Section 3.3. MULTI-DIMENSIONAL SEPARATION OF CONCERNS
3.3. MULTI-DIMENSIONAL SEPARATION OF CONCERNSThis section introduces a model of decomposition and composition that we believe satisfies these needs. The model is used in conjunction with developers' artifact formalism(s) of choice, giving developers additional power without requiring changes to the formalisms. We begin with a model of conventional software, to set the context and introduce some terminology, then describe our model and show how it addresses many of the issues raised earlier. 3.3.1. A Model of Conventional SoftwareA particular software system is written to address some problem or provide some service within a problem domain. To do this, it must model or implement a variety of concepts of importance in that domain. These concepts include objects (e.g., "expression" in the example), functionality (e.g., "evaluation"), and properties (e.g., "persistence"). Concepts derived directly from the domain as well as internal software concepts (e.g., data structures) are both important. The software system itself consists of a set of artifacts, such as requirements specifications, designs, and code. Each artifact consists of descriptive material in some formalism, whose purpose is to model needed concepts in a manner appropriate for that artifact. The formalisms differ for different projects, different phases, and different artifacts, and perhaps even within an artifact. Different artifacts often share the same concepts, with each concept potentially being described in a different way, and with different details, in the different artifacts. For example, the word expression in the requirements and the class Expression in the design and code all describe the concept "expression" in their rather different ways and at different levels of detail. It is convenient to think of the descriptive material in each artifact as being made up of units. What constitutes a unit depends on the formalism, and perhaps on the context. For example, in object-oriented design formalisms or programming languages, classes are one kind of unit. If one looks below the class level, individual methods may also be considered units. This illustrates the important point that formalisms typically consist of at least some basic elements, which we call primitive units, and some grouping construct(s), which we call compound units or modules. We treat primitive units as indivisible; our model works with them, but never looks inside them. A single concept is typically modeled by a collection of many units (primitive or compound). Perhaps surprisingly, a single unit often participates in modeling more than one concept. For example, the eval() method within the Plus class participates in modeling both the "plus expression" concept and the "evaluation" concept. The purpose of modules is to accomplish separation of concerns [19]. Even software systems of moderate size contain so many primitive units that they cannot all be held in one's mind at once. When performing some development task, a developer must be able to focus on those units that are pertinent to that task and ignore all others. To accomplish this, software engineers identify concerns of importance, and seek to localize units representing concepts that pertain to each concern into a module. Ideally, one only need look inside a module if one is interested in a given concern. For example, a class is a module containing units (describing methods and instance variables) that model a particular kind of object; all internal details of such objects, such as their representation, are described within the class. Many kinds of concerns are important during the software lifecycle. These dimensions of concern help to organize the space of concepts and units. Common dimensions of concern are data or object (leading to data abstraction) and function (leading to functional decomposition). Others include feature (both functional, such as "evaluation," and cross-cutting, such as "persistence"), role, and configuration. As illustrated by these examples, some dimensions of concern derive from the domain, often aligning with important domain concepts, while others come from system requirements, from the development process, and from internal details of the system itself. In short, there are any number of dimensions of concern that might be of importance for different purposes (e.g., comprehension, traceability, reusability, evolvability, etc.), for different systems, and at different phases of the lifecycle. Modern artifact formalisms typically allow decomposition (i.e., grouping of units) into modules according to only a single dimension of concern, which we term the dominant dimension. The formalism often dictates specifically what the dominant dimension must be. For example, object-oriented formalisms support decomposition based on the object (or data) dimension, while procedural and functional programming languages permit decomposition based on function. Even formalisms that do not impose a specific dominant dimension typically do not support simultaneous decomposition according to multiple dimensions, so the developer ultimately chooses a dominant dimension. In either case, the modular structure of the artifact achieves separation of concerns only along this dominant dimension. Thus, in our model, a conventional software system is a set of artifacts that model domain concepts in appropriate formalisms. Artifacts contain modules, which contain units. The modular structure reflects decomposition based on one dominant dimension of concern. 3.3.2. Multi-Dimensional Decomposition: HyperslicesAs discussed in Section 3.2, decomposition according to concerns along a single, dominant dimension is valuable, but usually inadequate. Units pertaining to concerns in other dimensions end up "scattered" across many modules and "tangled" with one another. Separation according to these concerns is, therefore, not achieved. To alleviate this problem, we introduce hyperslices as an additional, flexible means of decomposition. A hyperslice is a set of conventional modules, written in any formalism. Hyperslices are intended to encapsulate concerns in dimensions other than the dominant one. The modules within it contain all, and only, those units that pertain to, or address, a given concern. Hyperslices can overlap, in that a given unit may occur, possibly in different forms, in multiple hyperslices. This supports simultaneous decomposition according to multiple dimensions of concern. A system is written as a collection of hyperslices, thereby separating all the concerns of importance in that system, along as many dimensions as are needed. The hyperslices are composed to form the complete system (discussed below). The choice of the term "hyperslice" is intended to reflect relationships to both "program slicing" [25] and "hyperplane." Hyperslices are similar to program slices in that both involve cuts through a system that do not align with the standard modules. They differ, however, in that program slices are at the code level only, generally consist specifically of statements that affect particular variables, and are extracted from existing programs by analysis, rather than being used to build systems by composition. Hyperslices are hyperplanes in that they encapsulate concerns that cut across multiple dimensions in a space defined by the dimensions of concern. To demonstrate the utility of hyperslices, we consider the initial version of the expression SEE described in Section 3.2. We identified two separate dimensions of concern applicable to the initial design: object (different kinds of expressions) and feature (display, evaluation, and basic checking). Since we used object-oriented formalisms for the design and code, the object dimension was the dominant one, and separation of concerns along that dimension was effective. Separation by feature could not be accomplished, however, leading to scattering and tangling of feature-specific units. We therefore introduce five hyperslices, one to encapsulate each of these concerns (features), as shown in Figure 3-3. One hyperslice encapsulates the basic ("kernel") expression AST capabilities (node creation, accessor, and modifier methods), modularized using UML classes in the design and Java classes and interfaces in the code. The other hyperslices encapsulate, respectively, the display, evaluation, and syntax and semantic checking features. Note that these hyperslices also contain many of the same class modules as found in the kernel hyperslice (i.e., their concerns overlap), but the modules in these hyperslices contain only those units that pertain to the particular concern they encapsulate. Thus, e.g., the display hyperslice defines display() methods and instance variables (units) in AST node classes (modules), while the evaluation hyperslice defines eval() methods and instance variables. Figure 3-3. Defining the SEE with Hyperslices.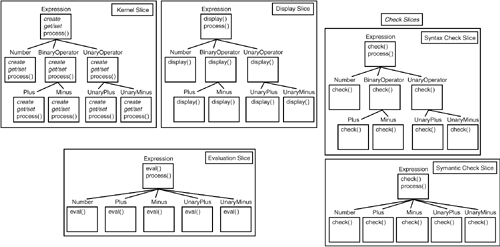 Note that hyperslices have been introduced without requiring the definition of new artifact formalisms. We deliberately do not modify the artifact formalisms themselves, preferring instead to allow developers to use their familiar formalisms throughout the lifecycle. The modules within a hyperslice are standard modules in the desired formalism, except that they contain only those units pertinent to the hyperslice's concern. That means that these modules might not satisfy all of the completeness constraints that the formalism normally requires. For example, the implementation code in the display hyperslice might refer to accessor methods that it does not define, on the expectation that the kernel hyperslice will provide them. This is not legal in Java, which requires modules to define any methods they use. It is fine in our model, however, because hyperslices are eventually composed together to form a "complete" hyperslice that must satisfy all of the formalism's constraints. The definition of hyperslice above is sufficiently broad that it is possible, for any concern, to form a hyperslice consisting of exactly those units pertaining to that concern. For example, hyperslices can correspond to features, to units of change, or to specific customizations or components. If this approach is followed for all concerns of interest in a system, there is likely to be a good deal of overlap: the same unit, or different units describing the same concept, might be involved in multiple concerns. We saw this in the expression exampleeach of the hyperslices includes expression concepts in the form of class modules, but it defines those concepts in a way that is appropriate to its task. Overlap is acceptable; indeed, it is responsible for much of the power of this approach. Composition must be able to resolve the overlap, as discussed later. This great flexibility raises the question of how developers should choose hyperslices for decomposing a given system, and whether the freedom is likely to lead to error and abuse. Simple uses, such as for major features or units of change, provide great benefit with little difficulty. Formulation of guidelines for more complex use of hyperslices is an issue for future research. Even with outstanding guidelines, however, use of hyperslices, like any other modularization mechanism, requires good judgement. If key structural decisions turn out to be incorrect because of design error or dramatic changes to requirements, system restructuring may be necessary, as with conventional technology. The support for simultaneous separation of concerns along multiple dimensions, however, opens the possibility of introducing new dimensions and ignoring obsolete ones, without dismantling the system. This, too, needs further research. 3.3.3. Composing Hyperslices Using HypermodulesHyperslices provide a flexible means of decomposing artifacts. To be useful, however, it must be possible to compose them to produce complete and consistent artifacts in unchanged artifact formalisms of choice. A hypermodule is a set of hyperslices, together with a composition rule that specifies how the hyperslices must be composed to form a single, new hyperslice that synthesizes and integrates their units. Because of this composition property, a hypermodule is appropriate wherever a hyperslice may be used. Hypermodules can thus be nested. An entire artifact can be modeled as a hypermodule; the artifact consists of all the modules in the composed hyperslice and must satisfy whatever consistency and completeness constraints are required by the artifact formalism. The system as a wholeall of its artifactscan also be modeled as a hypermodule, whose composition rule describes the relationships between the artifacts. The simplification of these relationships, made possible by hyperslices, and their reification in the composition rule, is a key advantage of this model. Figure 3-4 shows a hypermodule consisting of the hyperslices from Figure 3-3. The composition rule must indicate which units in the hyperslices describe the same concepts, and how those units must be integrated. In this case, it asserts that classes in different hyperslices with the same name model the same concept and should be "merged" into a new, composed class with the same name and combined details. When the composition rule is applied, the resulting hyperslice contains exactly the modules shown in Figure 3-1. Notice that the syntax and semantic checking hyperslices can be grouped optionally into a "check" hypermodule that is nested within the SEE hypermodule. The result of (optionally) composing the syntax and semantic checking hyperslices within the "check" hypermodule is a check hyperslice, which can then be composed with the other SEE hyperslices. The ability to nest hypermodules in this manner promotes abstraction and encapsulation. Figure 3-4. Composing Hyperslices using Hypermodules.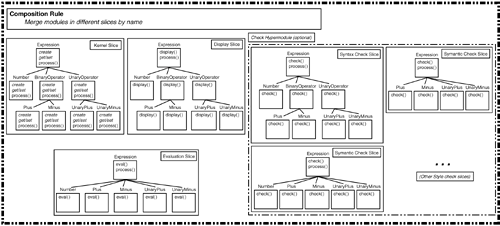 Details of composition vary greatly depending on the formalism in which units are written, and on which of the formalism's constructs are treated as units and modules. These are details that are specified as part of an instantiation of this model (described in detail in Section 3.4, which represents a mapping between a particular formalism and the concepts embodied within the model. They are also dependent on the details of the particular units involved, and can vary from straightforward to highly complex. Nonetheless, some general properties are worth discussing. Composition is based on commonality of concepts across units: different units describing the same concept (usually, though not necessarily, differently) are composed into a single unit describing that concept more fully. This process involves three steps: matching units in different hyperslices that describe the same concept, reconciliation of differences in these descriptions, and integration of the units to produce a unified whole. Clearly, composition cannot be a fully automatic process. It is the task of the composition rule in the hypermodule to specify the details of composition. One approach to composition rules, suggested by our work on subject-oriented programming [7, 17], is for the rule to be a combination of a concise, general rule, and detailed, specific rules that specify exceptions to the general rule or handle cases that it cannot handle. The general rule essentially names an automatic approach to apply as a starting point or default, such as matching by unit name (i.e., the name denotes the concept). General rules can be applied to an entire composition, or selectively to portions of it; different automatic approaches can thus be applied to different areas of a composition. Only in cases where no automatic rule suffices are detailed rules needed, in which the developer says explicitly exactly what to do. Detailed rules can handle such issues as matching units with different names that do describe the same concept, not matching units with the same names that do not describe the same concept, and reconciling different module structures, such as matching units nested at different depths in different hyperslices that nonetheless describe the same concept. The degree of mismatch in module structure and abstraction level that can be handled effectively is an issue for future research, as is determining how much mismatch occurs in practice in composed hyperslices. An alternative is to split the composition rule across the hyperslices, allowing each hyperslice itself to specify how it is to be composed. If the rule in a hyperslice can refer to other hyperslices, this increases coupling and reduces reusability of hyperslices; if it cannot, this limits the flexibility with which overlap can be handled. Putting the composition rule a level higher, in the hypermodule, allows both flexible overlap and enhanced reuse. In this model, therefore, developers write each artifact as a hypermodule. For each concern of importance that cannot be encapsulated effectively using the artifact formalism, they write a hyperslice that consists of modules in the artifact formalism. They also write a composition rule that specifies how these hyperslices are to be composed into a set of legal modules that make up the artifact. They also write an enclosing hypermodule that contains all the artifacts and whose composition rule specifies the relationships between them. 3.3.4. Using the ModelWe have already begun to see how this artifact model can help to address some of the software lifecycle problems identified in Section 3.2.3. We now explore its impact on these problems in more detail, by revisiting the expression SEE example. We apply the same software development and evolution process, but this time, we use the proposed artifact model. We then evaluate how well the resulting artifacts address the problems presented earlier. 3.3.4.1 Revised First Go-RoundAs described in Section 3.3.2, Figure 3-3 shows a somewhat different decomposition of the design and code artifacts than that produced during the initial design and coding process (depicted in Figure 3-1). The model has allowed us to separate the major non-object concerns identified during requirements-gathering: the "kernel," which encapsulates basic functionality pertaining to expressions, and display, evaluation, and checking features. Each of these concerns is encapsulated in a hyperslice. Since we chose to decompose the check feature further, we represent it as a nested hypermodule, which includes two subhyperslices, one each for the syntax and semantic checkers. This decomposition has some significant benefits. First, hyperslices permit decomposition along multiple dimensionsin this case, object and featureeven within object-oriented formalisms that generally support only the object dimension. Second, the improved separation of concerns eliminates the scattering and tangling problems we saw earlier, by keeping units pertaining to separate requirements and features separate. A key benefit is that we have achieved encapsulation of coherent concerns across the lifecycle. This improves traceability and can significantly simplify the interrelationships among different artifacts that are traditionally so difficult to maintain. This approach also improves reusability considerably. For example, the entire expression AST concept, from requirements all the way to code, has been defined in a context-independent manner and can be reused readily, since the context-specific pieces are encapsulated in other hyperslices. The use of composition to assemble hyperslices into the final SEE provides some substantial benefits as well. Observe that because composition of hyperslices is always optional, we have managed, just by separating the concerns, to ensure that we will later be able to "mix-and-match" syntax and style checking. We can also create versions of the SEE that contain different combinations of checking, evaluation, and display featuresan ability we did not have in the original SEE. Notice also that we have a choice over how we define our hypermodules. We could, for example, define three hypermodules: one each that includes all hyperslices pertaining to a particular artifact. This allows us to compose the full requirements specification, design, and code artifacts. But we could also choose to define one hypermodule per concerne.g., an "expression" hypermodule, which contains the requirements, design, and code hyperslices that encapsulate the "kernel," a "display" hypermodule that encapsulates all artifact hyperslices pertaining to display, etc. Both kinds of composition are valid and are useful for different purposes; the former permits the creation of the final artifacts, while the latter facilitates reuse of concerns and permits certain forms of inter-artifact completeness and consistency checking. As noted earlier, developers may need to decompose or compose differently for different reasons. This model permits them to do just that. 3.3.4.2 SEE Evolution: Saving the EnvironmentClients eventually requested support for optional persistence of expressions and for multiple forms of style checking and the ability to "mix-and-match" types of checks. Persistence is a new concern; it represents both a new feature and a unit of change. As such, its addition is not supported well by object-oriented separation of concerns, as we saw in Section 3.2.2. This time, we choose to model persistence as an independent concern (hyperslice), which both encapsulates it and provides us the opportunity to use ASTs with or without persistence. Adding style checkers is trivialthe checking hyperslice already separates syntax and semantic checking, so we need only define the style checkers as hyperslices and compose any set of them together with the syntax and/or semantic check hyperslices. Notice that these new capabilities do not require any modifications to existing hyperslices or artifactsthey can be encapsulated as separate concerns and composed with the existing artifacts. 3.3.4.3 Postmortem RevisitedWe now revisit the set of software engineering problems discussed in Section 3.2.3. Impact of change: Much of the reason for high impact of change is the mismatch between the units of change and the units of abstraction and encapsulation within artifacts. With our model, however, units of change can be separated and encapsulated like any other concern. This can, in many common cases, significantly reduce or eliminate the impact of change. Reuse: As noted above, this model may significantly improve reuse of all artifacts. It permits the separation of generally useful capabilities from special-purpose ones, and it provides composition as a very powerful, non-invasive customization and adaptation mechanism. Thus, it is simpler to create reusable components and to pick up and tailor a component to a particular need. Traceability: The ability to identify, encapsulate, and co-structure similar concerns across different artifacts greatly facilitates traceability and propagation of change across the lifecycle. While the appropriate use of the model can directly result in the benefits we have described (and many we have not), it is not a panacea for bad design, bad code, or poor modularization. Further, overseparation of concerns is as bad as underseparationit leads to large numbers of hyperslices with complex interrelationships, and may actually reduce comprehension and increase complexity. Nonetheless, we believe the model is a valuable tool with potentially high benefit, if used properly. |
EAN: 2147483647
Pages: 307