Section 3.3. Making Indexes Work
3.3. Making Indexes WorkTo justify the use of an index, it must provide benefit. Just as in our metaphor of the book, you may use an index if you simply require very particular information on one item of data. But if you want to review an entire subject area, you will turn not to the index, but to the table of contents of the book. There will always be times when the decision between using an index or a broader categorization is a difficult one. This is an area where the use of retrieval ratios makes its persuasive appearance. Such ratios have a hypnotic attraction to many IT and data practitioners because they are so neat, so easy, so very scientific! The applicability of an index has long been judged on the percentage of the total data retrieved by a query that uses a key value as only search criterion, and conventionally that percentage has often been set at 10% (the percentage of rows that match, on average, an index key defines the selectivity of the index; the lower the percentage, the more selective the index). You will often find this kind of rule in the literature. This ratio, and others like it, is based on old assumptions regarding such things as the relative performance of disk access and memory access. Even if we forget that these performance ratios, which have been around since at least the mid-1980s, were based on what is today outdated technology (ideal percentages are grossly simplistic views), far more factors need to be taken into account. When magical ratios such as our 10% ratio were designed, a 500,000-row table was considered a very big table; 10% of such a table usually meant a few tens of thousand rows. When you have tables with hundreds of millions or even billions of rows, the number of rows returned by using an index with a similar selectivity of about 10% may easily be greater than the number of rows in those mega-tables of yore against which the original ratios were estimated. Consider the part played by modern hard disk systems, equipped as they are with large cache storage. What the DBMS sees as "physical I/O" may well be memory access; moreover, since the kernel usually shifts different amounts of data into memory depending on the type of access (table or index), you may be in for a surprise when comparing the relative performance of retrievals with and without using an index. But these are not the only factors to consider. You also need to watch the number of operations, which can truly be performed in parallel. Take note of whether the rows associated with an index key value are likely to be physically close. For instance, when you have an index on the insertion date, barring any quirk such as the special storage options I describe in Chapter 5, any query on a range of insertion dates will probably find the corresponding rows grouped together by construction. Any block or page pointed to by the very first key in the range will probably contain as well the rows pointed to by the immediately following key values. Therefore, any chunk of table we return through use of the index will be rich in data of interest to our query, and any data block found through the index will be of considerable value to the query's performance. When the indexed rows associated with an index key are spread all over the table (for example, the references to an article in a table of orders), it is quite another matter. Even though the number of relevant rows is small as a proportion of the whole, because they are scattered all over the disk, the value of the index diminishes. This is illustrated by Figure 3-5: we can have two unique indexes that are strictly equivalent for fetching a single row, and yet one will perform significantly better than the other if we look for a range of values, a frequent occurrence when working with dates. Factors such as these blur the picture, and make it difficult to give a prescriptive statement on the use of indexes. Figure 3-5. When two highly selective indexes may perform differently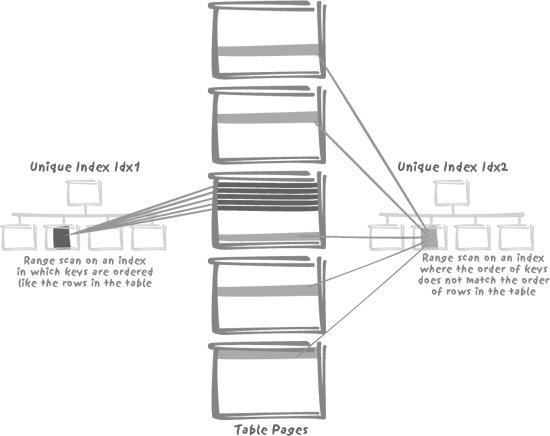 Rows ordered as index keys lead to a faster range scan. |
EAN: 2147483647
Pages: 143