Section 6.5. Common Optimizations
6.5. Common OptimizationsA smart regex implementation has many ways to optimize how quickly it produces the results you ask of it. Optimizations usually fall into two classes:
Over the next dozen or so pages, we'll look at many of the different and ingenious optimizations that I've seen. No one language or tool has them all, or even the same mix as another language or tool, and I'm sure that there are plenty of other optimizations that I've not yet seen, but this chapter should leave you much more empowered to take advantage of whatever optimizations your tool offers. 6.5.1. No Free LunchOptimizations often result in a savings, but not always. There's a benefit only if the amount of time saved is more than the extra time spent checking to see whether the optimization is applicable in the first place. In fact, if the engine checks to see if an optimization is applicable and the answer is "no," the overall result is slower because it includes the fruitless check on top of the subsequent normal application of the regex. So, there's a balance among how much time an optimization takes, how much time it saves, and importantly, how likely it is to be invoked. Let's look at an example. The expression Yet, no engine that I know of actually uses this optimization. Why not? Well, first of all, it's not necessarily easy to decide whether it would apply to a particular regex. It's certainly possible for a regex to have But, it's not common (it's silly!) [
6.5.2. Everyone's Lunch is DifferentKeep this in mind when looking at the various kinds of optimizations that this chapter discusses. Even though I've tried to pick simple, clean names for each one, it may well be that every engine that implements it does so in a different way. A seemingly innocuous change in a regex can cause it to become substantially faster with one implementation, but substantially slower with another. 6.5.3. The Mechanics of Regex ApplicationBefore looking at how advanced systems optimize their regex performance, and how we can take advantage of those optimizations, it's important to first understand the basics of regex application. We've already covered the details about backtracking, but in this short section, we'll look at the broader picture. Here are the main steps taken in applying a regular expression to a target string:
The next few sections discuss the many ways this work can be reduced by smart implementations , and taken advantage of by smart users. 6.5.4. Pre-Application OptimizationsA good regex engine implementation can reduce the amount of work that needs to be done before the actual application of a regex, and sometimes can even decide quickly beforehand that the regex can never match, thereby avoiding the need to even apply the regex in the first place. 6.5.4.1. Compile cachingRecall the mini mail program from Chapter 2 (˜ 57). The skeleton of the main loop, which processes every line of the header, looks like: while () { if ($line =~ m/ ^\s*$ /) if ($line =~ m/ ^Subject: (.*) /) if ($line =~ m/ ^Date: (.*) /) if ($line =~ m/ ^Reply-To: (\S+) /) if ($line =~ m/ ^From: (\S+) \(([^()]*)\) /) The first thing that must be done before a regular expression can be used is that it must be inspected for errors, and compiled into an internal form. Once compiled, that internal form can be used in checking many strings, but will it? It would certainly be a waste of time to recompile each regex each time through the loop. Rather, it is much more time efficient (at the cost of some memory) to save, or cache , the internal form after it's first compiled, and then use that same internal form for each subsequent application during the loop. The extent to which this can be done depends on the type of regular-expression handling the application offers. As described starting on page 93, the three types of handling are integrated, procedural , and object-oriented . 6.5.4.2. Compile caching in the integrated approachAn integrated approach, like Perl's and awk's, allows compile caching to be done with ease. Internally, each regex is associated with a particular part of the code, and the compiled form can be associated with the code the first time it's executed, and merely referenced subsequent times. This provides for the maximum optimization of speed at the cost of the memory needed to hold all the cached expressions.
The ability to interpolate variables into the regex operand (that is, use the contents of a variable as part of the regular expression) throws somewhat of a monkey wrench into the caching plan. When variables are interpolated, as with something like m/ ^Subject: \Q $DesiredSubject \E\s*$/ , the actual regular expression may change from iteration to iteration because it depends on the value in the variable, which can change from iteration to iteration. If it changes every time, the regex must be compiled every time, so nothing can be reused. Well, the regular expression might change with each iteration, but that doesn't mean it needs to be recompiled each time. An intermediate optimization is to check the results of the interpolation (the actual value to be used as the regular expression), and recompile only if it's different from the previous time. If the value actually changes each time, there's no optimization, as the regex indeed must be recompiled each time. But, if it changes only sporadically, the regular expression need only be checked (but not compiled) most times, yielding a handsome optimization. 6.5.4.3. Compile caching in the procedural approachWith an integrated approach, regex use is associated with a particular location in a program, so the compiled version of the regex can be cached and used the next time that location in the program is executed. But, with a procedural approach, there is just a general "apply this regex" function that is called as needed. This means that there's no location in a program with which to associate the compiled form, so the next time the function is called, the regex must be compiled from scratch again. That's how it works in theory, but in practice, it's much too inefficient to abandon all attempts at caching. Rather, what's often done is that a mapping of recently used regex patterns is maintained , linking each pattern to its resulting compiled form. When the apply-this-regex function is called, it compares the pattern argument with those in the cache of saved regular expressions, and uses the cached version if it's there. If it's not, it goes ahead and compiles the regex, saving it to the cache (and perhaps flushing an old one out, if the cache has a size limit). When the cache has become full and a compiled form must be thrown out, it's usually the least recently used one. GNU Emacs keeps a cache of up to 20 expressions. Tcl keeps up to 30. PHP keeps more than 4,000. The .NET Framework by default keeps up to only 15 expressions cached, although that can be changed on the fly or even disabled (˜ 432). A large cache size can be important because if more regular expressions are used within a loop than the size of the cache, by the time the loop restarts, the first regex will have been flushed from the cache, guaranteeing that every expression will have to be compiled from scratch every time. 6.5.4.4. Compile caching in the object-oriented approachThe object-oriented approach puts control of when a regex is compiled directly into the programmer's hands. Compilation of the regex is exposed to the user via object constructors such as New Regex, re.compile , and Pattern.compile (which are from .NET, Python, and java.util.regex , respectively). In the simple examples from Chapter 3 where these are introduced (starting on page 95), the compilation is done just before the regex is actually used, but there's no reason that they can't be done earlier (such as sometime before a loop, or even at program initialization) and then used freely as needed. This is done, in the benchmarking examples on pages 235, 237, and 238. The object-oriented approach also affords the programmer control over when a compiled form is thrown away, via the object's destructor. Being able to immediately throw away compiled forms that will no longer be needed saves memory. 6.5.4.5. Pre-check of required character/substring optimizationSearching a string for a particular character (or perhaps some literal substring) is a much "lighter" operation than applying a full NFA regular expression, so some systems do extra analysis of the regex during compilation to determine if there are any characters or substrings that are required to exist in the target for a possible match. Then, before actually applying the regex to a string, the string is quickly checked for the required character or stringif it's not found, the entire application of the regex can be bypassed. For example, with While it's trivial for a regex engine to realize what part of There is a great variety in how well different applications can recognize required characters and strings. Most are thwarted by the use of alternation . With such systems, using 6.5.4.6. Length-cognizance optimization Also see the length-cognizance transmission optimization on page 247. 6.5.5. Optimizations with the TransmissionIf the regex engine can't decide ahead of time that a particular string can never match, it may still be able to reduce the number of locations that the transmission actually has to apply the regex. 6.5.5.1. Start of string/line anchor optimization This optimization recognizes that any regex that begins with The comments in the "Pre-check of required character/substring" section on the previous page about the ability of the regex engine to derive just when the optimization is applicable to a regex is also valid here. Any implementation attempting this optimization should be able to recognize that Similar optimizations involve 6.5.5.2. Implicit-anchor optimization An engine with this optimization realizes that if a regex begins with More advanced systems may realize that the same optimization can also be applied when the leading
6.5.5.3. End of string/line anchor optimization This optimization recognizes that some regexes ending with
6.5.5.4. Initial character/class/substring discrimination optimization A more generalized version of the pre-check of required character/string optimization, this optimization uses the same information (that any match by the regex must begin with a specific character or literal substring) to let the transmission use a fast substring check so that it need apply the regex only at appropriate spots in the string. For example 6.5.5.5. Embedded literal string check optimization This is almost exactly like the initial string discrimination optimization, but is more advanced in that it works for literal strings embedded a known distance into any match. In general, this works only when the literal string is embedded a fixed distance into any match. It doesn't apply to 6.5.5.6. Length-cognizance transmission optimizationDirectly related to the Length-cognizance optimization on page 245, this optimization allows the transmission to abandon the attempt if it's gotten too close to the end of the string for a match to be possible. 6.5.6. Optimizations of the Regex Itself6.5.6.1. Literal string concatenation optimization Perhaps the most basic optimization is that 6.5.6.2. Simple quantifier optimization Uses of star, plus, and friends that apply to simple items, such as literal characters and character classes, are often optimized such that much of the step-by-step overhead of a normal NFA engine is removed. The main control loop inside a regex engine must be general enough to deal with all the constructs the engine supports. In programming, "general" often means "slow," so this important optimization makes simple quantifiers like For example, 6.5.6.3. Needless parentheses elimination If an implementation can realize that 6.5.6.4. Needless character class elimination A character class with a single character in it is a bit silly because it invokes the processing overhead of a character class, but without any benefits of one. So, a smarter implementation internally converts something like 6.5.6.5. Character following lazy quantifier optimization With a lazy quantifier, as in So, this optimization involves the realization that if a literal character follows the lazy quantifier, the lazy quantifier can act like a normal greedy quantifier so long as the engine is not at that literal character. Thus, implementations with this optimization switch to specialized lazy quantifier processing for use in these situations, which quickly checks the target text for the literal character, bypassing the normal "skip this attempt" if the target text is not at that special literal character. Variations on this optimization might include the ability to pre-check for a class of characters, rather than just a specific literal character (for instance, a pre-check for
6.5.6.6. "Excessive" backtracking detection The problem revealed with the "Reality Check" on page 226 is that certain combinations of quantifiers, such as For example, if the limit is 10,000 backtracks, For different reasons, some implementations have a limit on the size of the backtrack stack (on how many saved states there can be at any one time). For example, Python allows at most 10,000. Like a backtrack limit, it limits the length of text some regular-expressions can work with. This issue made constructing some of the benchmarks used while researching this book rather difficult. To get the best results, the timed portion of a benchmark should do as much of the target work as possible, so I created huge strings and compared the time it took to execute, say, 6.5.6.7. Exponential (a.k.a., super-linear) short-circuitingA better solution to avoid matching forever on an exponential match is to detect when the match attempt has gone super-linear. You can then make the extra effort to keep track of the position at which each quantifier's subexpression has been attempted, and short-circuit repeat attempts. It's actually fairly easy to detect when a match has gone super-linear. A quantifier should rarely "iterate" (loop) more times than there are characters in the target string. If it does, it's a good sign that it may be an exponential match. Having been given this clue that matching may go on forever, it's a more complex issue to detect and eliminate redundant matches, but since the alternative is matching for a very, very long time, it's probably a good investment. One negative side effect of detecting a super-linear match and returning a quick failure is that a truly inefficient regex now has its inefficiency mostly hidden. Even with exponential short-circuiting, these matches are much slower than they need to be, but no longer slow enough to be easily detected by a human (instead of finishing long after the sun has gone dormant , it may take 1/100 of a secondquick to us, but still an eternity in computer time). Still, the overall benefit is probably worth it. There are many people who don't care about regex efficiencythey're scared of regular expressions and just want the thing to work, and don't care how. (You may have been this way before, but I hope reading this book emboldens you, like the title says, to master the use of regular expressions.) 6.5.6.8. State-suppression with possessive quantifiersAfter something with a normal quantifier has matched, a number of "try the nonmatch option" states have been created (one state per iteration of the quantifier). Possessive quantifiers (˜ 142) don't leave those states around. This can be accomplished by removing the extra states after the quantifier has run its course, or, it can be done more efficiently by removing the previous iteration's state while adding the current iteration's. (During the matching, one state is always required so that the regex can continue once the quantified item can no longer match.) The reason the on-the-fly removal is more efficient is because it takes less memory. Applying
6.5.6.9. Small quantifier equivalence Some people like to write My tests show that with Perl, Python, PHP/PCRE, and .NET, Compare More advanced still, Perl, Ruby, and .NET recognize this optimization with either 6.5.6.10. Need cognizanceOne simple optimization is if the engine realizes that some aspect of the match result isn't needed (say, the capturing aspect of capturing parentheses), it can eliminate the work to support them. The ability to detect such a thing is very language dependent, but this optimization can be gained as easily as allowing an extra match-time option to disable various high-cost features. One example of a system that has this optimization is Tcl. Its capturing parentheses don't actually capture unless you explicitly ask. Conversely, the .NET Framework regular expressions have an option that allows the programmer to indicate that capturing parentheses shouldn't capture. |
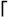 \d+
\d+  , are so common that the engine might have special-case handling set up to execute them faster than the general engine mechanics would.
, are so common that the engine might have special-case handling set up to execute them faster than the general engine mechanics would.  ] so even though the savings could be huge in the rare case, the added overhead is not worth slowing down the common case.
] so even though the savings could be huge in the rare case, the added overhead is not worth slowing down the common case.  this other)‹
this other)‹  }
}  ] characters from the end of the string, so the transmission can jump directly there, potentially bypassing much of the target string.
] characters from the end of the string, so the transmission can jump directly there, potentially bypassing much of the target string. EAN: 2147483647
Pages: 113
- An Emerging Strategy for E-Business IT Governance
- Linking the IT Balanced Scorecard to the Business Objectives at a Major Canadian Financial Group
- Measuring and Managing E-Business Initiatives Through the Balanced Scorecard
- Measuring ROI in E-Commerce Applications: Analysis to Action
- Technical Issues Related to IT Governance Tactics: Product Metrics, Measurements and Process Control