Section 3.2. MOTIVATION
3.2. MOTIVATIONTo illustrate some pervasive and serious problems in software engineering that help motivate our work, we present a running example involving the construction and evolution of a simple software engineering environment (SEE) for programs consisting of expressions. We assume a simplified software development process, consisting of informal requirements specification in natural language, design in UML, and implementation in Java. 3.2.1. The First Go-RoundThe initial set of requirements for the SEE are simple:
Based on these requirements, we design the system using UML. Figure 3-1 shows a subset of the design, which represents expressions as abstract syntax trees (ASTs) and defines a class for each kind of AST node. Each class contains accessor and modifier methods, plus methods eval(), display(), and check(), which realize the required tools in a standard, object-oriented manner. Figure 3-1. Initial (Partial) Design Artifact for SEE.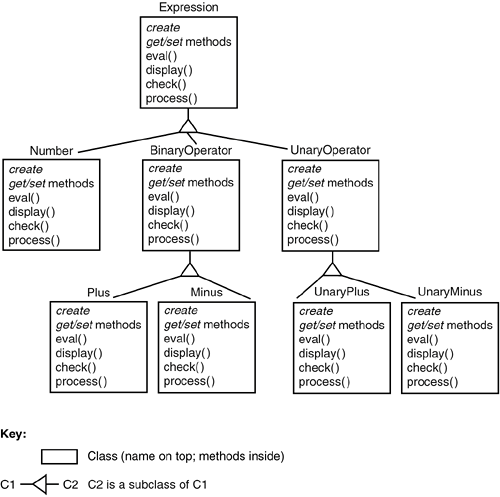 The code that implements this design has a similar structure, except that it separates interfaces to AST nodes from implementation classes, resulting in two hierarchies instead of one. This simple example raises some noteworthy issues that occur commonly in software. Despite being representations of the same system, each of the three kinds of artifacts decomposes the system differently. The requirements decompose by tool, or feature (e.g., [23]), while the design and code decompose by object. The code further separates interface from implementation parts. The difference in decomposition models leads directly to scatteringa single requirement affects multiple design and code modulesand tanglingmaterial pertaining to multiple requirements is interleaved within a single module. These problems compromise comprehension and evolution, as we will see shortly. 3.2.2. Evolving the SEE: An Environmental HazardAfter using the SEE for some time, clients request some changes in the system:
Unfortunately, these seemingly straightforward enhancements have a significant impact on the design and code. Figure 3-2 shows the impact on the Java implementation class hierarchy. A simple implementation of persistence requires adding "save" and "retrieve" methods to all AST classes, and inserting additional code into all accessor and modifier methods to retrieve persistent objects upon first access and to flush modifications back to the database. This represents a non-trivial, invasive change to all AST design classes and to all of the interfaces and implementation classes in the code, a serious case of scattering.[1] Code to support retrieval and update of persistent objects becomes tangled with other code in the accessor and modifier methods, impeding comprehensibility and future evolution. Further, the persistence code also has an impact on the new style checkers. If the persistence option is present, the style checkers must include their state information in the persistent representation of expressions. This kind of context-dependent feature is extremely difficult to represent in modern formalisms.
Figure 3-2. The Java Implementation Classes, Post-Evolution.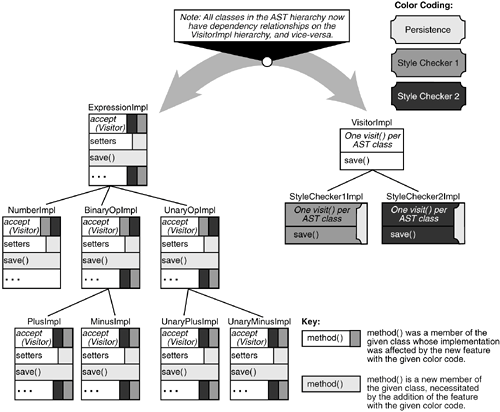 The ability to permit arbitrary combinations of checks is also problematic. It requires special infrastructure support, in both the design and implementation. This infrastructure is not presentit comes at high cost in terms of conceptual complexity and run-time overhead, so it was not included originally, as it was not necessary. We choose to address this problem by retrofitting the Visitor design pattern [5], which permits optional combinations of features, into the design and code. Visitor requires us to replace all AST check() methods with accept(Visitor) methods, and to define a separate Visitor class for each type of check. The modifications to the check feature needed to support this capability are invasive, affecting every module in the design and code, and complicating all the artifacts and their interrelationships. The presence of arbitrary checks further complicates the persistence capability, since the information to be made persistent depends on the particular combination of syntax and/or style checkers. Finally, these modifications significantly impede the future evolution of the artifacts. They introduce a higher degree of coupling between the AST classes and the visitor classes, as evident in Figure 3-2, and the presence of visitors in the design will necessitate extensive changes to accommodate modifications to the AST hierarchy [5]. 3.2.3. The PostmortemThis example demonstrates, in a microcosm, many problems that plague software engineers and suggests why we still fall short of our goals. Impact of change: The goal of low impact of change requires additive, rather than invasive, change. Yet conceptually simple changes, like those in the expression SEE, often have widespread and invasive effects, both within the modified artifact and on related pieces of other artifacts. This is primarily because units of change often do not match the units of abstraction and encapsulation within the artifacts. Thus, additive changes in one artifact, like requirements, may not translate to additive changes in other artifacts, like design and code. Modern extensibility features, such as subclassing and design patterns, help but are not sufficient [16] because they require significant pre-planning. It is not feasible to pre-enable artifacts for all possible extensions, even if it were possible to anticipate them. Reuse: Despite wide recognition of its benefits, reuse is limited and occurs mostly on code, not requirements or designs. Part of the impediment to large-scale reuse is that larger artifacts entail more design and implementation decisions, which can result in tangling of concerns and coupling of features, reducing reusability. Given large and complex artifacts, plus the weak set of adaptation and customization capabilities available in most formalisms, developers face a significant amount of invasive work to adapt a component for a given context. Traceability: Different artifacts are written for different purposes and include different levels of abstraction. Thus, they are specified in different formalisms and are often decomposed and structured differently. A case in point is the requirements scattering and tangling problem illustrated earlier. No clear correspondence of abstraction or structure across artifacts exists, in general, to aid traceability. Instead, developers must create connections among related artifacts explicitly (e.g., [9]). These connections are complex, can be invalidated readily, and, most importantly, they do not reduce scattering or tangling. They can help developers assess the impact of a given change, but they cannot localize it or reduce its impact. Developers must therefore make invasive, time-consuming changes to multiple artifacts to propagate the effects of a given change. When time constraints are tight, they often choose to make changes only to code, letting other artifacts become obsolete. We believe that a major cause of these impact of change, reusability, and traceability problems is the "tyranny of the dominant decomposition." Existing modularization mechanisms typically support only a small set of decompositions, and usually only a single "dominant" one at a time. This dominant decomposition satisfies some important needs, but usually at the expense of others. For example, a decomposition may be chosen to limit the impact of some changes, but traceability may thereby be sacrificed (or, indeed, the ability to limit the impact of other changes); or, in a data decomposition designed to match application-domain concepts, code for a feature may be scattered across multiple application modules and tangled with code for other features. To make matters worse, different formalisms typically support different dominant decompositions, reducing traceability across artifacts. Many different kinds of concern are important in a software system, and designating one of them as dominant in each context, at the expense of the others, contributes significantly to the problems identified above. 3.2.4. Breaking the TyrannyTo achieve the full potential of separation of concerns, we need to break the tyranny of the dominant decomposition. In the example and related discussion, several kinds of concerns were identified:
If the system could be modularized according to concerns of all these kinds, simultaneously, the problems described above would be greatly ameliorated. Traceability would be improved by encapsulating features separately, with clear correspondence between the representation of a particular feature in different artifacts (i.e., co-structuring). Impact of change would be reduced by the ability to encapsulate each unit of change separately. Reuse would be enhanced by the improved traceability, and by separating customization details from the base component, provided composition is rich enough to apply them effectively. These are just a few of the dimensions of concern along which separation may be desirable. Others include: to match conceptual abstractions; to conform to a given modeling paradigm (object-oriented, functional, etc.) or to take advantage of special-purpose formalisms; to separate "optional" from "required" pieces; to separate variants for different host systems, classes of users, etc.; to permit distribution or parallel processing; to facilitate concurrent or cooperative development; etc. The possibilities are limitless, and vary with context. What is more, different dimensions of concern are seldom orthogonal: they overlap, and can affect one another. A truly flexible approach to modularization must allow any and all that are needed to apply simultaneously, and must be able to handle overlap and interactions among them. |
EAN: 2147483647
Pages: 307