Section 5.3. Considering Indexes as Data Repositories
5.3. Considering Indexes as Data RepositoriesIndexes allow us to find quickly the addresses (references to some particular storage in persistent memory, typically file identifiers and offsets within the files) of the rows that contain a key we are looking for. Once we have an address, then it can be translated into a low-level, operating system reference which, if we are lucky, will direct us to the true memory address where the data is located. Alternatively, the index search will result in some input/output operation taking place before we have the data at our disposal in memory. As discussed previously in Chapter 3, when the value of a key we are looking for refers to a very large number of rows, it is often more efficient simply to scan the table from the beginning to the end and ignore the indexes. This is why, at least in a transactional database, it is useless to index columns with a low number of distinct values (i.e., a low cardinality) unless one value is highly selective and appears frequently in where clauses. Other indexes that we can dispose of are single-column indexes on columns that already participate in composite indexes as the leading column: there is no need whatsoever to index the same column twice in these circumstances. The very common tree-structured, or hierarchical, index can be efficiently searched even if we do not have the full key value, just as long as we have a sufficient number of leading bytes to ensure discrimination. The use of leading bytes rather than the full index key for querying an index introduces an interesting type of optimization. If there is an index on (c1, c2, c3), this index is usable even if we only specify the value of c1. Furthermore, if the key values are not compressed, then the index contains all the data held in the (c1, c2, c3) TRiplets that are present in the table. If we specify c1 to get the corresponding values of c2, or of c2 to find the corresponding c3, we find within the index itself all the data we need, without requiring further access to the actual table. For example, to take a very simple analogy, it's exactly as though you were looking for William Shakespeare's year of birth. Submitting the string William Shakespeare to any web search engine will return information such as you see in Figure 5-1. Figure 5-1. Searching the Web for "William Shakespeare" There is no need to visit any of these sites (which may be a pity): we have found our answer in the data returned from the search engine index itself. The fourth entry tells us that Shakespeare was born in 1564. When an index is sufficiently loaded with information, going to the place it points to becomes unnecessary. This very same reasoning is at the root of an often used optimization tactic. We can improve the speed of a frequently run query by stuffing into an index additional columns (one or more) which of themselves have no part to play in the actual search criteria, but which crucially hold the data we need to answer our query. Thus the data that we require can be retrieved entirely from the index, cutting out completely the need to access the original source data. Some products such as DB2 are clever enough to let us specify that a unique index includes some other columns and check uniqueness of only a part of the composite key. The same result can be achieved with Oracle, in a somewhat more indirect fashion, by using a non-unique index to enforce a uniqueness or primary key constraint. Conversely, there have been cases of batch programs suddenly taking much more time to run to completion than previously, following what appears to be the most insignificant modification to the query. This minor change was the addition of another column to the list of columns returned by a select statement. Unfortunately, prior to the modification, the entire query could be satisfied by reference to the data returned from an index. The addition of the new column forced the database to go back to the table, resulting in a hugely significant increase in processor activity. Let's look in more detail at the contrast between "index only" and "index plus table" retrieval performance. Figure 5-2 illustrates the performance impact of fetching one additional column absent from the index that is used to answer the query for three of the major database systems. The table used for the test was the same in all cases, having 12 columns populated with 250,000 rows. The primary key was defined as a three-column composite key, consisting of first an integer column with random values uniformly spread between 1 and 5,000, then a string of 8 to 10 characters, and then finally a datetime column. There is no other index on the table other than the unique index that implements the primary key. The reference query is fetching the second and third columns in the primary key on the basis of a random value of between 1 and 5,000 in the first column. The test measures the performance impact of fetching one more columnnumeric and therefore relatively smallthat doesn't belong to the index. The results in Figure 5-2 are normalized such that the case of fetching two columns that are found in the index is always pegged at 100%. The case of having to go to the table and fetch an additional column absent from the index is then expressed as some percentage less than 100%. Figure 5-2. Performance impact of fetching a third column that has to be retrieved from the table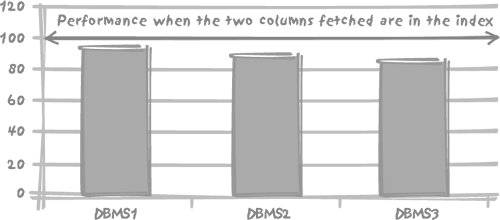 Figure 5-2 shows that the performance impact of having to go to the table as well as to the index isn't enormous (around 5 or 10%) but nevertheless it is noticeable, and it is much more so with some database products than with others. As always, the exact numbers may vary with circumstances, and the impact can be much more severe if the table access requires additional physical I/O operations, which isn't the case here. Pushing to the extreme the principle of storing as much data as possible in the indexes, some database management systems, such as Oracle, allow you to store all of a table's data into an index built on the primary key, thus getting rid of the table structure altogether. This approach saves storage and may save time. The table is the index, and is known as an index-organized table (I0T) as opposed to the regular heap structure. After the discussion in Chapter 3 about the cost penalty of index insertion, you might expect insertions into an index-organized table to be less costly than applying insertions to a table with no other index than the primary key enforcement index. In fact, in some circumstances the opposite is true, as you can see from Figure 5-3. It compares insertion rates for a regular table against those for an IOT. The tests used a total of four tables. Two table patterns with the same column definitions were created, once as a regular heap table, and once as an IOT. The first table pattern was a small table consisting of the primary key columns plus one additional column, and the second pattern a table consisting of the primary key columns plus nine other columns, all numeric. The (compound) primary key in every table was defined as a number column, a 10-character string, and a timestamp. For each case, two tests were performed. In the first test, the primary key was subjected to the insertion of randomly ordered primary key values. The second test involved the insertion into the leading primary key column of an increasing, ordered sequence of numbers. Where the table holds few columns other than the ones that define the primary key, it is indeed faster to insert into an IOT. However, if the table has even a moderate number of columns, all those columns that don't pertain to the primary key also have to be stored in the index structure (sometimes to an overflow area). Since the table is the index, much more information is stored there than would otherwise be the case. Chapter 3 has also shown that inserting into an index is intrinsically more costly than inserting into a regular table. The byte-shuffling cost associated with inserting more data into a more complicated structure can lead to a severe performance penalty, unless the rows are inserted in the same or near-the-same order as the primary key index. The penalty is even worse with long character strings. In many cases the additional cost of insertion outweighs the benefit of not having to go to the table when fetching data through the primary key index.[*]
Figure 5-3. Relative cost of inserting into an Oracle index-organized table compared to a regular (heap-organized) table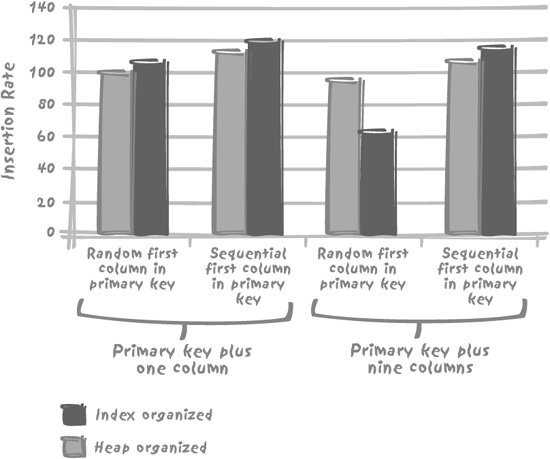 There are, however, some other potential benefits linked to the strong internal ordering of indexes, as you shall see next. Some queries can be answered by retrieving only the index data. |
EAN: 2147483647
Pages: 143