Database Design Considerations
3 4
Before you begin creating a database, it's a good idea to do some planning and preparation. Sometimes when you're creating a database for another person, you're given a vague, high-level description of what the database is supposed to do, without any guidance as to the desired interface or what type of users will be performing what tasks with the database. At other times, you might be given instructions in excruciating detail, accompanied by stacks of hard-copy documents more suitable for pencil and paper work than computer data input.
Sometimes these instructions are based on the requirements of obsolete databases, or even on nondatabase programs such as Microsoft Excel, so the instructions might be difficult-or even impossible-to implement. A typical example is data entered in all uppercase, which might have been the only way data could be entered in some long-ago database from the 1950s, but now just makes the data hard to read.
As a database creator, you need to step back and analyze the database's requirements before starting work. Rather than try to follow vague or inappropriate instructions literally, you need to determine what the database should do and then construct the database in Access so that it does what the users need it to do and is easy for them to work with. The following sections introduce some of the considerations involved in designing a database.
Planning the Database
Before you begin work constructing the Access database, make sure you know what your customer is expecting in response to the following questions:
- What are the overall goals of the database?
- What specific tasks will the database perform?
- How do users want to output information from the database?
- What kinds of users will be working most with the database, and what is their level of comfort with Access and computers in general?
- Are the tasks or procedures to be implemented in the database finalized and working correctly in their current implementation?
- Will all users have Access 2002, or are some using an older version of Access?
- Does the customer prefer a familiar, tried-and-true interface or the newest Access 2002 features?
- Are there any specific Access features the customer wants you to incorporate into the database?
If you're creating a complex database for a customer, be sure to refer to the section "Design Considerations for Large or Complex Databases."
You don't need to build the database with all the latest features of Access. On the other hand, it would be a mistake to omit a useful feature-for example, a tabbed form created using the tab control-just because the database users don't know enough about Access to request it. Talking with your customer about these issues beforehand will help you plan for a smoother development process.
tip - Be flexible in design
If users don't like the way you've implemented a feature and it's possible to change the feature to please them, you should try to do so. Things work out a lot better in the long run if you can design database features to work the way users want them to work, rather than spending a lot of time (and generating a lot of negativity) trying to teach users to use features designed your way.
Identifying How the Database Will Be Used
When you're designing a database, you need to consider how the database will be used and how (and where) its data should be stored. There are typically three types of databases: personal, corporate/networked, and Web-enabled.
note
These are not official Access database terms, but we'll use them occasionally in this book.
Personal Databases
A personal database generally stores its data in the same database as the interface objects, instead of placing the data tables in an external database. Personal databases are used to store information such as addresses, phone lists, CD collections, and other personal data. Although flat-file databases can be used for personal data, even a simple name and address database for personal use works better if it's set up as a relational database, with data separated into linked tables.
A personal database isn't necessarily a small or simple database-you might need a large and complex database to manage a personal interest or hobby such as genealogy or Civil War history. The main distinction between a personal and a corporate database (apart from the fact that a personal database is rarely networked) is that you have complete design control over a personal database, and you can spend as much time as you see fit on each database element, without the constraints of a corporate budget or the need to interface with a mainframe database.
Corporate/Networked Databases
A database designed for business use should usually be broken into a front-end database (containing the interface elements, such as forms and reports) and a back-end database (containing just the data tables). Separating the data from the front end makes it possible to update the database interface without disturbing existing data. It also enables you to place the back end on a server, with separate front ends on individual workstations, which can improve performance to some extent and allows for customized front ends for different users.
A front-end/back-end database isn't the same thing as a client-server database. In a true client-server database, the application needs to be divided into a client component, which contains interface objects, and a server component (such as Microsoft SQL Server), which stores data and performs data manipulation on a server (a central computer used for high-powered data processing and storage of massive amounts of data).
Web-Enabled Databases
An Access front end using data access pages can be connected to an Access or a SQL Server table located on a Web server. This scenario enables users to connect to the database via the Web, either on a corporate intranet or using the Internet. A Web-enabled database is suited for applications whose users are mobile-with Web access, users can log onto the database and view or modify data (with the proper permissions) from anywhere in the world.
Reviewing Data
It's easy to create Access tables and fields-very easy, if you use the Database Wizard or the Table Wizard. Once you get beyond the standard wizard-created tables and fields, however, you need to understand your data to determine how you'll divide the data into fields in the tables.
Before you create your tables, or any other database elements, you should analyze the data you'll be storing. For example, if you're creating a database to store information about your CD music collection, you need to decide whether you want to store only data about the CD number, title, and artist for each CD or whether you also want to include the liner notes, the individual performers, publisher, instruments, language, type of music, and so on. Additionally, you might want to store separate information about title, artist, and other information for each track on a multitrack CD.
If you're creating the database for a customer, you'll need to establish which data elements are important to the customer, to ensure that those elements will be represented by fields in the tables you create, and also to determine how the user wants to input and output the data.
As a rule, it's better to divide your information as finely as possible. This makes your database more flexible and leaves your options open for extracting data in many different ways. As a rule of thumb, if you want to look up a certain type of information later on, it needs to be stored in a separate field. However, even if you don't anticipate looking up specific information, it doesn't hurt to make the data atomic.
For example, suppose that you don't expect to need information about individual performers, so you enter only group names (such as Josh Barnhill's jug band) for the CDs in your CD database. Later, if you want to find all CDs that feature a certain performer (such as Molly Shapiro), you won't be able to retrieve that information for CDs on which that performer sang as a member of the group. But if you enter the names of individual performers as well as groups, you can retrieve information about either groups or performers.
Entering Name and Address Data
Many databases store name and address data, and it's especially important to enter this data in separate fields for each name or address component, rather than entering the complete name in a Name field and the complete address in an Address field. Countless databases have had to be redesigned later because names were entered into a single field instead of being split (at a minimum) into FirstName, MiddleName, and LastName fields (or better still, into Prefix, FirstName, MiddleName, LastName, and Suffix fields). Splitting a name into its components enables you to perform a variety of sorting tasks, including alphabetizing by last name in a report or printing name badges using first names only. And you won't have reports listing names such as Jones Jr., John, because the suffix was put in the same field as the last name.
The same principle applies to addresses: You should split addresses into (at least) Street Address, State/Province, Postal Code, and Country fields, for maximum usefulness. In some cases, you might want to split the street address into several fields, especially if you need to track the physical address and mailing address separately. You can always concatenate the separate address components into a single variable for exporting to Microsoft Word, for example, but it's much harder to extract the separate address components from a single Address field.
tip - Split names and addresses according to Microsoft Outlook
You can use Microsoft Outlook's system of dividing names and addresses into fields as a guide for your own data strategy. (Open the Check Name and Check Address dialog boxes for a contact in order to see these Outlook fields.) If you expect to transfer Access data to or from Outlook, be sure to use the same country names that Outlook does because otherwise you might find that your U.S. addresses are sorted into two or three country categories, depending on whether the country was entered as U.S.A., U.S., or United States of America.
Designing Tables
Once you have identified the type of database and reviewed the data, you should examine how the information will be stored in the database and determine how it should be split up into tables. For example, you should have one table for each significant category of information to be stored in the database, such as customers, orders, and shippers.
Designing for a New Database
When you're designing a database application from scratch, one approach to use is to first create unbound forms—forms that don't display data from tables-as a prototype of the application. Then get feedback from users, and modify the forms until they provide all the features users need to work with their data. Create tables with fields to hold all the information displayed on the forms, bind the prototype forms to the tables, and then create the other interface objects needed for modifying and displaying information.
This approach can save a lot of time later on, in contrast to designing tables first and then creating forms bound to the tables. Unbound forms as a design technique are especially suited for clients who don't know exactly what they want or need until they see it. Prototype forms let users (and the developer) think through how they need to interact with the data and are helpful in clarifying what tables are needed, what fields are needed in each table, and what relationships are needed between tables. On the other hand, clients who are more comfortable with abstract concepts are able to analyze their needs and give you a complete list of tables and fields without examining prototype forms.
Designing with Existing Data
When you're designing a database to manage existing data (for example, data stored in an old Access database, in another database format, in Excel worksheets, or in text files), it's generally advisable to first create (or import) the tables to store the data and normalize the tables (if needed), then create queries and forms to modify existing data and enter new data, and last create reports and data access pages for displaying and printing the data. This sequence will ensure that the tables have appropriately normalized relationships (discussed in the next section, "Normalizing and Refining") before you create other database objects referencing the tables.
Normalizing and Refining
Normalization is the process of designing a database so that there's no duplication of data in different tables, other than the linking fields that establish relationships. Although Access is a relational database, no constraints exist that prevent users from setting up Access tables with duplicate data—in effect, using Access as if it were a flat-file database. If you inherit such a database, although it will probably be a tiresome task, it's definitely worthwhile to separate the data into normalized, linked tables so that you won't have to worry about out-of-sync duplicated data in the future. If you're designing a database from scratch, it's easy to set it up correctly from the start.
As an example of the normalization process, let's say that you've been given a list of contacts, in the form of a Word document, in which each contact has one or more addresses, several phone numbers, and one or more e-mail addresses. You might be tempted to create a single table, tblContacts, with fields to hold all the data, including several sets of address fields (say, Home, Business, and Other), perhaps three sets of phone fields (Voice, Fax, Mobile), and a few sets of e-mail address fields. This table is a flat-file table—no doubt, you've seen such tables. In some older (or mainframe) databases, you don't have any other option, but in an Access database, this is poor design, because using fixed sets of fields to store multiple address, phone, and e-mail data for each client limits your options, in addition to wasting database space. If you have two sets of e-mail address fields, you won't be able to enter a third or fourth e-mail address for contacts that have them. If you have three sets of address fields, two sets will be empty for the majority of clients who have only one address.
Because each contact can have many addresses, many phone numbers, and many e-mail addresses, it's best to create separate tables to hold each type of data, linking them by a ContactID field. Using linked tables guarantees that you'll be able to enter all the information you need for each client, and you can retrieve the linked information as needed for forms and reports.
Troubleshooting - How can I export data from normalized tables to an Excel file or a text file?
It's usually a good idea to thoroughly normalize a database using one-to-many and many-to-many relationships to avoid duplicated data while still allowing you to include linked data in queries and SQL statements. But there are some exceptions. If you need to export Access data to a Word table, an Excel worksheet, or a comma-delimited text file for upload to a mainframe database (because these applications don't support relational data), you need to produce a non-normalized table for export-one that contains information from several tables and thus violates normalization by containing duplicate data.
It's rarely desirable to store your data in a non-normalized fashion, even if you need to export a non-normalized table. It's most efficient to store data in normalized tables and then, when you need to export data, create a table incorporating data from several linked tables, using a make-table query. The process of creating a non-normalized table from normalized tables is called denormalization, or flattening. Figure 3-5 shows a query used to combine data from a number of linked Northwind database tables. This query is in turn used as one of the data sources for the make-table query used to create a flattened data table that will be used to export data from the Northwind database to a Word table, in VBA code.
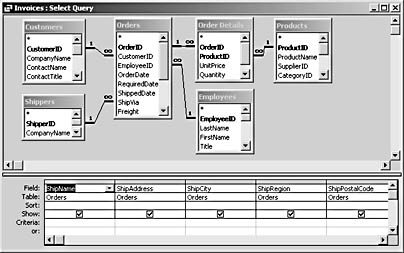
Figure 3-5. A query is used to produce a flattened table for export to Word.
Figure 3-6 shows the same query in Datasheet view—note the repeated data in several fields. The table created by the make-table query would also be suitable for export to an Excel worksheet or a text file for upload to a mainframe.
For more details on this technique, see Chapter 17, "Exporting Data from Access."
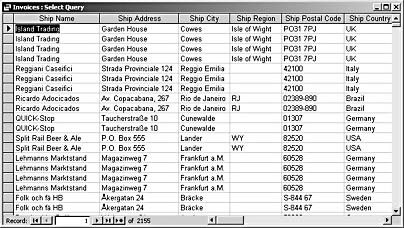
Figure 3-6. Flattened data generated by a query is used to produce a table for export.
EAN: 2147483647
Pages: 172