Managing Data in Time
| Data exists in time. It is originally created when it is first saved as a file or entered as a record in a database. From then on, the data may be actively used by applications and updated, or it may be static and unchanged. Many data management technologies are designed to recover or regenerate data as it was at some previous time. In general, there are two primary reasons for managing data by its time variables:
Recreating a System State Through Point-in-Time Snapshot TechnologyBusiness continuity is a discipline with the goal of resuming normal operations following some type of disaster. For many businesses, the primary responsibility of business continuity is making sure that data and data processing equipment are available and operating correctly. This means complete data integrity and consistency must be maintained in all copies of data that may be used to re-create a complete system state in the future. Backup technology (see Chapter 13, "Network Backup: The Foundation of Storage Management") and remote copy technology (see Chapter 10, "Redundancy Over Distance with Remote Copy") are the primary applications that have been used to protect data from loss during a disaster. Backup allows companies to create copies of data on tape. Unfortunately, backups can take a long time to run, and maintaining consistency requires live backup operations using copy-on-write. This causes problems on production servers by overloading their CPU capacity. Remote copy provides a way to transfer data between physically separated disk storage subsystems. Unfortunately, maintaining consistency is challenging with active applications where data is constantly being updated and transferred. Even though the forwarding and receiving controllers in a remote copy system may accurately monitor the communications process, there may still be unaccounted for data stored in host system buffers at any particular time, creating potential data consistency errors. It is necessary to periodically ensure data consistency by emptying host buffers and synchronizing data at local and remote sites. The fundamental goal of business continuity is to be able to resume computing operations from a recent point in time where the data is known to be complete and consistent. A technology designed for that purpose is called point-in-time copy, also known as snapshot technology. Many companies use point-in-time snapshot products along with both their backup and remote copy applications in their business continuity practices. Three common approaches are used to create point-in-time copies of data, as discussed in the following sections:
Whole Volume SnapshotsA simple concept for creating a point-in-time copy of storage is to detach (stop the connection) from one of the redundant storage subsystem logical unit numbers (LUNs), thereby creating a snapshot of the entire volume at the time the storage was detached. Sometimes the process of detaching is referred to as "breaking the mirror." NOTE Remember that secondary storage can be physically located nearby or far away from primary storage, even though a "remote copy" application is being used to create the redundant data. To be precise, the point-in-time copy is usually created immediately after the host system has flushed its buffers and when the host system has temporarily stopped writing and updating data. The remote storage subsystem is then disconnected logically or physically from the host system or the subsystem running the remote copy application, preserving the state of data at that point in time. This is also called taking a snapshot of the data. The data snapshot that is created has a file system image complete with all on-disk file system components, including the superblock, metadata, and layout reference system. Other systems running the same file system software can connect to this storage, mount the file system, and commence operations. A whole volume snapshot scenario is illustrated in Figure 17-1, where three storage targets are being used to store data for a host system. Primary storage targets A and A' are mirrored by a host process and ready to accept I/Os from the host system. The snapshot target, which had been receiving writes from a host-based process has been disconnected from the host system and now has a connection established with the data management system. Figure 17-1. A Whole Volume Snapshot with a Data Management System Accessing Snapshot Target Storage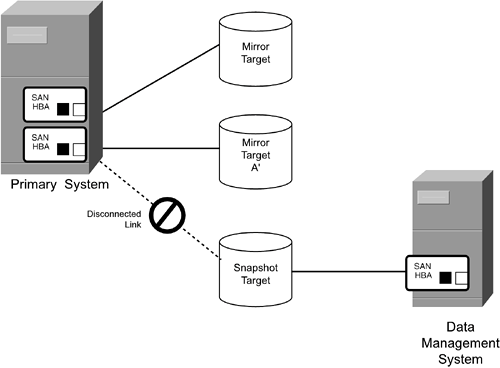 After the snapshot target is connected to the data management system and the file system in it has been mounted, the data management system is free to run any application against the data, including backup. The advantage of running backup on a snapshot target is that cold backups can be run at high speed without impacting the performance of primary storage and its applications. Another common use for point-in-time copies is for system testing. Many point-in-time systems were sold in 1998 and 1999 to help companies with their Y2K testing. After the point-in-time copy has been processed by the data management system, the snapshot storage target is disconnected from the data management system and reconnected to the host or the primary subsystem. A process called resilvering is performed to populate the reattached target with any data updates that occurred after the snapshot was created. NOTE The snapshot target in Figure 17-1 could be connected to either a host controller or a forwarding remote copy controller in a storage subsystem. It is even possible for the snapshot target to be located in the same subsystem cabinet as a primary storage target. Whatever. The important point is that the original connection for receiving data updates is re-established in order to resume normal operations. Volume Delta SnapshotsA point-in-time copy does not have to keep a separate, whole copy of a target. Another approach is based on the concept of keeping all blocks that are overwritten when data updates occur and then accessing those older blocks as they existed at a certain point in time. In other words, it provides a virtual view of the former volume at the time the snapshot operation was run. The former versions of changed data blocks are sometimes referred to as volume deltas. These volume deltas can be written either into special-purpose snapshot files or volumes. A virtual viewer interface, which is part of the point-in-time snapshot application provides access to point-in-time views of data by merging the views from the original volume and any volume deltas. The point-in-time snapshot application allows the administrator to select which previous version of data to view and then provides the selected version through the virtual viewer. Data management systems can use those virtual views to perform their operations. Figure 17-2 shows a volume delta snapshot scenario with older-version blocks being copied to a snapshot volume before being overwritten by an update to the primary volume. A viewer application merges the view of data in the primary volume with the view of data in the snapshot volume, overlaying the view of the most recent updates with views of older data versions. Figure 17-2. Older Data Is Copied to a Snapshot Volume, Where It Can Be Viewed as a Point-in-Time Snapshot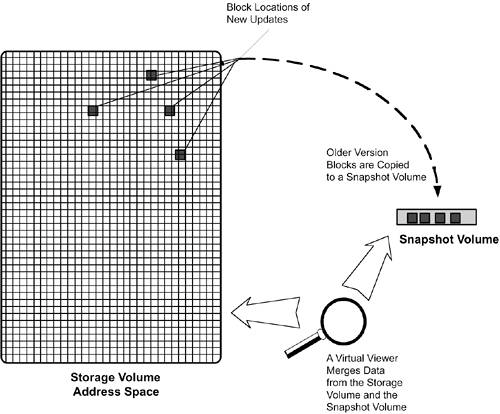 Creating this snapshot involves first flushing host buffers and then closing writes to the volume or file where old blocks are being written. This process is similar to copy-on-write used by backup applications, but this snapshot process copies the older-generation data to long-term snapshot storage instead of temporary storage. When the snapshot viewer is run, it merges the view of the primary storage volume with the view of blocks in snapshot volumes. Assuming that several such snapshot virtual views exist, multiple point-in-time views can be created by merging different combinations of volume deltas. Notice that all file system components, including the name space and layout reference system, are preserved this way. As long as all the data needed to operate the file system is stored within the volume and snapshot volumes, the volume delta method will be consistent. In fact, updates and writes to data files are made to free blocks, as opposed to overwriting existing blocks. It is possible that the old-version blocks copied to snapshot volumes were never used previously by the file system to store data. However, these "mystery blocks" are not a problem as long as the layout reference system maintains its integrity. Backup and other processes can be run against the virtual view of the volume. Depending on how the snapshot data structures are organized, and if the storage is located in a SAN, it might be possible for a second system to mount a virtual view of the data and process it with backup or or some other application, offloading data management tasks from the production system. One of the subtle tricks in the volume delta approach is handling updates made to any snapshot views of the volume. Updates from a virtual view obviously cannot be made to the actual volume, but they have to be created somewhere. The problem is that applications working with a virtual view may update a completely different set of blocks and a much larger group of blocks. There are a number of ways to do this, but all of them involve a fair amount of complexity and additional storage capacity. One way to prevent such problems is to limit volume delta views to read-only status. File System SnapshotsThe last method of creating point-in-time copies of data is similar to the volume delta approach, but it is done completely within the confines of a file system. In most standard file systems, updates to files are made to free storage blocks and the the layout reference system is updated to locate data in those newly allocated blocks. Afterwards, the file system returns the old blocks to the free block pool. File system snapshots are done by delaying the return of old blocks to the free block pool and maintaining older versions of the the layout reference system so these older versions of data can be accessed. The point-in-time copy is created when a snapshot process runs and identifies all data blocks that have been changed since the previous snapshot. For instance, file system metadata could contain information about which older versions of data belong together in a point-in-time group, allowing them to be viewed and accessed as a virtual, snapshot volume. Access to old files uses the exact same layout reference system that was used when the old file version was still current. Like the other point-in-time copy methods, backup operations can be run against the snapshot view of the file system. The main difference between the file system snapshot and the whole volume and delta volume methods described previously is the fact that file system snapshot data can be accessed using network file system protocols like NFS and does not rely on storage connectivity over a SAN. While SAN connectivity can be valuable for systems administrators, it has limited applicability for desktop users whose systems are not connected to a SAN. Practice Good Data Hygiene and Flush Data from Host BuffersA necessary process to ensure data consistency for point-in-time data is flushing host system buffers before making the point-in-time copy. Data held in file system write cache buffers must be on disk before the point-in-time process begins. The process of flushing host buffers is sometimes referred to as synchronizing the file system. Syncing the file system can be done several different ways, depending on the implementation details of the various products in use. It can be done manually at the system console, through scripts, and even through programmatic interfaces. One way to make sure cache buffers are flushed is to unmount the file system. Synchronization may not be necessary if direct I/O is being used, as it often is with database systems. Just the same, it is probably necessary to stop processing briefly when creating a snapshot with data stored under direct I/O to make sure the disconnection process does not occur in the middle of any pending I/Os. Continuous Volume SnapshotsAn interesting variation of point-in-time snapshot technology borrows an idea from mainframe computing, where I/O operations are time-stamped for precision operations and diagnostics. Continuous volume snapshot technology is based on the concept of logging all write I/Os and assigning a time value to each. This approach is similar to file system or database journaling, but the journal is at the storing (block) level and includes fine-granularity time designations. In essence this is an extremely precise, small-granularity application of delta redundancy technology. There are many possible ways this technology can be structurednone of them easy. That said, the capability provided could be very valuable to database administrators and systems administrators for other high-performance applications. By correlating time values with I/O operations and keeping accurate logs, it is possible to roll the software state forward and backward in microsecond intervals and find the most recent consistent data state to operate from. NOTE Continuous snapshot is definitely an application that would benefit from the use of direct I/O to bypass host buffers. If the goal is to recover from almost any point in time, why would you prevent that from happening by holding necessary write data in cache buffers? File ReplicationAnother technology used for business continuity purposes is file replication. File replication is a process where a software agent monitors file system activity and sends changed file data to another system, usually over a TCP/IP network. Replication can be scheduled to run at regular intervals or as a continuous operation. Replication transmissions can be done over LAN or WAN networks. To differentiate from remote copy, where data blocks are sent without any knowledge of their context, file replication processes identify the file in which a change has occurred. A data transfer process sends either the entire file or just the byte range changes for the file. If byte range changes are transmitted, the receiving replication system applies them to the file to re-create the new version. Replication does not communicate file system layout reference information; instead, the receiving system stores replicated files in its own file system. That means multiple sending systems can replicate data to a single receiving system that stores the data under a separate directory structure. There can be communication cost advantages to using file replication. Only files that are selected for replication are transmitted, compared to remote copy, where all writes are transmitted. This allows systems that support multiple applications to have their highest-priority data transmitted to another system. Replication can also be used with backup to reduce the load on production servers. For instance, a system could replicate files for a high-availability application and back them up on the receiving system instead of the primary production system. |
EAN: 2147483647
Pages: 184