Section 5.3. THE BIRTH OF AOP AT PARC
5.3. THE BIRTH OF AOP AT PARCIn the summer of 1995, as I was starting to devise a thesis proposal based on some of these ideas, I took an internship in Gregor Kiczales's group at Xerox PARC. The group at the time was working on Open Implementations [15, 17, 19]. During that summer, I implemented Demeter's traversals in a dialect of Scheme that supported OO reflection [30], reinforcing the idea that reflection was a powerful programming technique that could support Demeter's useful concepts for software evolution. Following that internship, I got an invitation to stay at PARC and continue my thesis work there. And so I did. The three years that followed were crucial both to the foundations of AOP and to me, personally: I defended my thesis at the end of the summer of 1997. Between 1995 and 1997, I continued to work under Karl Lieberherr's supervision, but I had Gregor Kiczales as a co-advisor. I can't remember the exact date when we decided to call our work "aspect-oriented programming," but I remember the term was suggested by Chris Maeda, the most business-oriented person of the group. Another name being tossed around was Aspectual Decomposition and Weaving (ADW), which was dropped. In my notebook, the first reference to "AOP" occurs at the end of November 1995. In January 1996, my notebook indicates that we were using Open Implementation and AOP at the same time, although for different pieces of the group's work. By June of 1996, Gregor Kiczales gave a couple of public talks about AOP, one in the ACM Workshop on Strategic Directions in Computing Research, and another one in one workshop at ECOOP organized by Mehmet Ak One other word that defined AOP was the word "weaver." Again, I can't remember the exact date when that word emerged and who suggested it, but it must have happened in late 1995 or early 1996. Weaver was the name we gave to the pre-processors that would merge the components and aspect modules into base language source code. Later, this word was disfavored because it had a strong connotation with text pre-processing. But "weaver" is still a good word for the AOP language processors, even though they are more than simple text pre-processing. The latest version of the AspectJ compiler is a good example of bytecode weaving that supports the join point model. In October of 1996, we held a workshop at PARC to which we invited certain people who were pursuing work related to separation of concerns. That was the kick-off meeting for discussing AOP beyond our group; I'll say more about that in the next section. In this section, I'll focus on work done by the group at PARC. 5.3.1. RGOne of the projects going on at PARC when I got there was RG [33, 35]. The concern that was targeted in that project was optimizing memory usage when composing functions containing loops over matrices. Although optimizing memory usage has never since then been analyzed as an aspect, the RG example was actually very interesting, and it was chosen as the leading example in the first AOP paper [18]. The reason RG is interesting is that the problem in it illustrates quite well, even better than the AspectJ examples, what I think is the essence of AOP: the need for more powerful referencing mechanisms in a programming language. The aspects in RG expressed issues like the following (citing from [35]):
While I might have chosen a slightly different wording, what this quote shows is that there is the need to refer to lots of different things: "every message send" of a certain kind, "before computing its arguments," and certain "loop structures" in the target object and the arguments. These are all referencing needs that are not supported by most programming languages and that the group at PARC was trying to support. 5.3.2. AMLA second project under way was Annotated MatLab, or AML [13]. The problem addressed here was the optimization of certain MatLab programs, again focusing on memory usage and operation fusion. The AML solution was to annotate the MatLab code with special directives, mostly declarative, that augmented the code with information so that a language processor could produce optimized code. There were many discussions within the group at PARC regarding whether AML was AOP or not. The final language annotations didn't look like our other systems in that they weren't separated from the base code but rather were still embedded in it. But, more importantly, it was hard to express in plain English the abstractions that those directives captured. For this reason, AML didn't make it to the ECOOP paper. It served, however, as a data point to formulate what aspect-oriented programming should or shouldn't be like. 5.3.3. ETCMLBetween the summer of 1995 and the summer of 1997, John Lamping was working, among other things, on a little system called Evaluation Time Control Meta Language (ETCML). The idea was to provide a set of directives that programmers could use in order to instruct the language processor about when to evaluate certain pieces of code. This work was in the sequence of the work in Reflection more precisely, to identify whether certain parts of the code should be evaluated at compile-time or at runtime. This came from the need to optimize meta-object protocols, making them be compiled away. The thesis there was that the language processor could not always determine the best evaluation time and that input from the programmer would simplify immensely the task of the language processor. In ETCML, evaluation time was being analyzed as a software development concern that had important consequences on run-time performance. This work served as another interesting data point to think about software development concerns that were relatively independent from the functional code. 5.3.4. DJPrior to the doctorate program, my background was in distributed operating systems [43]. That led me to the search for better expression mechanisms for distributed programming. When I went to PARC, I had outlined my thesis in two publications: an ECOOP paper [29] and an ISOTAS paper [26]. Those were the pillars of my dissertation: a couple of small languages for distributed programming, which I called D (as in Distributed Programming) and their specification as an extension to Java, DJ [27]. The two little languages were called COOL and RIDL.[1]
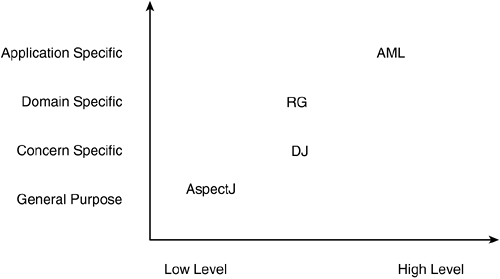
DJ was different from RG, AML, and ETCML and used a technical approach more similar to that of Demeter [22, 24] than that used at the time by the group at PARC, i.e., Reflection [16] and Open Implementation [15, 19]. For starters, DJ didn't target run-time optimizations; it targeted program-time expressiveness for some distributed programming concerns. RG, AML, and ETCML had a top-down flavor: There was the notion of what a well-designed program should look like, and they were adding more instructions for tuning the performance without modifying the original well-designed programs. DJ had a bottom-up flavor: Based on what distributed programs looked like, usually messy, I was trying to reorganize the code so that certain concerns that were tangled in Java could be untangled. In the process, I was defining language constructs that would allow me to do that. In the end, the combination of the top-down and bottom-up approaches proved to be fruitful. I didn't particularly like the meta-level programming model. Certainly that model and the resulting techniques could be used to separate the concerns I was studying, but it felt awkward, though it was the only decent model at the time. Meta-objects have a beautiful run-time interpretive semantics; I wanted a compile-time process. Compile-time reflection loses the beautiful simplicity of the run-time reflection model: Meta-objects start to feel and act like macros. Therefore, one is led to question whether that is the right model for compile-time processes at all. I didn't think so. I thought compile-time reflection introduced unnecessary complexity to the expression mechanisms I was looking for. Here is what I was looking for. For synchronization, I wanted to be able to say things like, "Before executing the operation, take in BoundedBuffer objects, make sure no other thread is executing it in the same object, and make sure the buffer is not empty; otherwise wait," or "After executing the operation, take in BoundedBuffer objects, check if the buffer is empty, and if so, mark it as empty; also, check if the buffer was previously full, and if so, mark it as not full." I also wanted to allow the expression of multi-object coordination schemes for concurrent agents like "Before executing the operation activate in the Engine object, make sure the Door object is closed." It seemed awkward to me that in order to say this, I would have to define metaclasses, instantiate and associate a meta-object for every base object, trap every message sent to the base objects, and execute their meta-objects code at those points. For multi-object coordination schemes, the one-to-one association between base and meta-objects wasn't even appropriate: we would want one single coordinator associated with the objects involved in the coordination scheme. For remote parameter passing, I wanted to be able to say things like, "When the operation getBook of Library objects is invoked remotely, the returned Book object should be copied back to the client, but the field shelfCopies shouldn't be included," or "When the operation borrowedBooks(User) of Library objects is invoked remotely, the only information that's needed from the User parameter is the User's name, so copy only that." Again, it seemed awkward that in order to express this, I would have to use the reflection model. Things would get even more confusing when these directives were to have a static code generation effect, which was what I was looking for. Although the reflection model might be a reasonable implementation model for the process, it certainly wasn't true to the intentions of synchronization and remote parameter passing directives, as expressed in plain English. The problem, then, was the expression of referencing. So I came up with a simpler referencing mechanism, which was inspired by a body of previous work done by other people, but especially by my advisor Karl Lieberherr's Demeter system [22]. The directives, expressed separately from the classes, would refer to the object's operations and internals by name: coordinator BoundedBuffer { selfex put, take; mutex {put, take}; condition empty = true, full = false; put: requires !full; on_exit { if (empty) empty = false; if (usedSlots == capacity) full = true; } take: requires !empty; on_exit { if (full) full = false; if (usedSlots == 0) empty = true; } } and portal LibrarySystem { boolean registerUser(User user) { //Only strings. Everything else of User is excluded. user: copy {User only all.String;} }; Book getBook(int isbn){ //for return object, exclude the field shelfCopies return: copy {Book bypass shelfCopies;} }; BookList borrowedBooks(User user) { //for return object, exclude the field shelfCopies return: copy {Book bypass shelfCopies;} // for User, bring only the name user: copy {User only name;} }; } The binding, by direct naming, was unidirectional from these modules to the classes they referred to, and not the other way around. In other words, contrary to the dominating paradigm that said that each module must specify itself and its dependencies completely, this scheme allowed the definition of modules that would "impose" themselves on other modules without an explicit request or permission from the latter. With this scheme, it was trivial to plug in and unplug concern-specific modules with a compilation switch. This scheme also scaled nicely for multi-object schemes: just add more class names to the list of classes the coordinators and the portals were associated with, and we could refer to the operations and internals of those classes. For example: coordinator Engine, Door {...} 5.3.5. DJavaUp until 1997, DJ was my own little piece of work, a system that I had carried with me from Northeastern, and one among others that we, as a group, were working on. In 1997, things changed. I spent most of that year locked in my apartment writing my dissertation, so I didn't participate much in the group's activities. In the spring, Gregor decided to invest the group's resources into the implementation of a DJ weaver, a pre-processor written in Lisp. That first language implementation, called DJava, supported COOL and some of RIDL. Over that summer, they planned a usability study. The users were four summer interns. They wrote a distributed space war game with it. (This came in handy, as I was writing the Validation chapter.) A report of those activities can be found in my dissertation ([27], Chapter 5). We used that application as an example for a long time. At the end of the summer, Gregor decided to use DJava as the flagship system, the seed of what later became AspectJ. In the meantime, back at Northeastern, Karl Lieberherr also decided to incorporate DJ into Demeter/Java. That happened from the end of 1997 throughout 1998. 5.3.6. AspectJThe first version of AspectJ, made public in March of 1998, was a reimplementation of DJava. It supported only COOL. Another release followed soon; I believe it was AspectJ 0.1. It included RIDL. A group at the University of British Columbia did some preliminary usability tests with this version. The results can be found in [47]. As release 0.1 was coming out, at the end of April of 1998, AspectJ suffered a transfiguration. Gregor wanted to develop a general-purpose aspect language. DJ was a couple of concern-specific languages; it wasn't very useful for general-purpose programming. The decision to make AspectJ general-purpose wasn't simple, at least for me. We had already released two versions, and changing the language's philosophy would probably confuse those who had been using it as a reference for AOP. But more importantly, it wasn't at all obvious to me how a general-purpose aspect language would, indeed, be useful at the time, given the limited number of crosscutting concerns we had previously identified. What examples would we use to justify and explain it? In retrospect, it is clear my fears were inconsequential. AspectJ is a lot more useful for a larger number of software development needs than it would have been if we had continued the path we initially set, which was, by design, limited. DJ served AOP well, but it was time to grow it. What follows is a brief analysis of what it took to make the shift from concern-specific to general-purpose. In a paper we published in the summer of 1998 [28], we used the image shown in Figure 5-1 to describe the range of languages we had been designing. Figure 5-1. Languages under design.
How did we move from concern-specific to general purpose? What was preserved, what was added, and what was thrown away? This is my view about the transition process. Significant differences:
Significant clarifications:
Significant preservations:
Past the transition from concern-specific to general-purpose aspect language, which happened in 1998, AspectJ evolved considerably. Part of that evolution was due to the commitment to a solid advanced development plan. The support from DARPA, starting in 1998, allowed Gregor to get the resources he needed. In early 1999, the weaver was rewritten in Java, which made the system much more portable than the previous Lisp version. At the end of that year, there were extensions to existing Integrated Development Environments. The design of AspectJ stabilized when it got to release 0.7 in the first half of 2000. That was also the time I started pursuing other interests. In concluding this section, I should note that many people were directly involved in the AOP project at PARC at various times besides Gregor Kiczales and myself. In the early days of AOP, the group included John Lamping, Anurag Mendhekar, Chris Maeda, Jean-Marc Loingtier, and John Irwin. Venkatesh Choppella was there during the transition from DJ to the general-purpose AspectJ. Jim Hugunin and Mik Kersten joined in the transition to advanced development. Others, including Erik Hilsdale, joined after I left the project and helped solidify the technology even further. Over the years, more than a dozen summer students contributed to the project; I can't remember all of their names, so I will leave them anonymous. |

EAN: 2147483647
Pages: 307