Hack 70. Break Codes with Etaoin Shrdlu
| You never know when you will have to decipher a cryptic message, whether it's one intercepted by your man, James Bond, or one scribbled illegibly onto a prescription pad by your doctor. Here are all the statistical tricks you'll need, Agent 003.14159. You might have noticed that certain keys on your computer keyboard get dirty or wear out more quickly than others. That's because you hit them more often than the others. You might also notice that these letters tend to be in the middle of the keyboard or, more correctly, in small circles near where your hands are when they are centered on a keyboard. Both the wear and tear on your keys and the placement of them in a standard typewriter (a.k.a. QWERTY, for the first six letters on the top row) pattern are based on their frequency of use in English. Different letters in the alphabet are used with different frequencies in the spelling of words in a language. By applying the known frequency of these letters, along with other statistical tricks, you can quickly decode classified documents, whether they are Leonardo da Vinci's diary, a puzzle in the newspaper, or big, bright letters being turned by Vanna White on TV. Single Substitution CiphersThe simplest and oldest type of letter-based code is the single substitution format. In these codes, some message is transformed from the actual letters in the words to other letters in the alphabet. In the simplest form of this type of coding, the same letter substitutes for the same letter throughout the message. For example, a simple cipher might use the substitution pattern shown in Table 6-18, in which the letters on the top row (the plain text) are replaced by the letters on the bottom row (the cipher text).
With a code like the one shown in Table 6-18, the following plain-text passage:
appears in cipher text like this:
The passage looks like nonsense, but with the key shown in Table 6-18, anyone could easily replace the nonsense letters with the original letters, causing the opening sentence of the second paragraph in Chapter Two of Tom Sawyer to reveal itself. Using Probability to Decode Substitution CiphersOf course, the real task when deciphering ciphers is to do it without access to the code key. Real-life code breakers and winning contestants on Wheel of Fortune use the same tool to solve their problems: they apply the known distribution of letters in English language words. The advent of computers, computer analysis, and electronic copies of millions of books has made the calculation of exact probabilities for each letter of the alphabet possible, though cryptographers (code makers and breakers) have known the basics for some time. Here are some of these basics:
With even just these basic probability facts, you could begin to tackle decoding a cipher such as our Mark Twain passage. The most commonly appearing letters in the garbled version are P and N. Because N is used as a single-letter word, it cannot be E (N is most likely A), so a good first guess for P is that it substitutes for E. With just a little knowledge of letter distribution, we have already identified the substitutes for E and A. We can't be sure we are right, but like any good statistician, we think we are probably right. Table 6-19 shows the likely distribution for each letter of the alphabet.
ETAOIN SHRDLUThe strange phrase "ETAOIN SHRDLU" is a mnemonic device (memory tool) for remembering the most frequently occurring letters. These 12 letters account for over 80 percent of total letter frequency. You might notice that the order of letters in ETAOIN SHRDLU is not exactly the rank order of popularity shown in Table 6-19. It is close enough, though, and easier to pronounce than if it were exactly correct. Another thing to remember is that any "definitive" list of letter probability depends on the source material for the letter count. You can find many different lists of letter order and frequency, and some differ slightly from others. For example, one organization that produced a list of statistical distributions of letters in English text relied on a computer analysis and actual count of letter occurrence in seven literary classics, such as Jane Eyre and Wuthering Heights. Two of these seven books were Tarzan novels. I'm guessing that if we were to compare that table of letter distributions with others, we would find that the proportional number of times the letter Z appeared was greater than if other sources were used. For the common letters, thoughsuch as E, T, and Athere is wide agreement on their use as best first guesses for code breaking.
Statistical Analysis of Coded TextsHere's how you might use these letter stats in real life to decode a secret message or solve a puzzle. This method works best if the coded text is lengthy, but it works surprisingly well even for shorter passages. Calculate the distribution of the coded, substitute letters (the cipher text), and then compare it to the distribution shown in Table 6-19. Figure 6-8 shows how this process might look graphically. Only the first 10 most common letters are shown, but the analysis would use all the letters. This example pretends that there is a lot of coded text and that the substitute cipher shown in Table 6-18 is being used. Figure 6-8. English letter frequency (left) and coded letter frequency (right)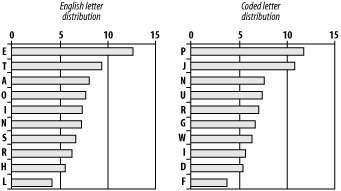 Because the most common substitute letters are P, followed by J, a good guess for breaking the code would be to see whether P could really be E and J could really be T. These first guesses can be made all the way down the line for each letter. By starting with the most frequently appearing letters and moving down the list, a code breaker can quickly see whether these first hypotheses are right or wrong and change guesses around until English words start to appear. Other Common Letter PatternsBeyond just knowing the frequency of individual letters appearing, good code breakers use probability information about other patterns of letters:
See Also
|
EAN: 2147483647
Pages: 114