 100 |
|
| 1,000 | 13 |
| 10,000 | 225 |
| 20,000 | 905 |
| 30,000 | 2,094 |
| 40,000 | 3,979 |
| 50,000 | 6,470 |
| 60,000 | 10,102 |
| 70,000 | 14,633 |
| 80,000 | 20,104 |
| 90,000 | 25,348 |
| 100,000 | 31,911 |
As shown in Table 14-1, if you stopped testing at 100 or even 1,000 periods, you might not have noticed there is a problem in the algorithm. But if the code is called using input that has more periods, the amount of time to remove duplicate periods greatly increases . A scatter plot of the preceding data is shown in Figure 14-3.
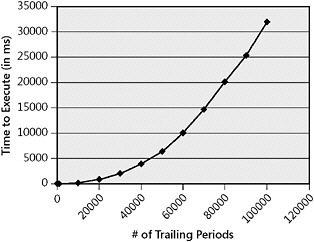
Figure 14-3: Scatter plot of the data from Table 14-1
The chart in Figure 14-3 indicates that the algorithm probably isn t the most optimal, and if an attacker continued to provide a filename with a lot of trailing periods, the CPU usage would be consumed for an unnecessary amount of time. A better algorithm for the C# example is as follows :
string RemoveTrailingPeriod(string filename) { return filename.TrimEnd(new char[] { '.' }); } Running the same tests result in the time of 0 ms for removing even 100,000 trailing periods ”a huge improvement over the previous algorithm.
Some encryption and decryption routines also can be expensive to execute and provide an area for DoS testing. Because the encryption and decryption algorithms generally consume a lot of CPU cycles by nature, they should be identified and tested . For example, a Web application might accept a user s HTTP POST data, which then will be encrypted by the server and returned to the user. If the input was not limited, an unordinary large HTTP POST could be sent to the server, which would then consume the server s CPU while encrypting the data. It might only take a couple of these types of malicious requests to be made until the server s performance degrades to an unusable state. Testers should identify any areas where data is encrypted or decrypted, and attempt large input, invalid input, and sending requests in repeated loops to see how the application handles the requests.
Understanding Recursive Calls A recursive call is when a method calls upon itself to perform an operation. Perhaps you remember computing a sequence of Fibonacci numbers , which is defined recursively as F n = F n-1 + F n-2 . However, if you write a program to compute a Fibonacci number using recursion, you find that it is an exponential algorithm.
Sometimes it is suitable for a function to call upon itself. For instance, imagine you are iterating through all of the folders and their subfolders on a system. If you do not know in advance how many folders and subfolders there are, it is more difficult to solve this problem using an iterative method. Instead, it might make more sense to use recursion to solve the problem, as shown in the following C# sample:
void PrintDirectories(string startingPath) { // Note: No exceptions are being handled for GetDirectories(). string[] dirs = Directory.GetDirectories(startingPath); // For each directory in "startingPath" call PrintDirectories(). foreach (string dir in dirs) { Console.WriteLine(dir); PrintDirectories(dir); } } The main concern with recursive calls is that, by definition, it is possible for an application to enter an endless loop. You should carefully review any code that is recursive, and it is also important to look for features in the application where it might be possible to have circular references.
For example, if a spreadsheet application allows a cell to contain a formula that uses a value from another cell, and that cell gets its value from yet another cell , it might be possible to create a situation in which A1 = B1 and B1 = A1. See the problem? If the application does not detect the circular reference, it enters an endless loop. Even if the application does not get into an endless loop with recursive calls, it might be possible to cause the application to run out of stack space. Testing the application while it is attached to a debugger can help you determine whether it runs out of stack space.
Memory Consumption
Next to CPU consumption, it is vital that a system have enough memory to complete operations successfully. Almost every computing device has some sort of memory it uses to store values when performing calculations. If you starve the machine of available memory, it can t perform operations. On some operating systems, when you consume the machine s physical memory, it has the ability to start paging the memory to disk. This means that the data is swapped between the system memory and hard disk, which is a time-consuming process. Once an attacker can consume the system memory, the machine could stop responding, causing applications to start failing.
When testing your application, monitor how much memory is consumed on different operations. Make observations on how the application behaves and think about what the application might be doing. For instance, if an application creates an instance of an object (which consumes memory) for each XML node it encounters, regardless of whether the node is valid, see what happens if you create lots of nodes. Does the application consume the system memory while it tries to process the file because of all of the objects it is creating for each node? If so, this could result in a DoS attack.
Also, look for places where length values are specified. For example, in an HTTP request, the Content-length value is supposed to specify the amount of data that is contained in the HTTP request s body. If the server allocates the space immediately without any verification, an attacker might be able to get the server to allocate a lot of memory without actually sending that much data to the server. When you are testing, the packet fields, header values, or other values that indicate the data length or size are interesting places in which to see whether you can get the application to allocate more memory than it should.
Disk Space Consumption
Even though the price of disk space has dropped considerably and the amount of space available on a hard disk continues to increase, allowing an attacker to consume all the system disk space can be considered a DoS. Sometimes a system can tolerate what might be considered a DoS. You have to decide whether what is written to disk is needed and whether it is acceptable for an attacker to cause the data to be written to the system.
Disk Quota To prevent a user from consuming all of the disk space on a machine, the system or application could use a disk quota system for mitigation. For instance, the Windows operating system has a built-in disk quota management service that can be used to restrict the amount of disk space a user consumes. If your application implements a quota system, consider the following few questions to make sure that the quota system does not lead to a DoS attack:
-
Does the quota system count all data that a user creates? Don t forget that files can have alternate data streams (discussed in Chapter 12, Canonicalization Issues), which consume disk space.
-
Can you bypass the quota system by making another application or account that isn t restricted by a quota write data on behalf of the restricted account?
-
Can you create orphan data that cannot be easily deleted? An attacker might use this flaw to consume a user s quota with data that the user can t clean up.
Logging Errors Generally, attackers try to make sure their tracks are covered when they are attempting to break into a system. Ideally, they want to target a system that does not have any audit trail, but because that is unlikely , they might use other tricks to try to hide their attacks from a system administrator. For example, they could flood the server with legitimate-looking traffic to fill the capacity of the logs. They can even use spoofing techniques (covered in Chapter 6, Spoofing) to make it hard for administrators to figure out where the attack is coming from and how it can be prevented. Logs need to include enough information so that administrators can filter out malicious attacker behavior, but cannot include too much data so that it becomes easy for an attacker to fill the capacity of the log files. Because it is difficult to determine the right balance between how much data to log out and how much to store, these settings should be configurable so the system administrator can make this choice.
Sometimes log files have the ability to roll, either by size or by date, meaning the old contents are purged from the log when the log reaches a certain size or passes a certain date. This behavior can also pose a security risk. Consider a log file that automatically rolls the week s log file at 2 A.M. every Sunday morning. If the system is attacked right before the log is rolled, say, at 1:45 A.M. on Sunday, the attacks might go undiscovered because the log is rolled before someone has a chance to notice the problem.
Decompression Bombs A lot of file formats use compression to optimize the space used by a file. Depending on the compression scheme, it is possible to create a small file that can result in a huge amount of uncompressed data, called a decompression bomb. For example, if you create a text file filled with 50 million zeros (or roughly a 50-MB file), it can easily be compressed to a size just under a couple of kilobytes. Now, imagine what might happen if an application accepts from a user a compressed file that is decompressed automatically. It would be easy to send the application a small payload that ends up expanding into a huge file that consumes the available disk space.
HTTP requests can be GZipped or compressed, which is another way attackers can potentially create a decompression bomb when a request is expanded on the server. This type of attack can even result in consuming all of the system s memory if the HTTP request is decompressed in RAM instead of straight to disk.
If your application uses compression, be sure that it checks the validity of the user before it decompresses data from the user. Also, it might be possible to have an application check what the size of the decompressed data would be before decompressing it. If so, the application should make sure the size of the decompressed data is reasonable. Of course, if an attacker could create a file that spoofs the actual size of the decompressed data, doing this type of check prior to decompression won t help.
Bandwidth Consumption
Applications that communicate over a network must take into account the network bandwidth they consume and produce. Some service providers claim they offer unlimited bandwidth, but there is no such thing. At some point, bandwidth has a limit. When that limit is reached, an application s network communication starts to degrade or is potentially lost ”causing a DoS. Depending on the application, two potential bandwidth limits that might affect the application are quota and throughput.
Bandwidth quota , although not as common as bandwidth throughput, essentially is a limit placed on how much data an application can send or receive. Most often, bandwidth quotas are used by Web hosting companies. If an application reaches its quota, transmitting network data might be prevented, rendering the application unusable. Or the service provider might charge additional fees if the application exceeds the quota limit. Imagine that a bandwidth quota is placed on an application that allows users to upload files. If the application accepts a file first before ensuring the user has permissions to upload the file, a malicious user can easily consume the allowed bandwidth by uploading huge files that will eventually be rejected.
Bandwidth throughput is the amount of network data that can be transmitted at a particular time. For instance, a cable modem might have a throughput limit of 6.0 Mbps download and 768 Kbps upload. This limit affects how fast data can be sent and received over the network connection, and affects all of the connections that use that network. So, in theory, a machine that has a cable modem with the bandwidth throughput limits previously mentioned can upload data using a single connection at 768 Kbps. If two uploads occur, the throughput limit remains the same, but the bandwidth is shared ”resulting in a 384-Kbps limit per upload. For each simultaneous upload, the throughput is shared among all the connections and the slower the data is transmitted. Eventually, when the throughput is consumed by too many connections, the service is unable to transmit data or connections start to time out.
Finding Solutions for a Hard Problem
As discussed in Chapter 3, Finding Entry Points, most applications process several pieces of data that come from various sources, including keyboard input, files, and network connections. With all the data an application must process, it can be difficult to differentiate between valid and potentially malicious data. The more data an application processes, the greater the chance of a DoS attack. You need to make sure that applications that process data do so in a robust fashion.
Even if an application has a solid design, you might not be able to protect against other types of DoS attacks that can occur at the application layer. For instance, distributed denial of service (DDoS) attacks use multiple clients to send an overwhelming number of legitimately formed requests to a victim. Because the attack uses multiple clients , it is hard to block all of the requests by filtering out the IP addresses of the originating requests. Also, it can be difficult to distinguish between requests that come from legitimate users and those that come from malicious users. DDoS attacks have been responsible for attacks on large Web sites, such as Amazon.com, Buy.com, and eBay.com ( http://www.networkworld.com/news/2000/0209attack.html ).
If an attacker has thousands of machines aimed at causing a denial of service on a single server, there isn t much an application can do to protect against this threat. However, if the attacker can achieve the same attack by using a reasonable amount of resources (smaller number of computers to initiate the attack, less bandwidth, etc.), the more likely the design of the application can protect against a DoS.
| More Info | Steve Gibson from Gibson Research Corporation (GRC), the target of DDoS attacks, used the attacks themselves to research some DoS exploitation techniques, especially in the realm of DDoS attacks. His story, available at http://www.grc.com/dos/grcdos.htm , underscores the fact that DDoS attackers strike without warning and have significant resources available for pulling off these attacks. Steve s suggestions about altering the operating system socket behavior to help mitigate DDoS attacks ignited controversy, with some claiming the effect was to hamper efforts of legitimate administrators and security testers while failing to adequately block real attacks. |
EAN: 2147483647
Pages: 156
- ERP Systems Impact on Organizations
- ERP System Acquisition: A Process Model and Results From an Austrian Survey
- The Effects of an Enterprise Resource Planning System (ERP) Implementation on Job Characteristics – A Study using the Hackman and Oldham Job Characteristics Model
- Healthcare Information: From Administrative to Practice Databases
- A Hybrid Clustering Technique to Improve Patient Data Quality