Audio Retrieval Systems
There are many audio retrieval systems available in either research laboratories or commercial vendors. Most of them utilize various audio processing algorithms to enhance the retrieving performance. Here, we briefly introduce three representative audio retrieval systems to show the state of the art in this area.
1.15 BBN Rough 'n' Ready System [22]
BBN has conducted a long term research on speech and language processing technologies, and developed an audio indexing system called Rough 'n' Ready system, which provides a rough transcription of the speech that is ready for browsing. The Rough 'n' Ready system focuses entirely on the linguistic content contained in the audio signal. Overall, the system is composed of three subsystems: the indexer, the server, and the browser. The indexer subsystem takes audio waveform as input and generates a compact structural summarization encoded in XML format. The server subsystem collects and manages the archive, as well as interacts with the browser. The browser handles the user interaction. Its main purpose is to send user queries to the server and present the results in a meaningful way.
Indexer subsystem is the technical core of the entire system, and it is built based on a series of spoken language processing technologies, including speech recognition, speaker recognition, name spotting, topic classification, and story segmentation. ASR module is realized by BBN Byblos, a large vocabulary speaker independent speech recognition system. Byblos employs continuous density hidden Markov models as acoustic models, and n-gram as language models. With multipass search strategy, unsupervised adaptation, and speedup algorithms, including fast Gaussian computation, grammar spreading, and N-Best tree rescoring, Byblos achieves an error rate of 21.4% on DARPA broadcast news test data with a sixty thousand word vocabulary at 3 times real-time performed on a 450M PII processor. Speaker recognition module recognizes a sequence of speakers in speech. It consists of three components: speaker segmentation, speaker clustering, and speaker identification. Name spotting uses IdentifFinder, a hidden Markov model-based name extraction system, to extract important terms from the speech and collect them into a database. OnTopic, a probabilistic HMM-based topic classification module, produces a rank-ordered list of all possible topics with corresponding scores for a given document. Story segmentation detects story boundaries such that each segment covers a coherent set of topics. All these structural features are used to construct highly selective search queries for retrieving specific content from large audio archives.
The technologies developed in Rough 'n' Ready system has reached the stage that commercialization is possible in very near future. There is no doubt that such an advanced audio indexing system will benefit wide ranges of customers in audio browsing and querying.
1.16 HP Speechbot System [35]
SpeechBot is claimed to be the first Internet search site for spoken audio on the web. It is built by Compaq research laboratory, which now belongs to Hewlett-Packard. Similar to AltaVista or Google, Speechbot system is a public search site that indexes transcribed audio documents by automatic speech recognition technology, and provides indexing and search functions based on audio content. The system does not serve audio content, but provide links to the relevant segments of the original documents. Currently the system is capable of indexing more than 100 hours of audio data every day, which includes popular talk radio, technical and financial news shows, and video conference recordings. Most of these audio data have no transcript, and when transcript does exist, it will be used to improve the indexing process. Although current recognition error rates are high, yet the system provides acceptable retrieval accuracy, such that the user can effectively find the interesting pieces of audio content easily.
SpeechBot consists of five key components. The transcoder module downloads various types of audio files from public web sites, and converts them into raw file format. Relevant metadata, including title, is saved for identifying them in the database. With eight workstations, each handling four streams in real time, the overall throughput of the transcoder module is 768 hours per day. The raw audio files are segmented and passed to the speech recognizer module, where they are transcribed in parallel. The speech recognizer is built based on Gaussian mixture, triphone-based hidden Markov model technology. The vocabulary of the recognizer is 64,000 words. With different combinations of model complexity and recognition searching beam, the recognizer provides different accuracies. For 6.5kb/s RealAudio data, the word error rate is in the range of 50%. A farm of 60 processors can process about 110 hours of audio per day, assuming that the recognizer is running at an average speed of 13 times real time. The librarian module manages the entire workflow on all modules, and stores metadata and necessary information for user interface. It is built on an Oracle relational database, and contains indices of 15550 hours of audio content at the time when this chapter was written. The indexer module basically is a query engine. It provides an efficient catalogue of audio documents based on their transcriptions and metadata. The retrieved document is sorted by relevance based on term frequency inverse document frequency metric. The last module is the user interface. The Web server collects users' interactions, passes their queries to Indexer, and generates the retrieval results. The user interface also highlights matching transcripts and expands and normalizes acronyms.
With the help of Speechbot, users are exposed to a huge amount of audio content, which is searchable as easy as text document. The extension of searching capability from text to non-text media is revolutionary.
1.17 AT&T Scanmail System [9]
SCANMail (Spoken Content-based Audio Navigator Mail) is a system that employs automatic speech recognition, information retrieval, information extraction, and human computer interaction technology to permit users to browse and search their voicemail messages by content through a graphical user interface. Voicemail users receive many voice messages everyday; SCANMail lets users manage their important message in a better way. The system has several useful features: 1) Read transcriptions of messages instead of listening to them, 2) Access messages randomly through a GUI, playing and reading just what's important, 3) Extract telephone numbers automatically from messages, 4) Label messages with caller names even when caller ID is not available, and 5) Use information retrieval to search messages by content.
Figure 20.4 shows the architecture of the SCANMail system. Voicemail messages are retrieved from a messaging system, Audix, via a POP3 server. The automatic speech recognition module transcribes voice messages, and the text information is indexed by the information retrieval module. The email server sends an email with original voice message plus its transcription to the user. Key information in the transcript including phone number, name, date, and time is extracted by the information extraction module. The speaker ID module compares the audio message against a list of speaker models to propose a caller identification. Users can provide feedback on the speaker ID results such that speaker models will be refined. SCANMail system provides a friendly GUI interface, which allows users to browse and query their voice messages by content. Experiments show that SCANMail offers some increase in efficiency and a significant increase in perceived utility over regular voicemail access by phones. With a variety of random access play and search capabilities, the system makes the daily voice message access an easy and pleasant experience.
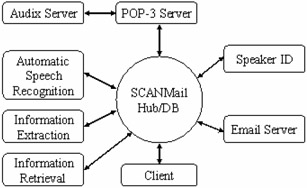
Figure 20.4: The SCANMail architecture.
EAN: 2147483647
Pages: 393